




P-tuning微调
简介
P-Tuning(Prompt Tuning)是一种基于预训练模型进行微调的方法,其基本思想是在预训练模型的输出层添加一个可学习的Prompt 可学习的软提示(Soft Prompts),以调整模型的输出。Prompt **可学习的软提示(Soft Prompts)**可以看作是一种特殊的上下文信息,通过将其添加到模型的输入中,可以引导模型产生期望的输出。在微调过程中,通过对Prompt进行训练,可以实现对预训练模型的微调。这种方法无需对模型的原始参数进行大规模修改,因此计算量相对较小,同时也能够有效避免过拟合。
P-Tuning就是在Prompt **可学习的软提示(Soft Prompts)**在处理,如图所示:
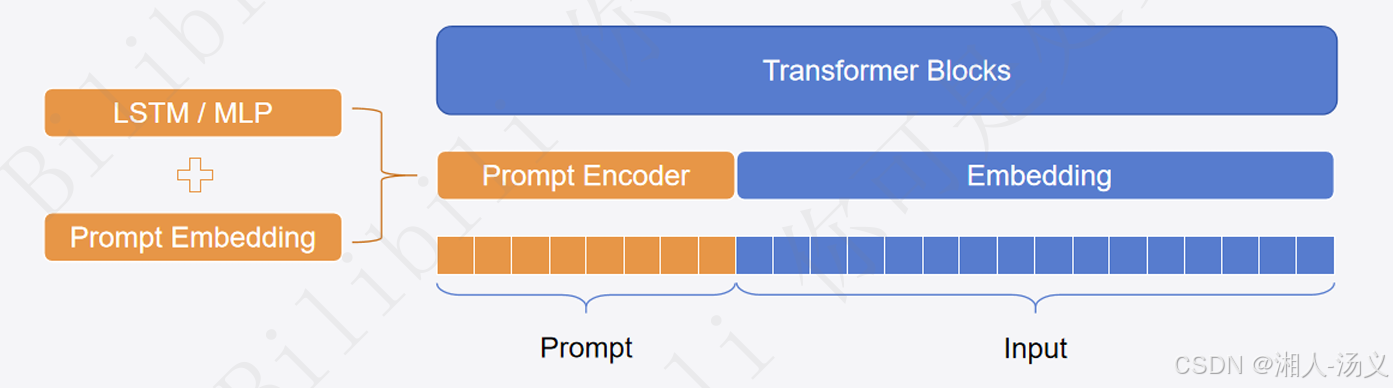
LSTM和MLP是PEFT的两种编码方式。
软提示(Soft Prompt)
- 软提示是一组可学习的连续嵌入向量,作为输入的一部分,插入到输入序列前或中间。
- 这些嵌入向量没有固定的语义,由模型在训练中学习其最优表示
代码实现
from datasets import Dataset
from transformers import AutoTokenizer, AutoModelForCausalLM, DataCollatorForSeq2Seq
from transformers import TrainingArguments, Trainer
from peft import PromptEncoderConfig, TaskType, get_peft_model, PromptEncoderReparameterizationType
from peft import PeftModel
# 分词器
tokenizer = AutoTokenizer.from_pretrained("langboat_bloom-1b4-zh")
# 函数内将instruction和response拆开分词的原因是:
# 为了便于mask掉不需要计算损失的labels, 即代码labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
def process_func(example):
MAX_LENGTH = 256
input_ids, attention_mask, labels = [], [], []
instruction = tokenizer(
"\n".join(["Human: " + example["instruction"], example["input"]]).strip() + "\n\nAssistant: ")
response = tokenizer(example["output"] + tokenizer.eos_token)
input_ids = instruction["input_ids"] + response["input_ids"]
attention_mask = instruction["attention_mask"] + response["attention_mask"]
labels = [-100] * len(instruction["input_ids"]) + response["input_ids"]
if len(input_ids) > MAX_LENGTH:
input_ids = input_ids[: 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 513
513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









