 Linux休眠唤醒解析
Linux休眠唤醒解析








 本文详细解析了Linux系统中的休眠唤醒机制,介绍了不同类型的休眠模式、宏定义实现、内存屏障使用及唤醒逻辑。并通过实例展示了如何确保进程正确地被唤醒。
本文详细解析了Linux系统中的休眠唤醒机制,介绍了不同类型的休眠模式、宏定义实现、内存屏障使用及唤醒逻辑。并通过实例展示了如何确保进程正确地被唤醒。
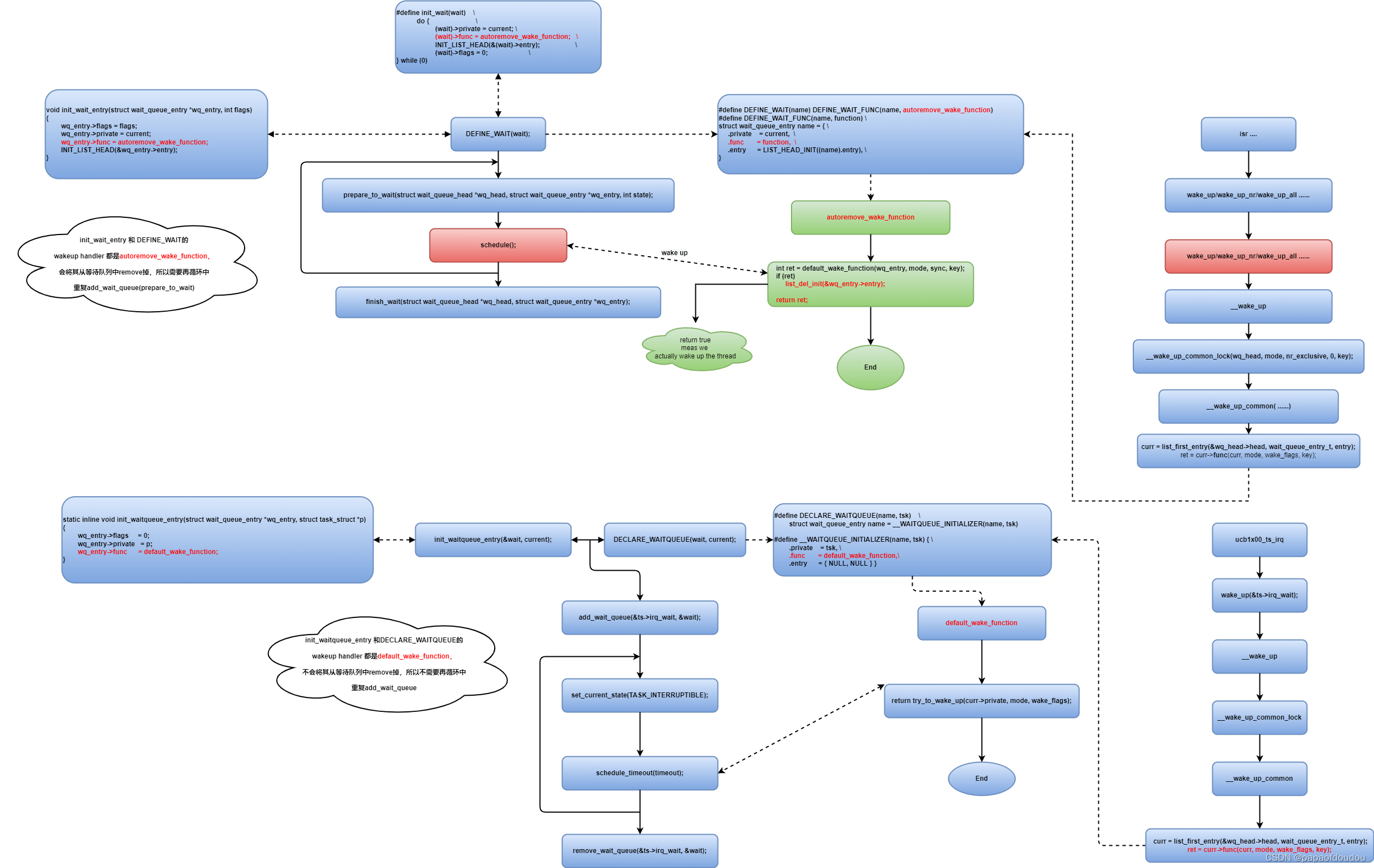
Linux系统中,很多的异步通知,尤其是中断和任务之间作同步的时候,有一种固定的休眠模式流程,如下图所示:
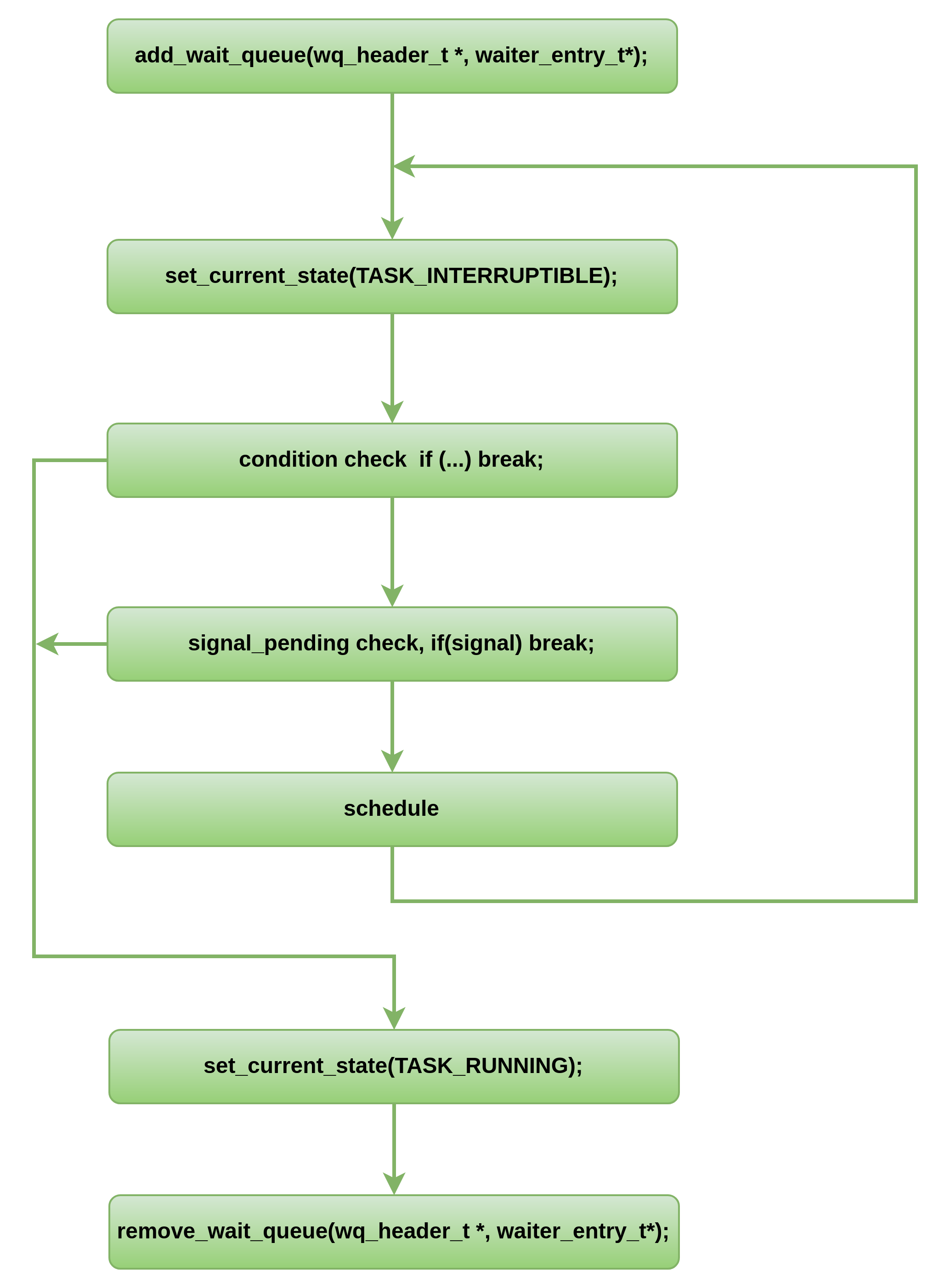
一种等价的流程
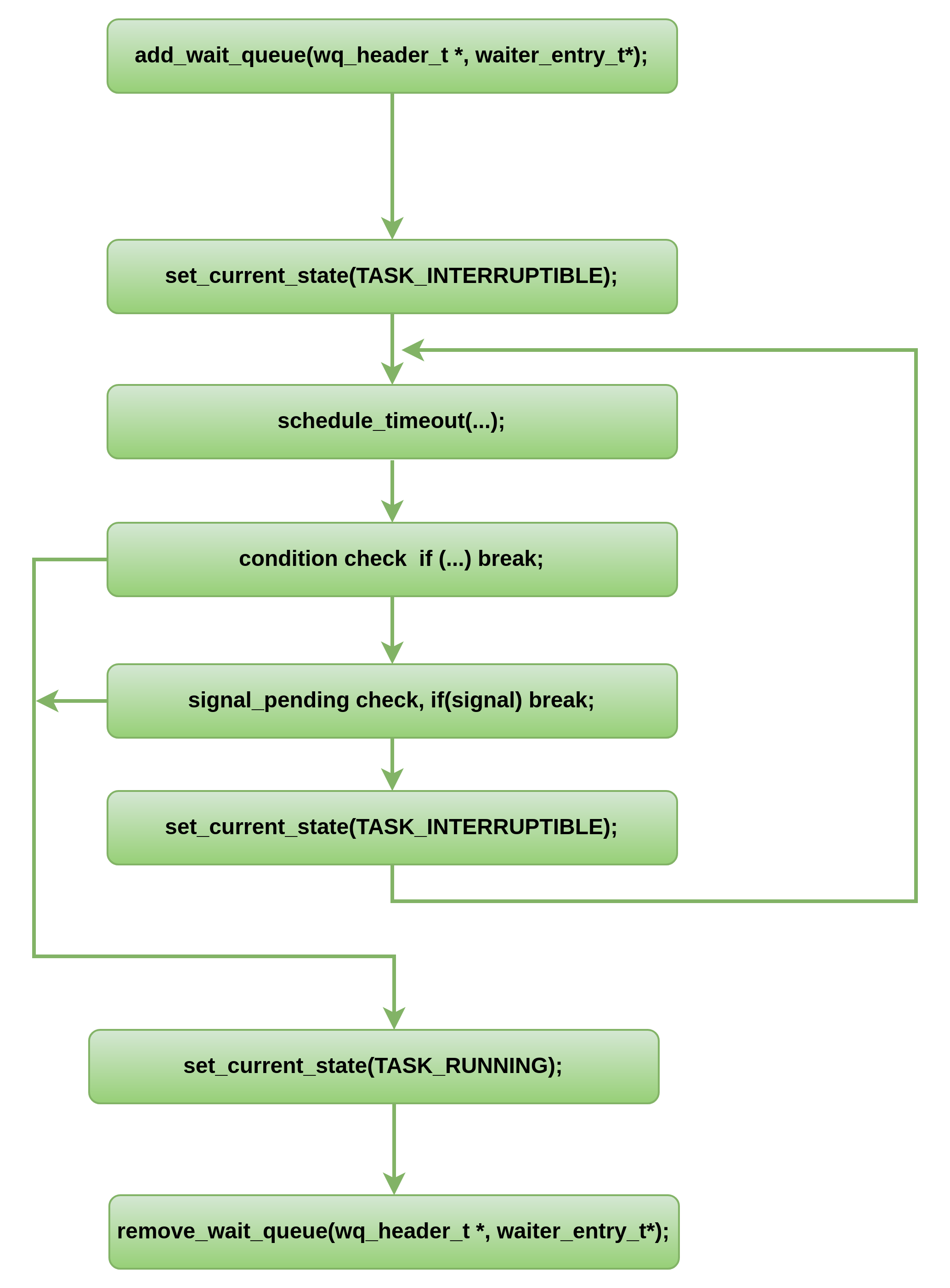
