






 本文详细解析Darknet框架,包括推理前处理、YOLO层概率计算、网络结构与层解析。探讨了图像归一化、NMS去重、YOLOV3层数计算,以及部署目标等内容,有助于理解Darknet的内部运作机制。
本文详细解析Darknet框架,包括推理前处理、YOLO层概率计算、网络结构与层解析。探讨了图像归一化、NMS去重、YOLOV3层数计算,以及部署目标等内容,有助于理解Darknet的内部运作机制。
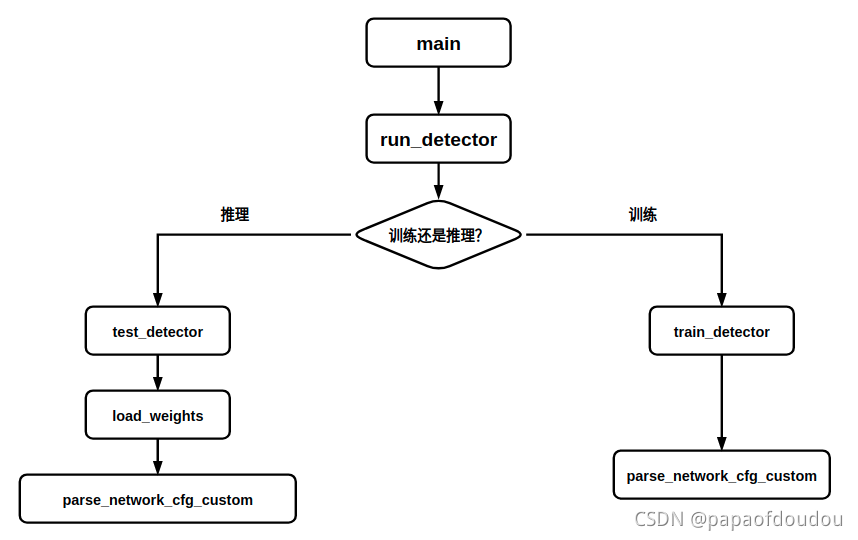
1.test_detector的调用路径:

这里重点介绍load_alphabet函数:
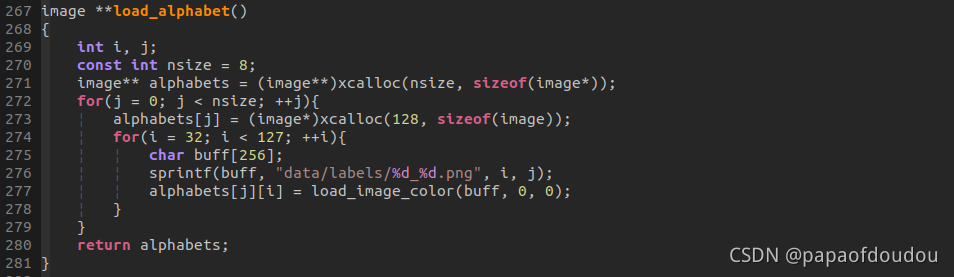
程序退出时,会清理这些图片分配的资源:

