 深度学习中的模型与激活函数:从sigmoid到ReLU
深度学习中的模型与激活函数:从sigmoid到ReLU





 本文详细介绍了深度学习模型的基础,包括神经网络的构成,如线性运算和非线性操作,以及几种常见的激活函数——sigmoid、tanh、ReLU及其变体leakyReLU。此外,还讨论了损失函数的重要角色,如MSE(均方误差)和交叉熵损失,在模型训练中的应用。这些概念是理解深度学习和大模型如chatGPT的关键组成部分。
本文详细介绍了深度学习模型的基础,包括神经网络的构成,如线性运算和非线性操作,以及几种常见的激活函数——sigmoid、tanh、ReLU及其变体leakyReLU。此外,还讨论了损失函数的重要角色,如MSE(均方误差)和交叉熵损失,在模型训练中的应用。这些概念是理解深度学习和大模型如chatGPT的关键组成部分。
chatGPT基于所谓的大模型,这里有两个关键词一个是“大”,一个是“模型”,我们先看什么叫“模型”。所谓模型其实就是深度学习中的神经网络,后者由很多个称之为“神经元”基本单元组成。神经元是一种基础计算单元,它执行两种操作,首先是一个矩阵M和输入向量X做乘法操作,其结果是一维向量WX,然后再跟另一个一维向量b做加法操作,所得结果还是一维向量WX + b,这些步骤统称为线性运算,最后这个一维向量会输入到一个函数f,最终输出结果是也是一个向量f(W*X + b),这个步骤叫非线性操作,其基本流程如下:
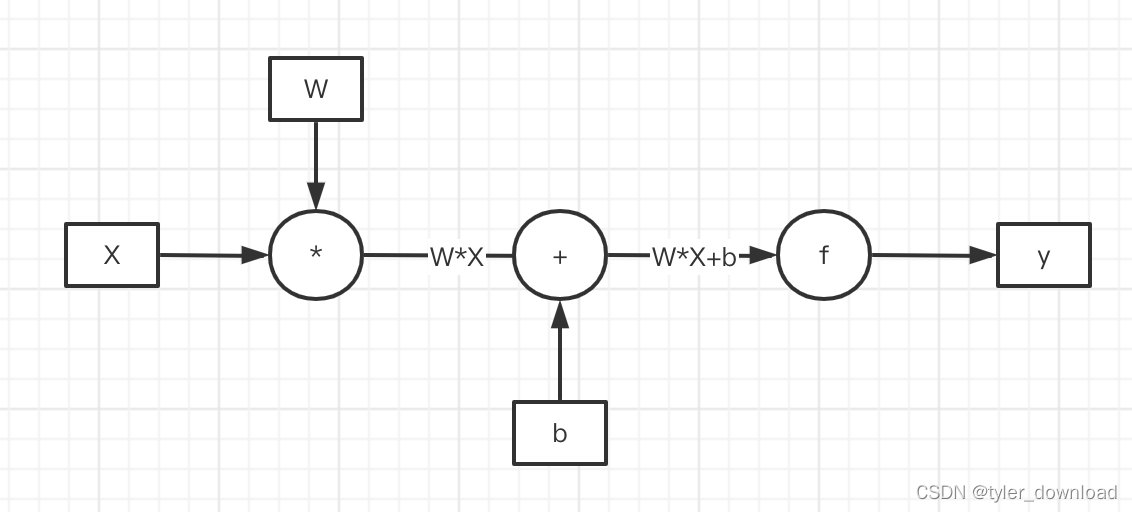
chatGPT的参数有1750亿个,也就是说它由1750亿个像上面那样的计算单元相互连接所形成的超大网络组成。上面流程中有一个关键步骤那就是函数f的执行,它也叫激活函数,其目的是把把前面线性运算的结果做某种非线性的跃迁,它主要有四种类型,第一种叫sigmoid,它的表达式为1 / (1 + e^(-x)),我们看看其函数图形:
import torch
import matplotlib.pyplot as plt
#创建x插值点[-5.0, -4.9, -4.8,...., 5.0]
x = torch.range(-5., 5., 0.1)
print(f"x:{
x}")
#执行激活函数
y = torch.sigmoid(x)
print(f"y:{
y}")
#根据插值绘图
plt.plot(x.numpy(), y.numpy())
上面代码执行后输出图形如下:
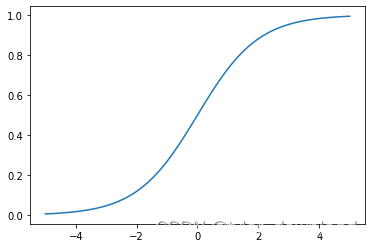
它的输出结果在0到1之间,如果我们想让网络预测某种概率,那么我们就可以在网络的末尾使用这个函数,它存在一个问题,那就是在x接近1.0或0的地方,如果对这些位置的x求导的话,切线的斜率就会非常接近0,这在训练网络时会产生一种叫"vanishing gradient"的问题。
第二种激活函数叫tanh(x), 它的表达式为(e^(x)- e ^ (-x)) / (e ^ (x) + e ^ (-x)),我们用下面代码画出其函数图形:
import torch
import matplotlib.pyplot as plt
x = torch.range(-5., 5., 0.1)
y = torch.tanh(x)
plt.plot(x.numpy( 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 204
204

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