细节图
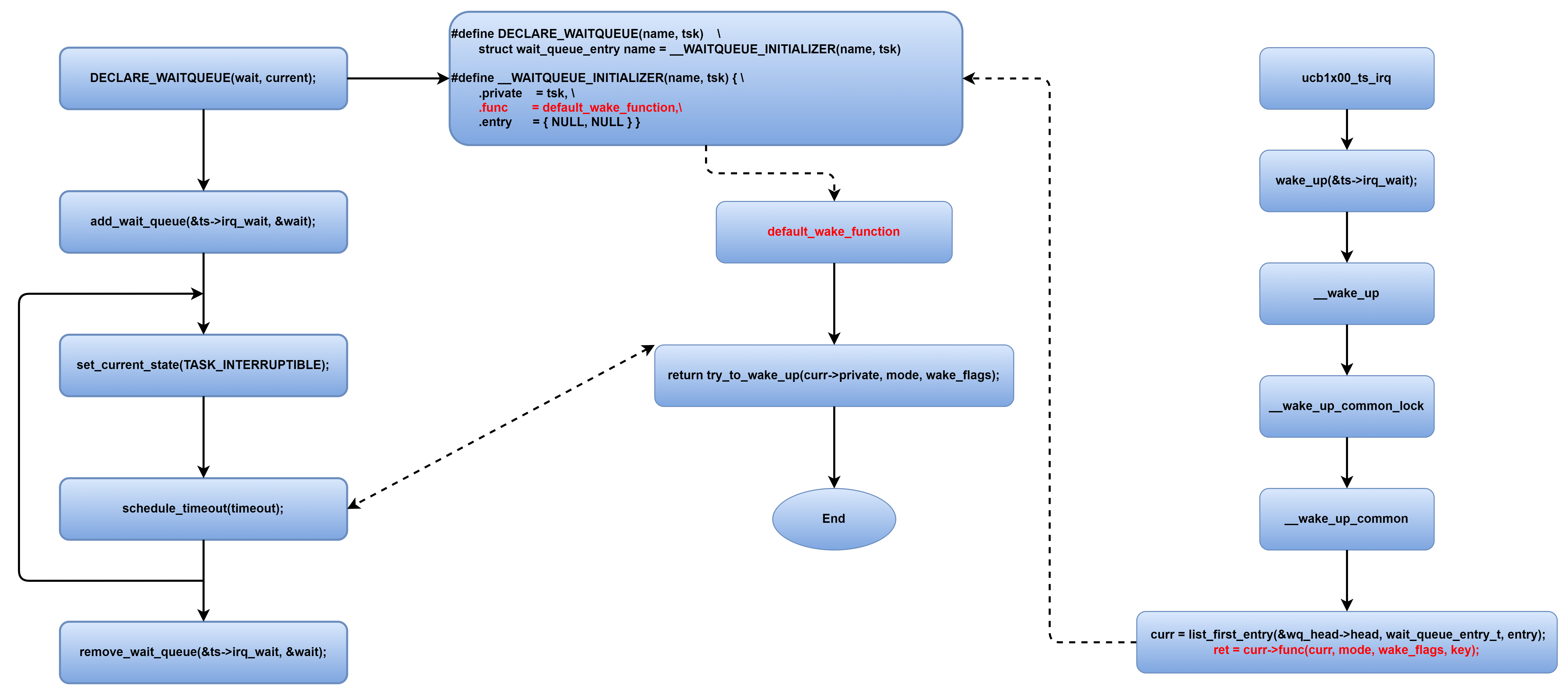
再介绍一种睡眠模式,下图代表的模式也经常在流程中遇到:
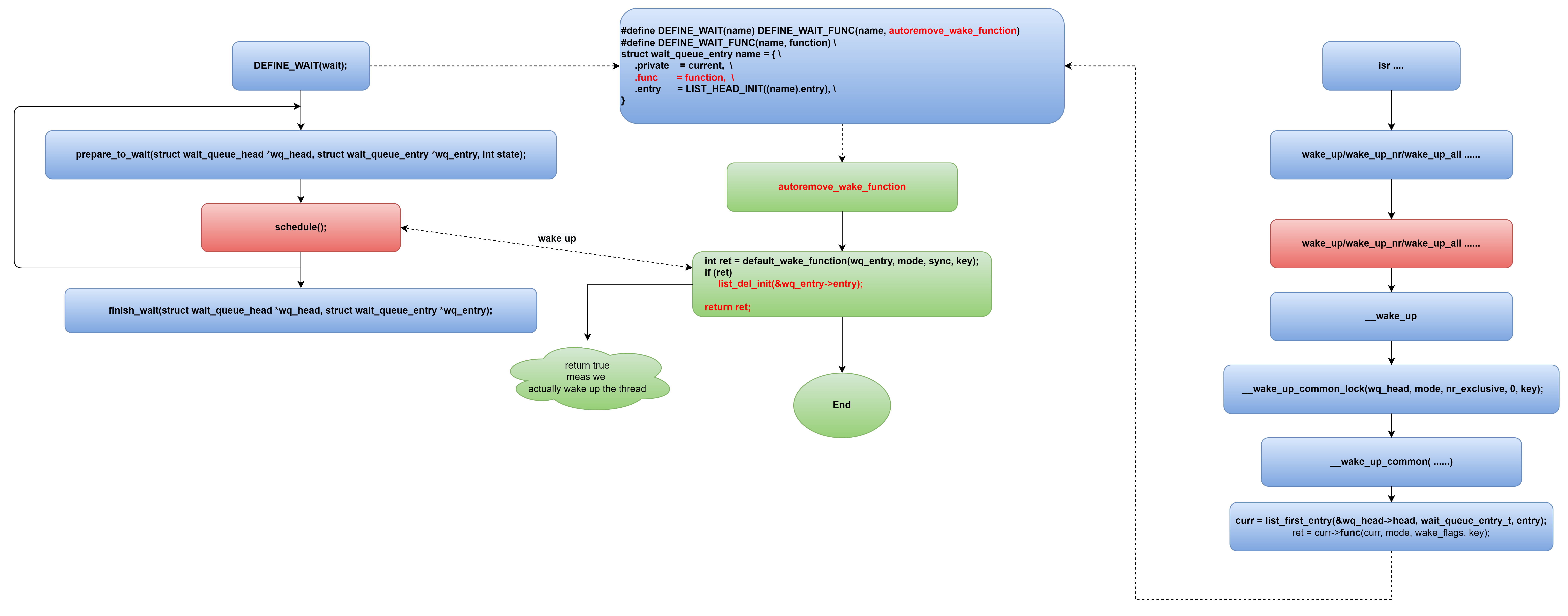
对比上面的两类流程,他们有什么差异呢?我们分析一下:
差异点1:第一种add wait queue 入队操作没有包含在循环里,而第二种操作,prepare to wait在循环体内重复执行。
差异点2:第一种的唤醒操作是default_wake_function,而第二种的唤醒操作是.autoremove_wake_function,autoremove_wake_function是对default_wake_function的瘦封装,只不过多了一个链表删除操作:

其实问题2回答了问题1,既然autoremove_wake_function多了一个删除操作,会将被唤醒的进程从等待队列中删除,那么下次循环时就必须要重新再加入等待队列,循环执行。并且分析代码可以指导,这个链表删除操作会将原链表中被删节点前后的节点连接起来,不破坏原链表结构的完整性,所以不需要重新初始化等待队列链表头。
为何prepare_to_wait和 schedule之间要加入唤醒条件检测?
其实这是一个barrier问题,如下的时许保证两点:
1.在检查点之前发生的事件,可以被有限检测到从而不必休眠。
2.在检查点之后发生的事件,通过task->state状态互锁,使schedule不会真正休眠,条件同样检测到。
schedule/schdule_timeout
schedule和schdule_timeout是通用的休眠让出CPU的两种方式,他们的区别是schdule_timeout支持中断唤醒源,而schedule出去的线程,只能由用户自行唤醒。
相同点是再调用schedule/schdule_timeout之前,都需要调用set_current_state设置线程状态。


否则,如果不提前设置线程状态,调用调度函数schedule并不会真正让出CPU,这样的话schedule会循环执行,由于schedule操作会拿取系统大锁,所以对系统的伤害比忙等更大。
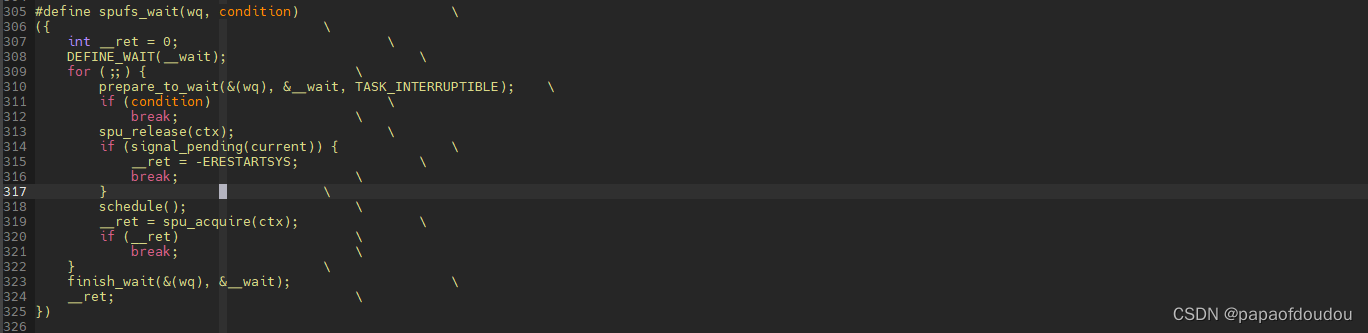
固定休眠模式的通用宏定义实现
既然有休眠流程有固定的模式,就可以通过宏定义将这些模式定义出来,通过一个宏接口调用去实现,内和中已经将这些固定的休眠模式定义为wait_event_xxx宏家族,调用这些宏,可以一步到位,实现上述的宏逻辑:
wait_event_interruptible_timeout/wait_event_hrtimeout/wait_event_idle/wait_event_freezable/wait_event ....
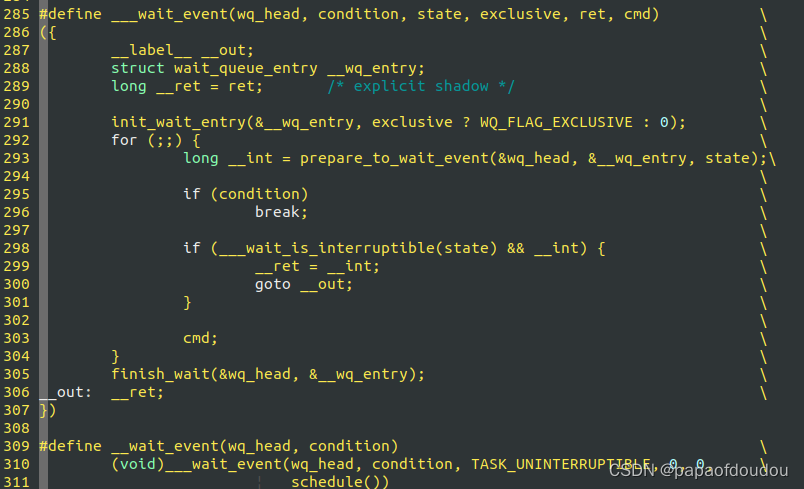
注意到condition条件检查被放在了设置任务state状态和进行实际休眠CMD中间,这是一种通用模式,和BARRIER的使用有关,在自己书写休眠过程时必须遵守。
循环体中加入fatal_signal_pending/signal_pending的作用
前面介绍的通用流程调用schedule/schedule_timeout出让处理器,这两个调用并不会修改task的状态,所以需要在调用这两个接口之前,首先调用set_task_state设置任务的休眠状态,休眠状态包括两种,分别是TASK_INTERRUPTIBLE和TASK_UNINTERRUPTIBLE,两种状态的区别是在处于休眠状态时,处于前者状态的任务是可以被唤醒的,而后者状态的任务无法被唤醒,所以当休眠状态为TASK_INTERRUPTIBLE时,需要在循环体中检测当前任务接受的信号情况,如果有接受到信号,则跳出休眠的循环体逻辑。