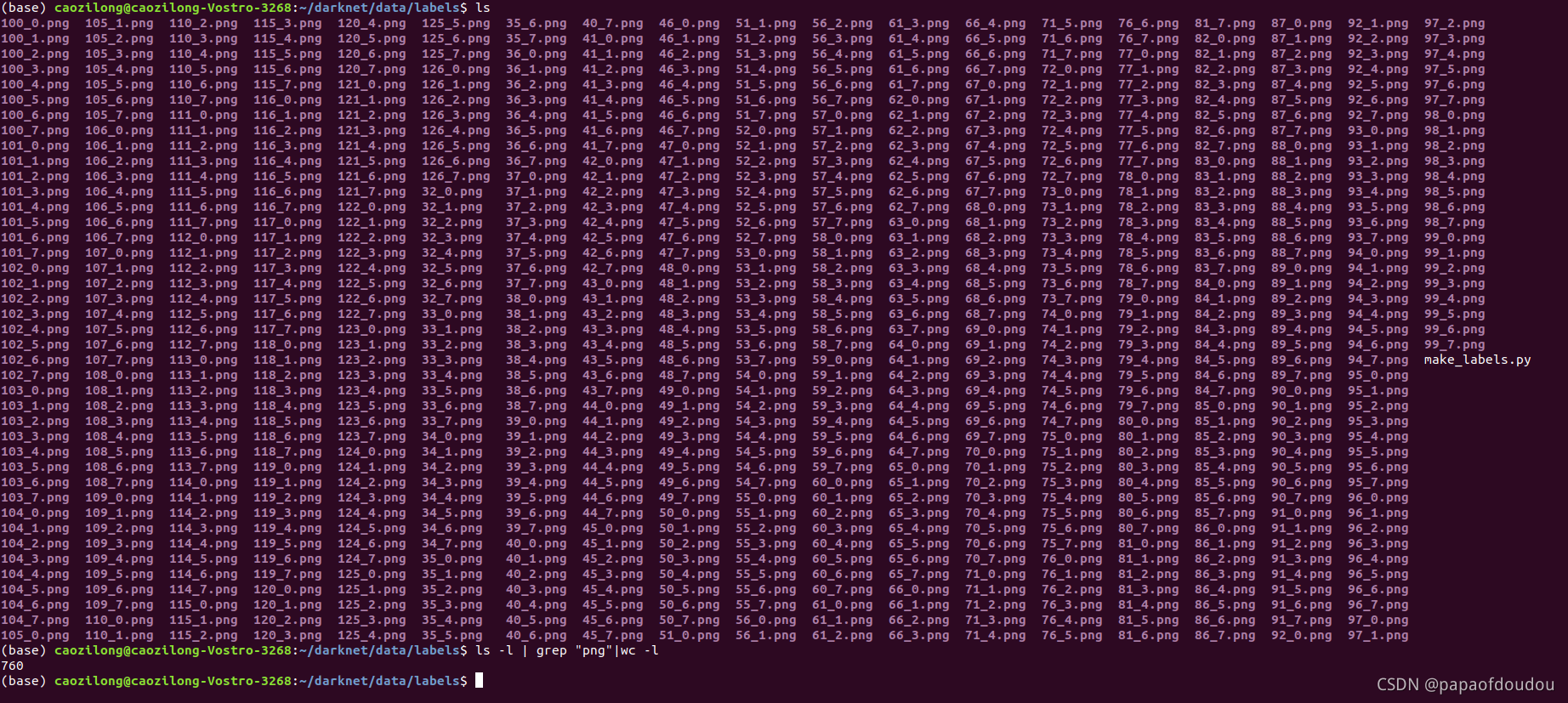
根据代码,这里是从data/labels/目录装载png图片,图片有8*95=760
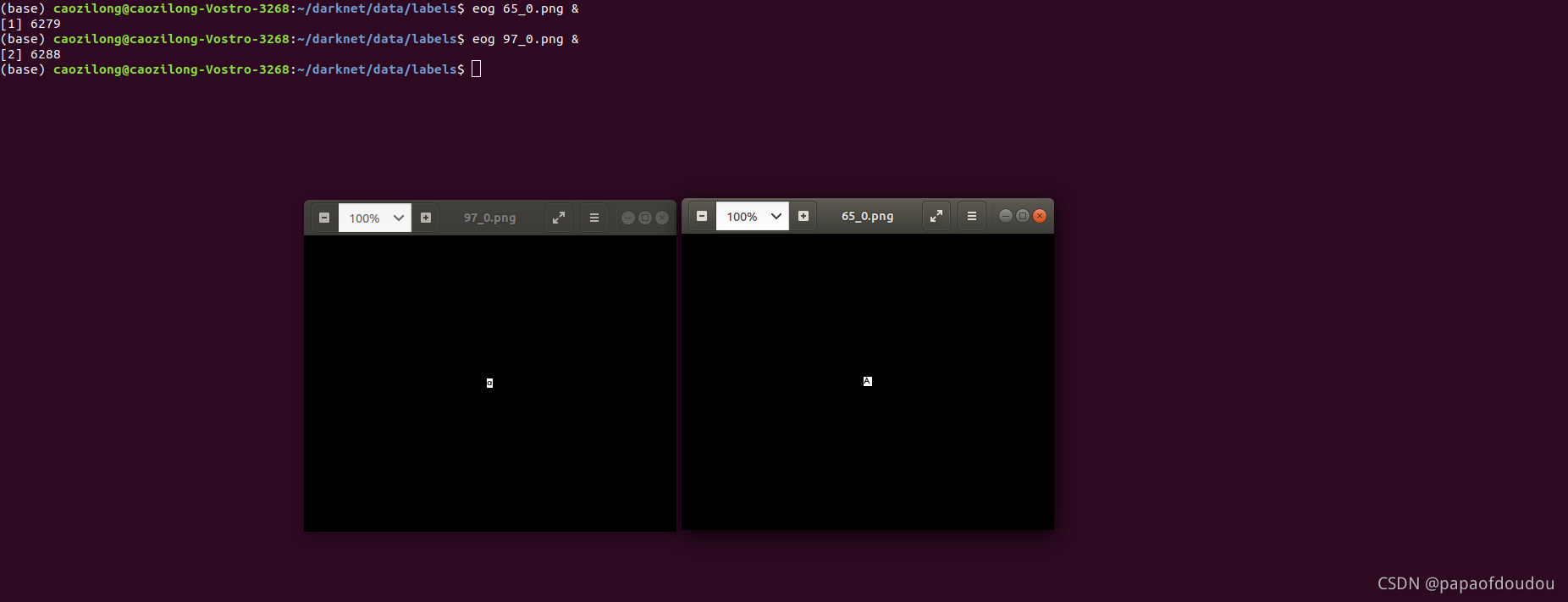
这些图片都是ASCII码,比如我们打开编号为65和97的PNG图片,看以下内容,分别是A和a.
怀疑最后绘框上面的Label字母就是来源于这里,这样就不依赖于系统字库了,我们确认一下,用反证法。
 如果我们将所有b的图片替换成a的图片,那么bicycle应该能变成aicycle的,我们测试一下:
如果我们将所有b的图片替换成a的图片,那么bicycle应该能变成aicycle的,我们测试一下:

我们重新运行推理测试,发现果然如此,b变成了a.