而对于在TASK_UNINTERRUPTIBLE状态下休眠的进程,由于其根本无法被信号唤醒,也就没有必要执行处理信号检测的逻辑。
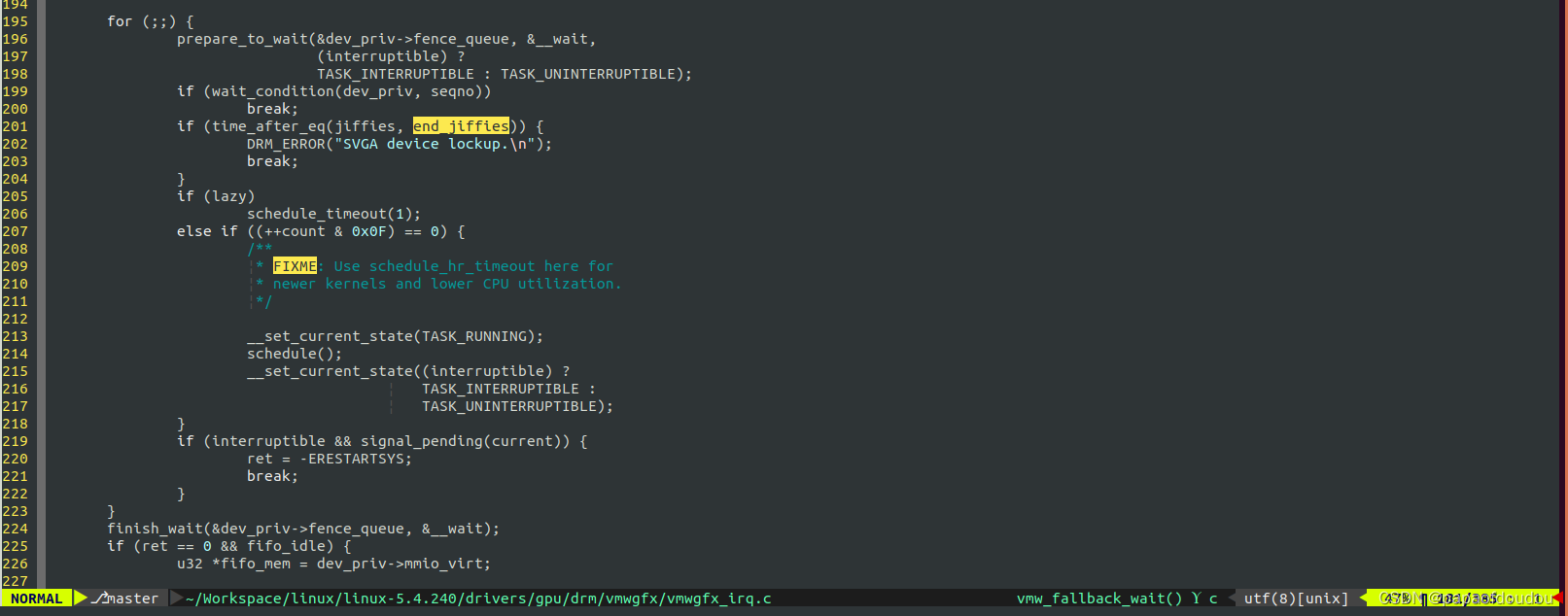
具体可以参考seqfile 219 test case,当休眠状态设置为TASK_INTERRUPTIBLE,可以被CTRL+C唤醒,否则,无法被CTRL+C唤醒。
另外,无论任务休眠在哪种状态,都可以通过针对状态的唤醒操作唤醒,毕竟,即便对于TASK_UNINTERRUPTIBLE状态的任务(比如在做磁盘IO的任务),也需要在IO结束后被唤醒。interrutible/uninterritble的区分,仅在于业务逻辑层面的不同。
比如,磁盘IO时 LOCK PAGE对应TASK_UNINTERRUPTIBLE休眠,而unlock_page则可以唤醒处于这种状态的任务。

系统调用pause也会使当前进程进入休眠,但是与时间无关,只有接收到信号之后才能被唤醒,所以常常用来协调若干进程的运行。它的实现如下,将进程设置为可中断的状态TASK_INTERRUPTIBLE,之后调度走,如果被唤醒,检查是否是由于信号唤醒的,如果是信号唤醒的进程,才会退出整个休眠循环。

在prepare_to_wait_event中,自带了signal检测:

所以常见的wait_event_interruptible_timeout函数集都可以处理signal函数。
内存屏障的使用模式
sleeper端需要在设置state和唤醒条件判断之间插入一个barrier 2.
waker端需要在设置判断条件和判断进程state中间插入一个barrier 5.
WQ_FLAG_EXCLUSIVE
休眠节点分为两种,分别是SHARED和EXCLUSIVE,在一次唤醒中,SHARED节点会被全部唤醒,而EXCLUSIVE节点只会被唤醒一个(根据传入的nr_exclusive参数决定,一般为1)。

当nr_exclusive被设置为0时,根据逻辑,!--nr_exclusive永远不会满足,所以函数逻辑是唤醒所有的在等待队列中的进程(just wake everything up). 而当nr_exclusive为一个正数时,将会唤醒所有的非WQ_FLAG_EXCLUSIVE任务一个nr_exclusive个WQ_FLAG_EXCLUSIVE类型的等待任务。
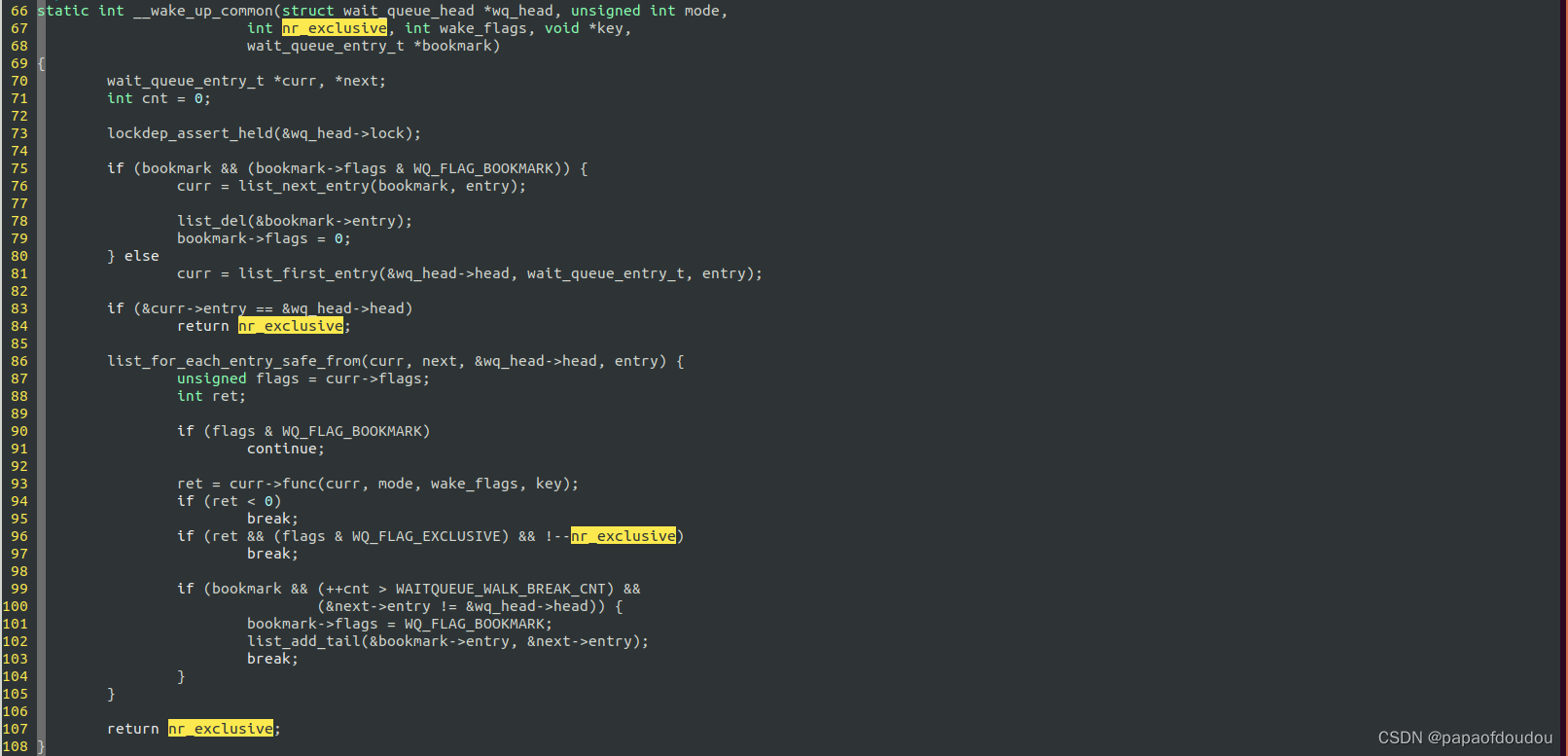
例如complete_all调用,为了唤醒所有等待complete的waiter,其nr_exclusive传入了0。

内核定义了多个唤醒接口,分别唤醒所有任务(wake_up_all,包含所有SHARED和EXCLUSIVE), 所有SHARED和1个EXCLUSIVE(wake_up),以及所有SHARED和用户设定数量的EXCLUSIVE任务(wake_up_nr))。

task_struct->on_rq/task_struct->on_cpu
on_cpu为1,则on_rq一定为1,道理很简单,正在占用CPU的进程,一定在就绪队列上,而on_rq为1,则并不一定on_cpu为1,因为还存在进程被抢占后,仍然在就绪队列,但是并不占用CPU这种情况。
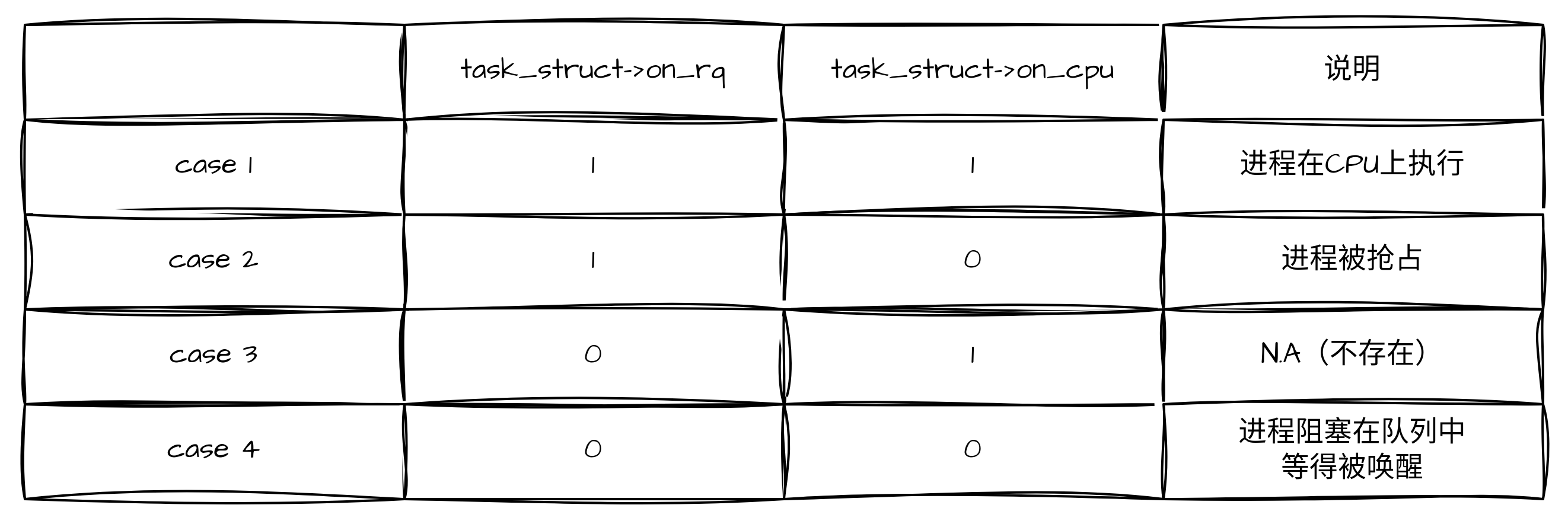
PS:case 3并非不存在,在任务主动修面,调用了__schedule->deactivate_task,设置了on_rq为0, 但是还没有调用context_switch->finish_task_switch->finish_task设置on_cpu为0时,也就是任务准备调度走的阶段。
设置on_cpu的时机
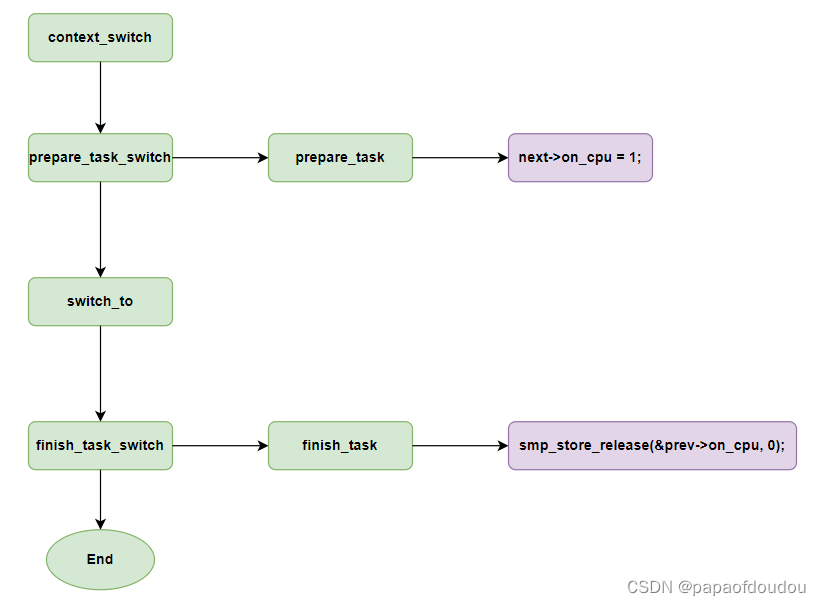
设置on_rq的阶段
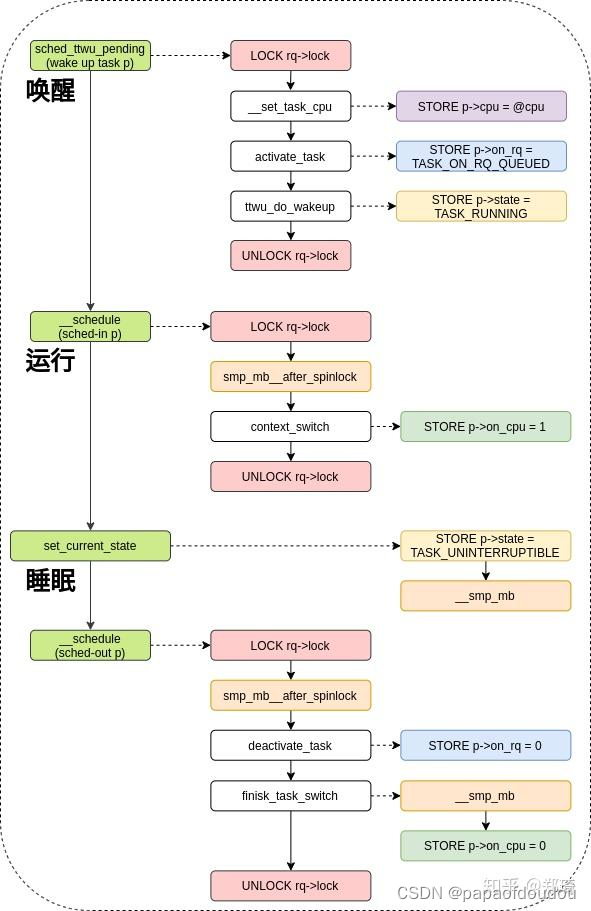
内核中的休眠唤醒逻辑汇总
一般来讲,在set_current_state和执行调度调用schedule中间应该应该加上判断condition的逻辑,否则有可能导致休眠后无法被唤醒。对于内核中有些地方没有加入判断condition的情况,可能是因为对于执行顺序有预期的顺序,或者加入了全局锁保证了执行的原子性。比如static ssize_t ipmi_read(struct file *file,。。。, static int wait_events(MGSLPC_INFO * info, int __user *mask_ptr)的实现。static int modem_input_wait(MGSLPC_INFO *info,int arg。。。)
内核中比较经典的休眠唤醒调用:
static int kcdrwd(void *foobar)
btmrvl_service_main_thread
static ssize_t ac_read (struct file *filp, char __user *buf, size_t count, loff_t *ptr)
hpet_read(struct file *file, char __user *buf, size_t count, loff_t * ppos)
static ssize_t ac_write(struct file *file, const char __user *buf, size_t count, loff_t * ppos)。
hpet_read(struct file *file, char __user *buf, size_t count, loff_t * ppos)
int ccp_cmd_queue_thread(void *data)
dma_fence_wait_any_timeout
kfd_wait_on_events/drm_syncobj_find_fence/i915_request_wait/wait_for_bit_change/radeon_fence_default_wait/hid_debug_events_read/vga_get/roccat_read/hidraw_read/hiddev_readcompletion机制
completion机制将condition变量和wait_queue_head_t对象封装起来:


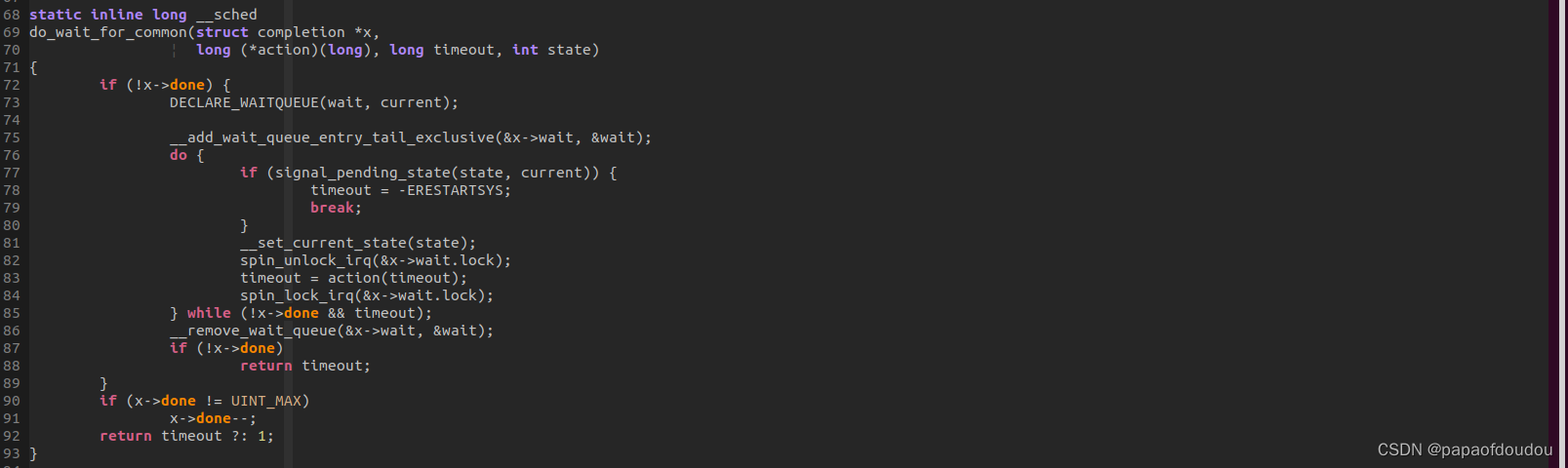
complete信号发送后,被唤醒进程会自动复位条件变量done,所以可以构成不断休眠唤醒的循环逻辑:
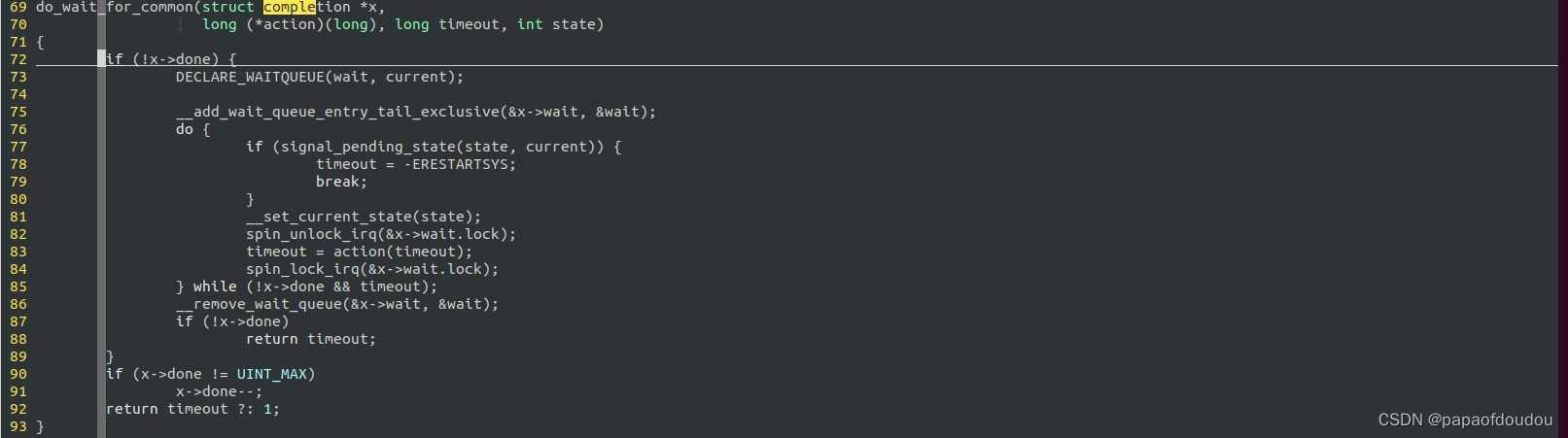


因为complete_all会将condition 设置为UINT_MAX,而针对这种情况的唤醒,被唤醒方并不会复位condtion done信号,所以被complete_all唤醒的任务,需要不断的调用reinit_completion复位dong condition.


前面固定休眠模式的通用宏定义实现一节中提到,条件变量的判断需要放在修改任务状态和进行实实际的调度调用中间,目的是在进行休眠调度除去前最后检查一次条件变量是否满足,否则,如果唤醒操作发生在休眠任务修改任务状态之前,因为任务还没有休眠,唤醒操作实际上不会改变任务的STATE状态,TTWU函数返回0,所以如果不在休眠前检查条件变量,休眠线程有可能错过这次唤醒进入休眠,从而一直休眠下去。
但是为何completion这里的休眠实现,在修改任务状态和进行实际调度的调用中间,没有加入判断条件变量DONE的逻辑呢?不怕错过唤醒信号么?