所以,labels/下有ASCII码32-127的8种尺寸的图片,是显示标签用的。
澄清一个问题,继续下一个问题
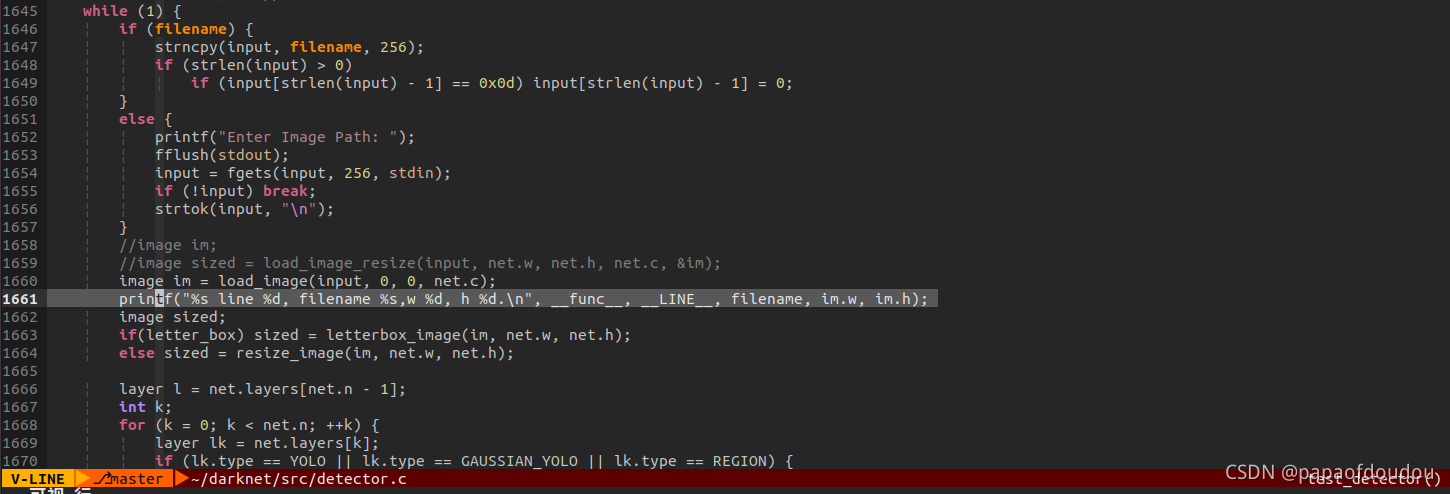
运行后:
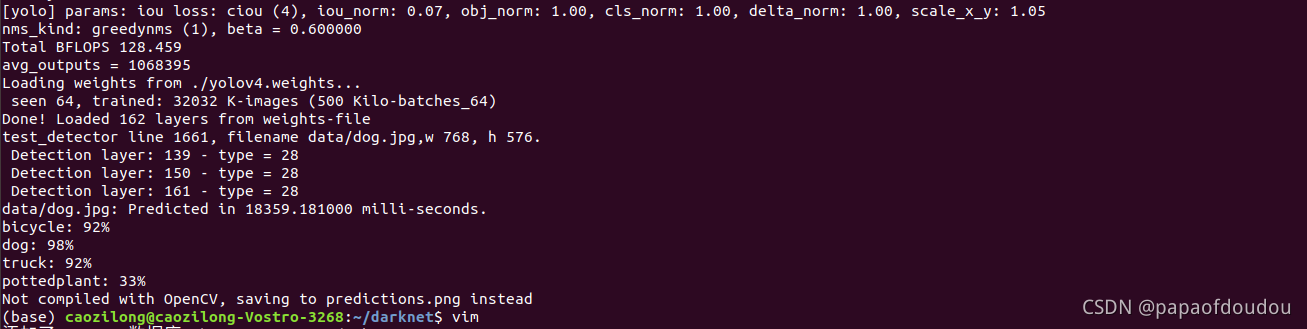
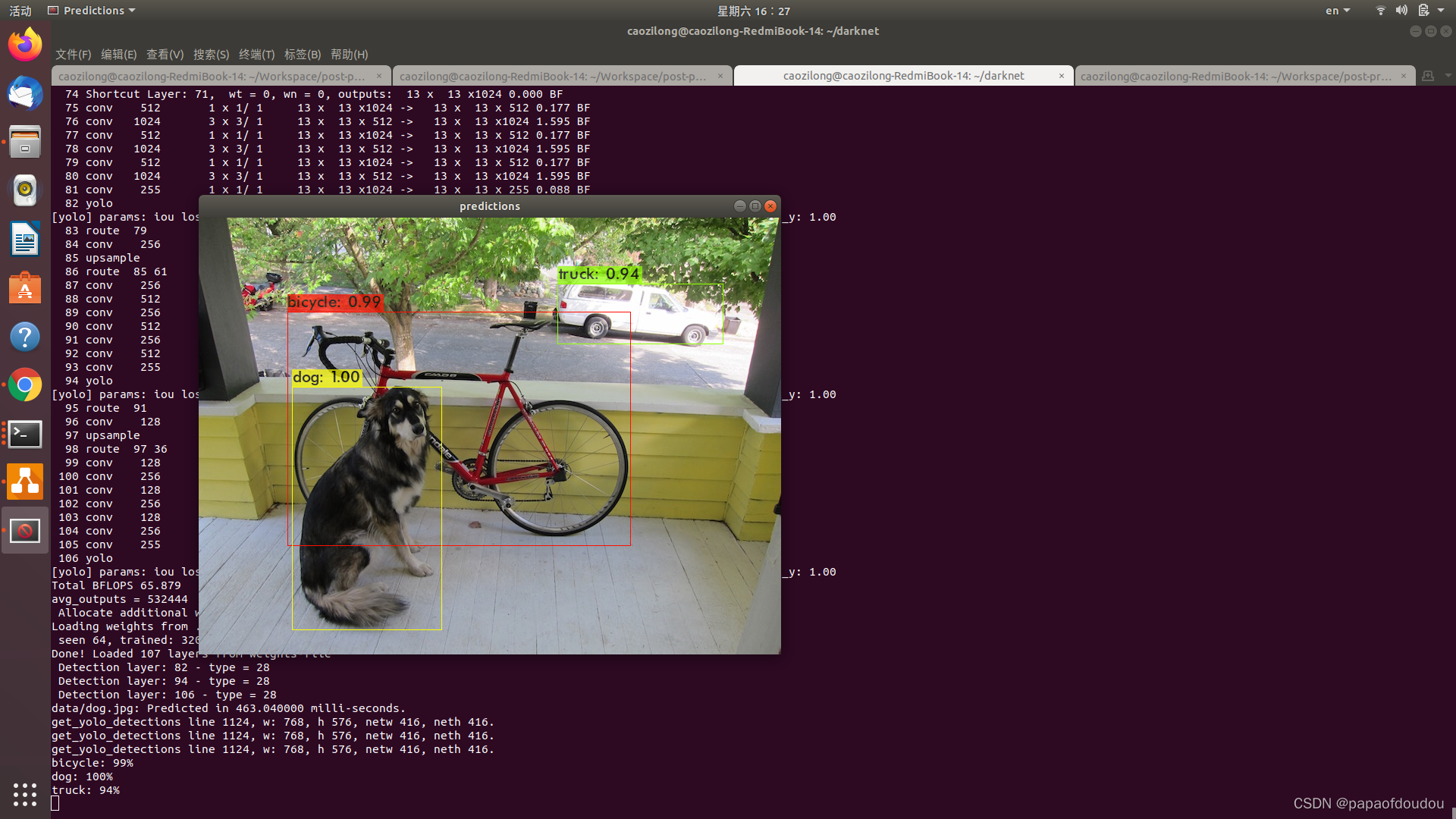
dog.jpg,宽高分别为768,576,这是原图的尺寸。
但是我们的网络描述文件,网络的输入应该是416*416的,该如何处理呢?