原因在于,do_wait_for_common的实现中,x->done条件信号的检查并不是没有加,而是加在了设置任务STATE调用__set_current_state的前面(无论第一次,还是后面的循环中,都是先判断x->done condition信号再修改任务状态的。
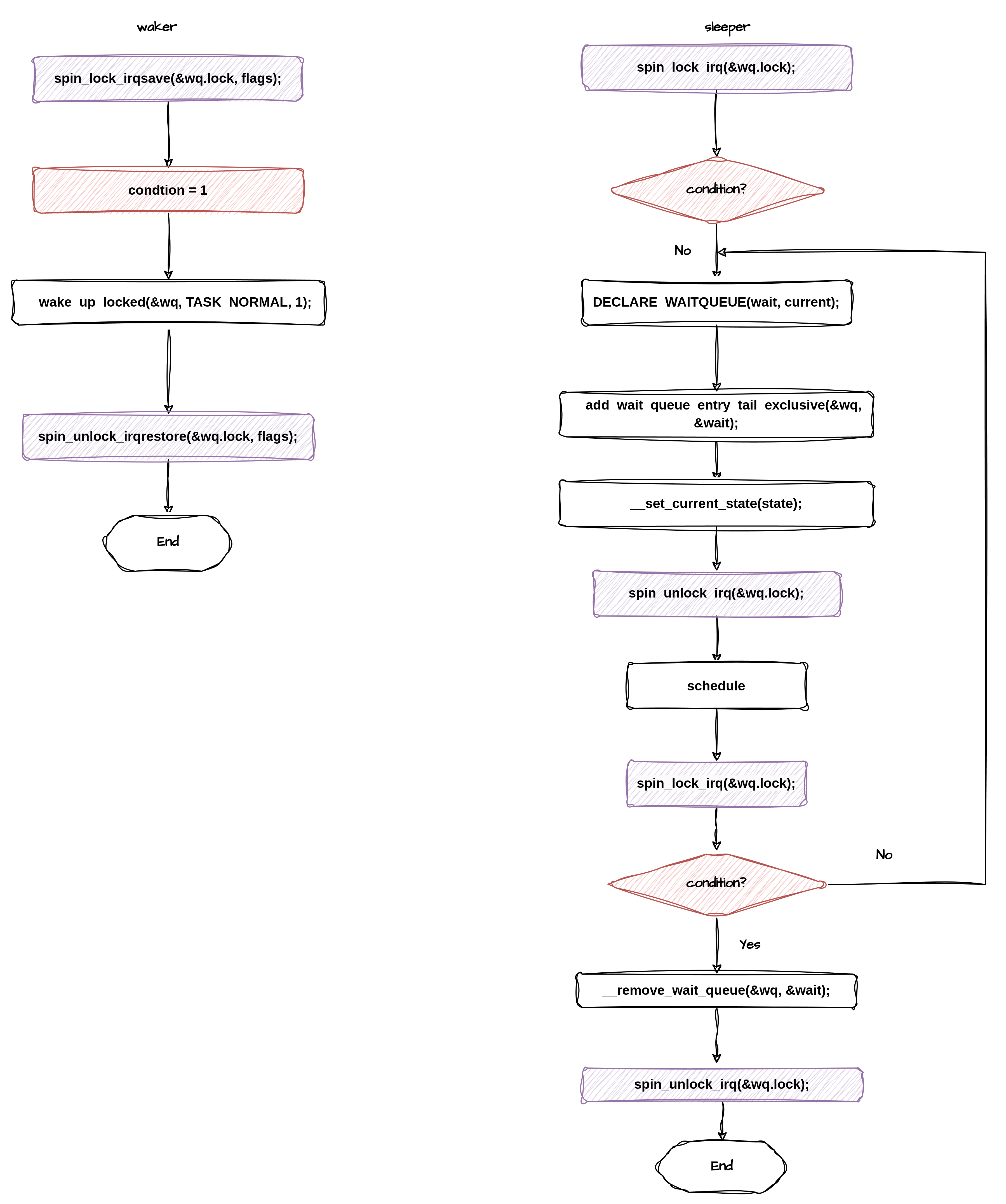
更为重要的是,这个 1.判断x->done状态和2.修改任务状态是WQ中的自旋锁x->wait.lock保护着的,更更更为重要的是,在唤醒操作complete中修改条件变量和唤醒操作,也是被同一把锁保护着的,所以,要么唤醒方的唤醒信号被检测到,要么睡眠方完成睡眠,之后唤醒方走完整的唤醒逻辑,不会出现唤醒房的唤醒信号被睡眠方同时进入临界区误判的情况。所以,COMPLTE的实现也是安全的。

如果先设置任务状态,在判断条件,则就不需要锁保护了:
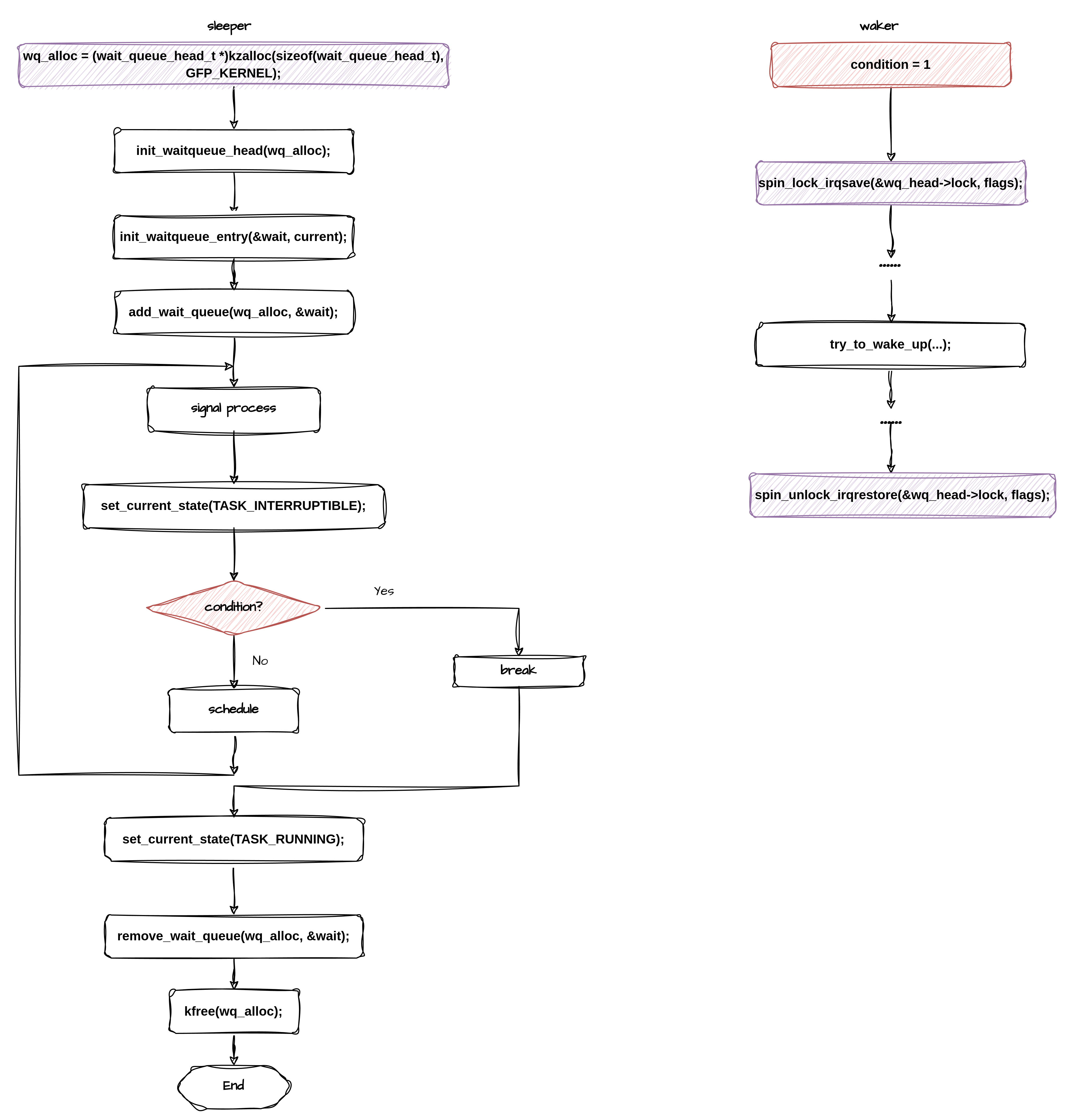
为何会这样呢?为何调换一下设置任务状态和条件判断的顺序,就不需要锁保护了呢?这里和barrier的使用逻辑有关:

上图中的1,2,3和4,5,6的逻辑,构成了如下的内存屏障模型:
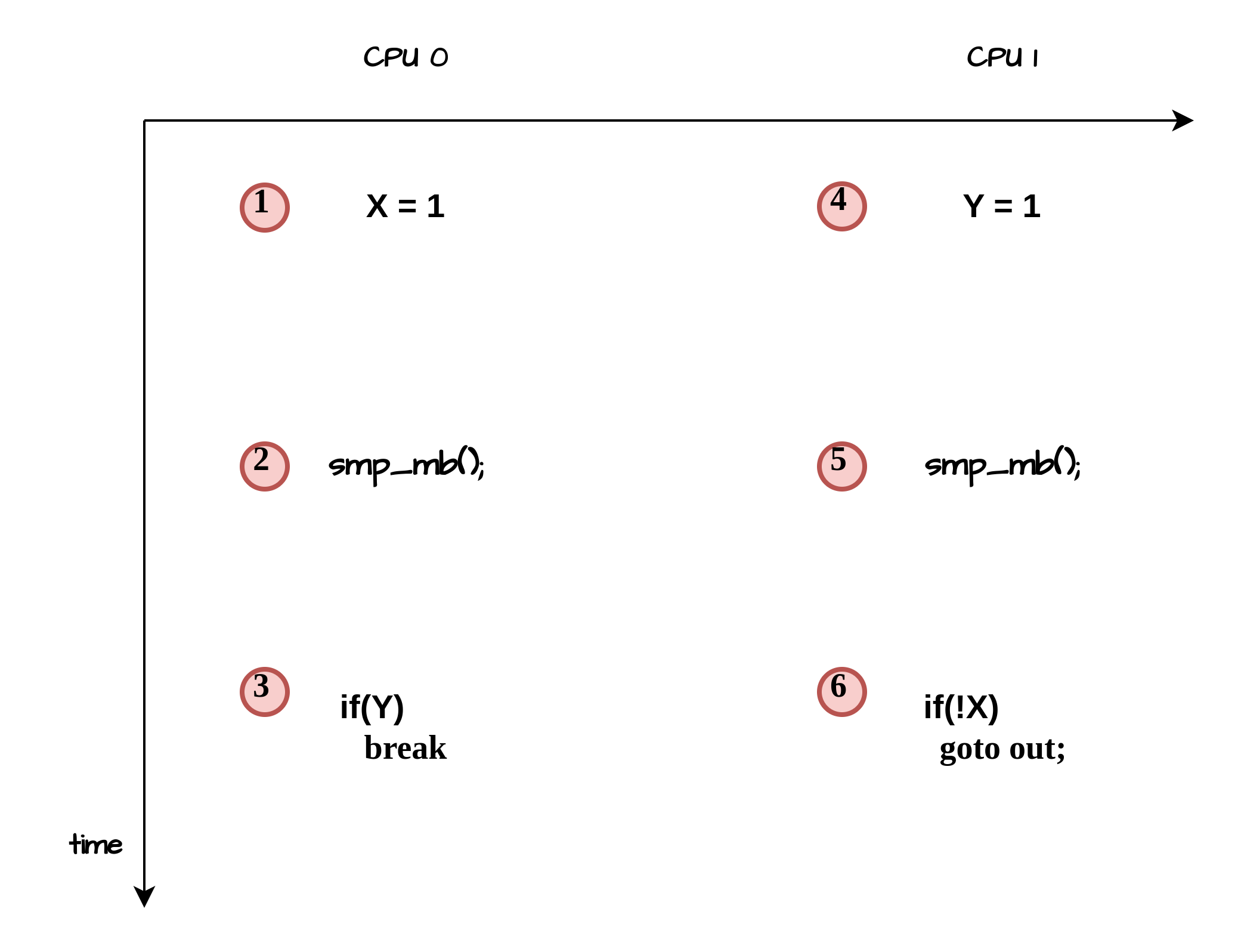
如同模型中,在3点和6点不可能同时检测到X=Y=0一样,内核的休眠唤醒中也不可能同时发现condition 和p->state&TASK_NORMAL 都为0。所以,要么休眠方发现condition为0, 那么唤醒方一定发现p->state&TASK_NORMAL不为0,这样waker能够执行一次真正的唤醒,要么唤醒方发现p->state&TASK_NORMAL为0,此时休眠方一定会发现condition 为1,从而不会执行真正的休眠被唤醒。
此外,还有一个CORNER CASE需要考虑,在condition被休眠方发现是0,唤醒方发现p->state&TASK_NORMAL不为0的情况下,休眠方从condition条件判断到真正执行schedule调度除去,这中间的一段流程是没有加任何锁保护的,非原子的,所以,如果这个时候,唤醒逻辑跑完了,休眠还会继续执行的话,岂不是又会错过这次唤醒?如下图所示,由于没有锁保护,执行的时序按照唤醒逻辑跑完了,schedule才继续跑:

这样会有问题吗?仍然不会,这个和调度器的实现有关,调度器中,唤醒方和休眠方都是被大的就绪队列自旋锁保护的,对任何一方来说,修改任务状态和操作就绪队列(移除和插入)是原子的,唤醒方如果在schedule之前执行完,则任务的state一定会被修改为RUNNING状态,而调度__schedule方如果发现任务状态为就绪RUNNING,是不会将任务从就绪队列中摘除的,而是当成一次抢占,任务实际上还是被唤醒的,等待下次调度。
或者调度进程先拿到就绪队列锁,执行休眠,这样唤醒方因为拿不到就绪队列锁而足色,直到休眠方完成休眠,释放就绪队列锁,此时唤醒方拿到锁会,会执行真正的唤醒调用,将目标任务状态设置为RUNNING,并任务加入就绪队列。
对于唤醒方在GAP中执行完毕的情况,唤醒方首先拿到就绪队列大自旋锁,此时休眠方由于拿不到就绪队列大锁而处于SPIN阻塞状态,并不能把自己从就绪队列摘除,而唤醒方发现目标任务仅仅是状态为非RUNNING,任务本身仍然在就绪队列,就简单的执行修改任务状态为RUNNING,然后释放就绪队列锁退出唤醒流程。此时阻塞的睡眠方可以拿到就绪队列锁,继续完成休眠流程,但是此时由于任务状态已经被修改为RUNNING,根据__schedule的实现,任务仅仅是执行一次类似于抢占调度的yield流程,任务可能被调度除去,也可能不被调度除去仍然被选择执行,无论那种情况,任务任务始终处于就绪队列,只要处于就绪队列,任务的唤醒就是成功的。所以可以看到,调度器原子的判断任务状态进而确定是否任务从就绪队列摘除,是这种通用休眠唤醒时序可以正常工作的保证。



被唤醒的进程行为
当调度发生时,被唤醒的进程不一定能能够被选上运行,因为RQ中有很多就绪的进程,LINUX内核并不区分在CPU上运行的任务和在就绪队列中等待任务的状态,统一都为RUNNING状态。至于到底多久之后才会被调度,这一点在目前的LINUX内核中是没有保证的,只能从统计角度去看。
参考
https://zhuanlan.zhihu.com/p/339378819
关于处理器静态&动态内存屏障的原理和应用_mov 0x2d93(%rip),%eax-优快云博客
Linux内核关于休眠唤醒部分的主体流程逻辑分析_linux唤醒流程-优快云博客
从磁盘读写看ttwu的典型唤醒流程_papaofdoudou的博客-优快云博客
Linux内核关于休眠唤醒部分的主体流程逻辑分析_papaofdoudou的博客-优快云博客_linux 内核休眠



















 1354
1354

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