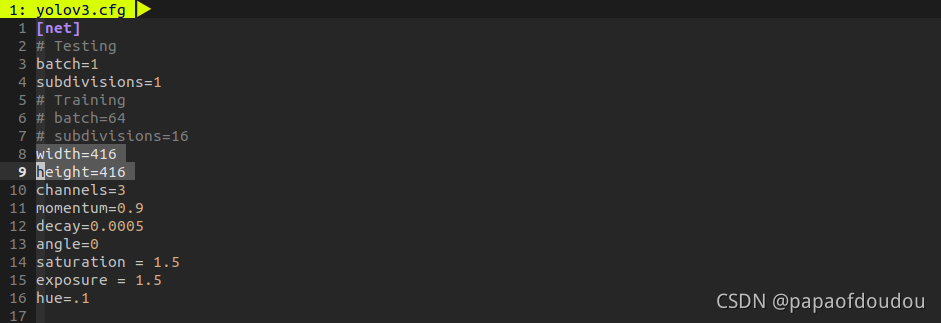
打印几个关键变量: 

喂给网络的JPG图像,首先要经过resize_image操作,转换为网络吃的416*416大小,load_image调用栈中会调用STBI库,库里面还会进行JPG-RGB的转换。



网络推理用的图像分辨率是416*416,但是输入原图和输出框却是在768*576大小,那么框和坐标是如何转化的呢?
./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights data/dog.jpg -i 0 -thresh 0.25s -out result.json
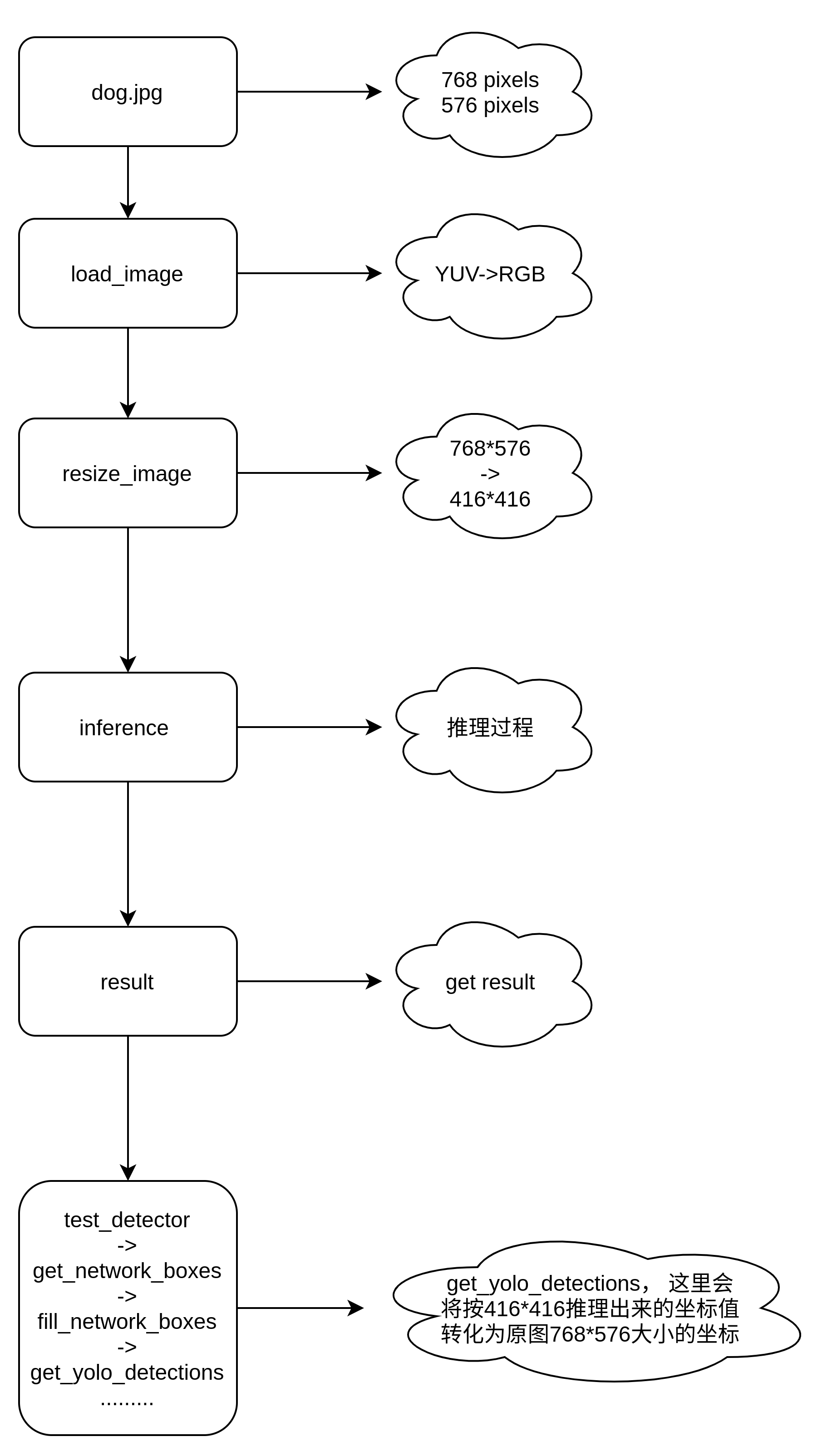
具体调用发生在下图中的correct_yolo_boxes函数。
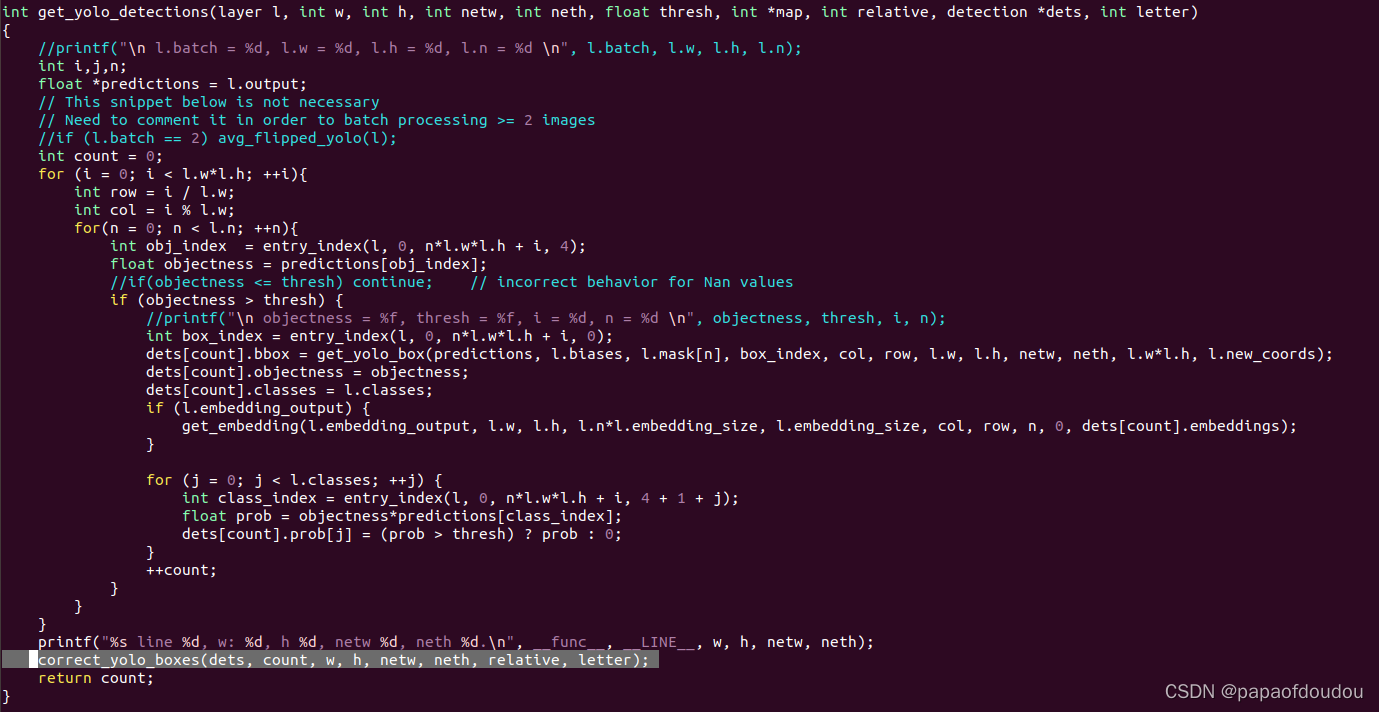
加入图中的打印LOG,我们看一下调试输出:
 数据处理流水线:
数据处理流水线:


这里的224*224写错了,YOLOV3网络不支持这种尺寸的输入,而应该是320*320。
推理前处理
前处理后,原图被转换为sized对象中存储的数据类型,我们打引它的维度信息和数据:
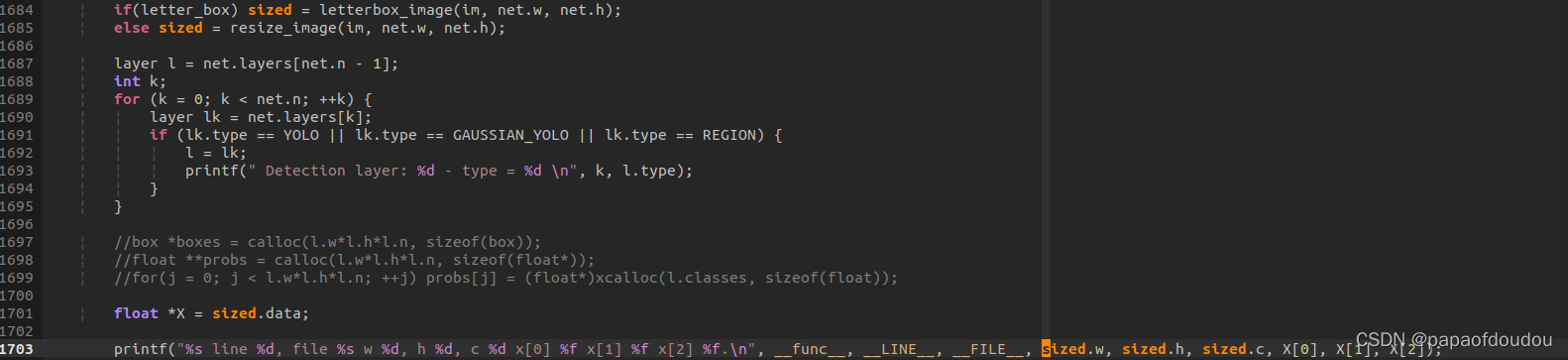
打印出来,看到确实是按照网络对图像尺寸的要求,数据变为416*416*3的数据。
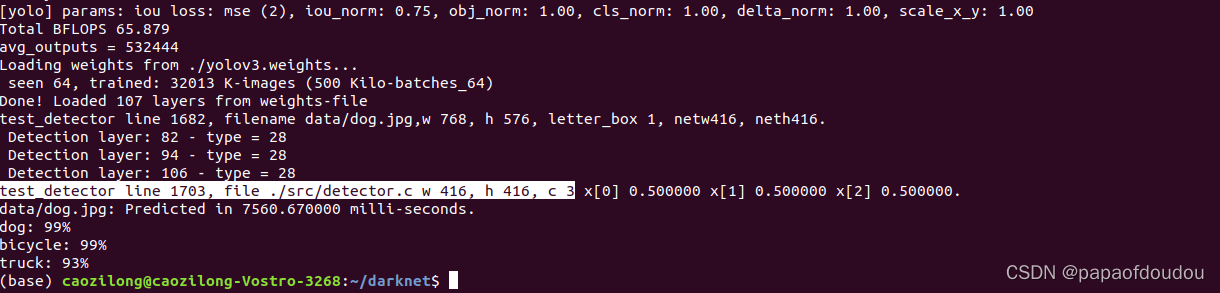
但是数据貌似是归一化[0,1]范围的浮点,而非RGB像素信息,我们把数据也打印出来:

并且我们加入了范围检测,检测最小值和最大值的存在,运行后,最大值为1,最小值为0,没有负值.
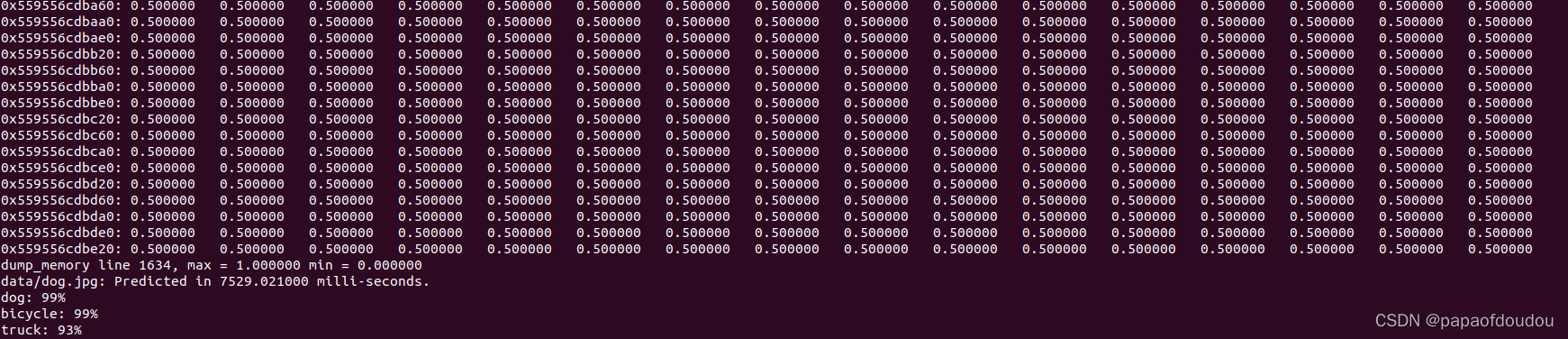
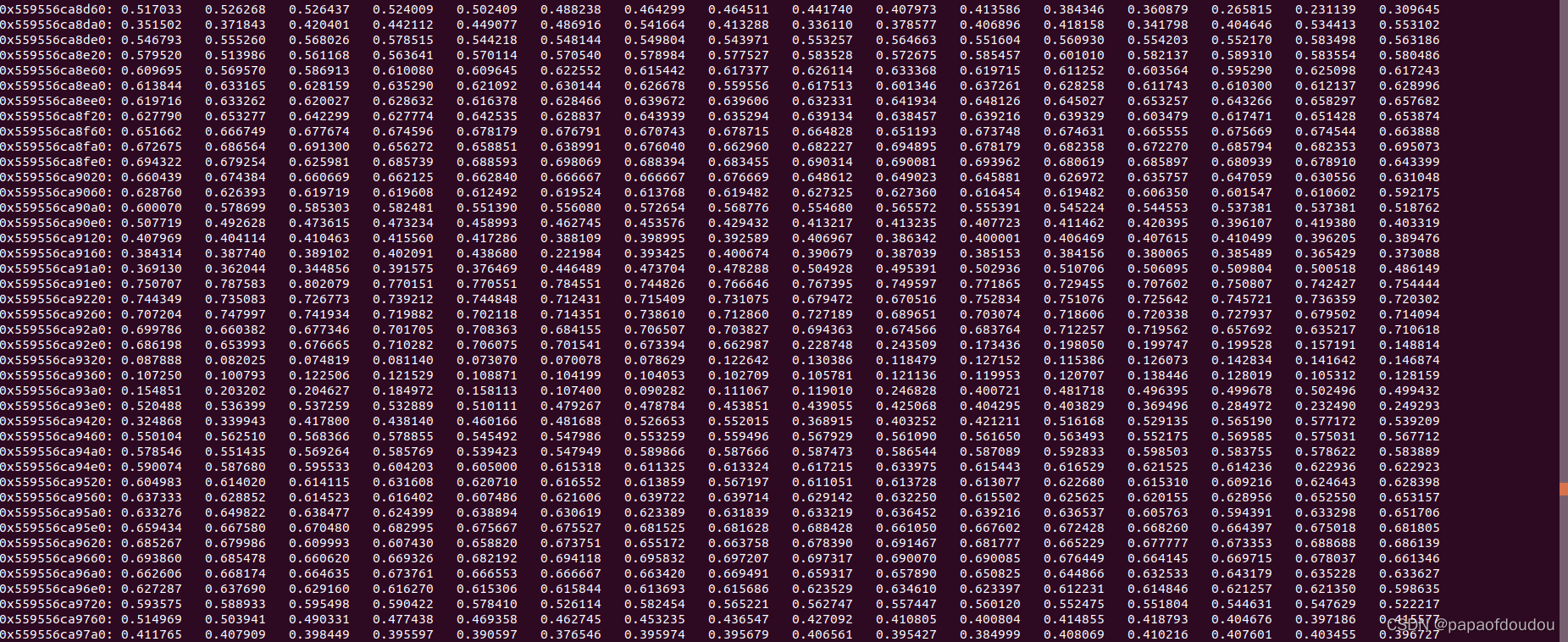
归一化的细节发生在那里呢?还需要再寻找。
继续寻找归一化的前奏,对输入图像的最早处理是发生在下面这段代码:

打印:

所以,你看到,图像装载的时候就已经归一化为小数了。归一化是在哪里发生的呢?我们追踪一下load _image的实现,可以很明显看到最后一步除了255。


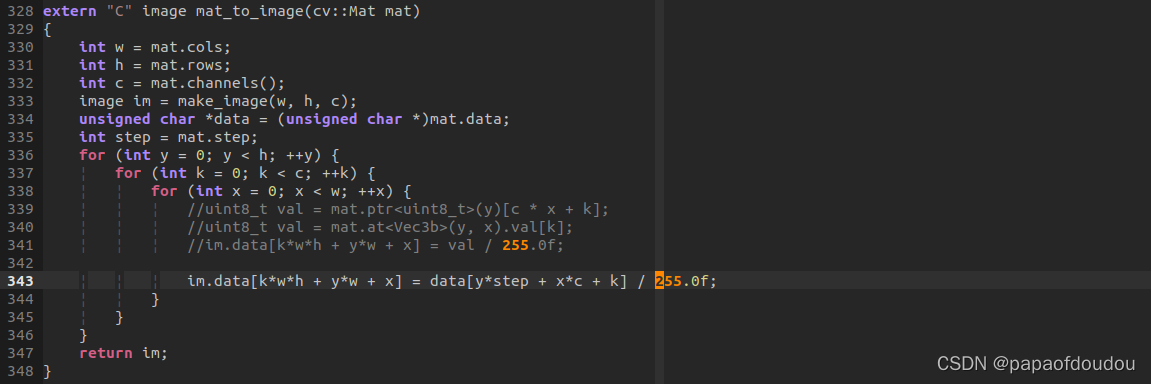
Darknet 对于缩放的实现,使用了最临近插值的算法,算法原理可以参考博客
 https://blog.youkuaiyun.com/tugouxp/article/details/120110219
https://blog.youkuaiyun.com/tugouxp/article/details/120110219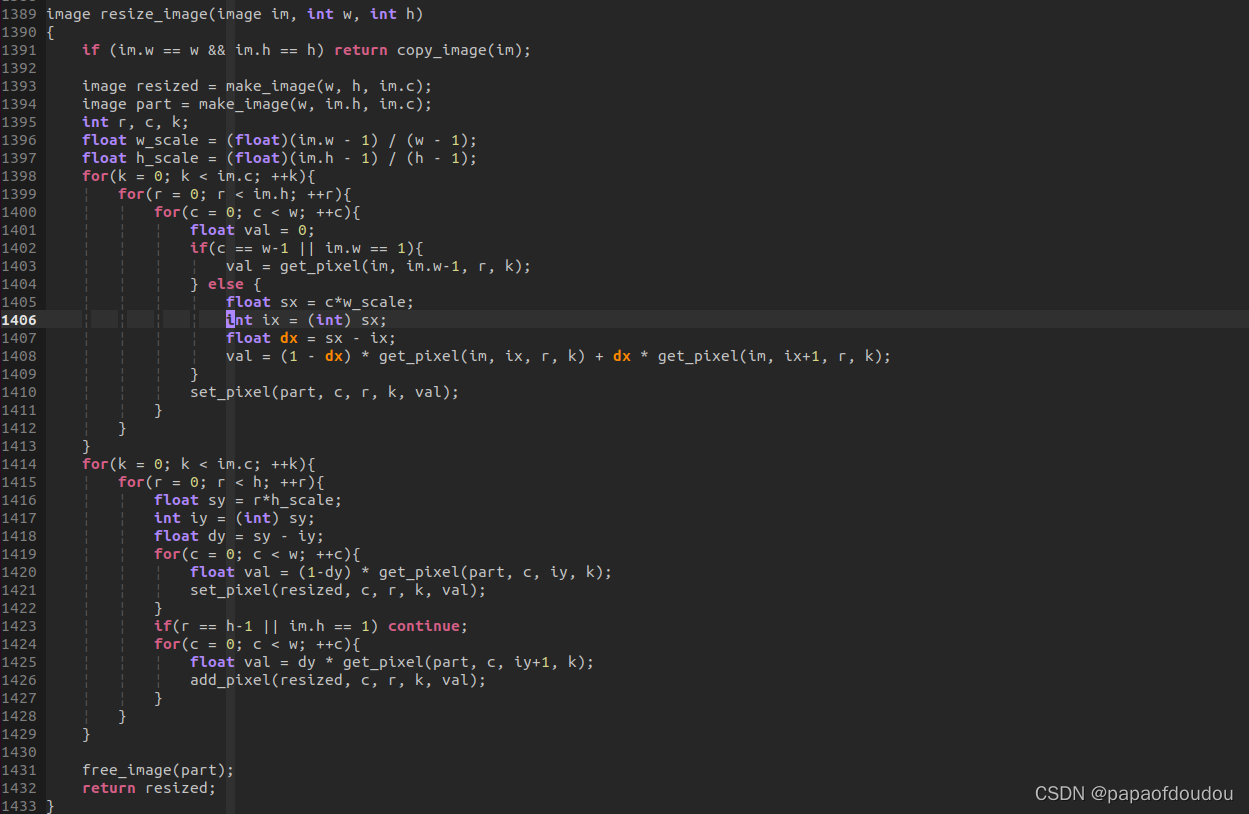
不难看出YOLOV3网络的输入是按照NCHW的方式组织TENSOR的,矩阵在这里经过一次转置。

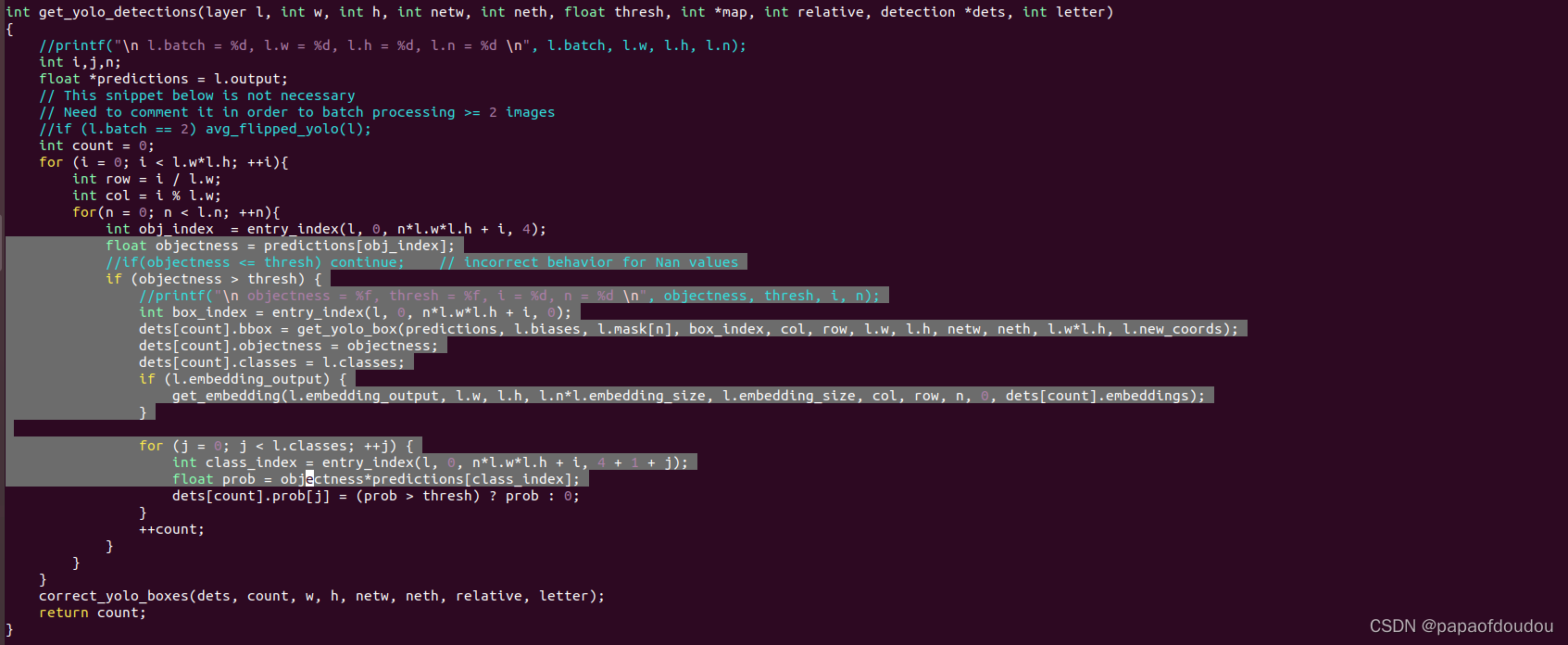
darknet每个框针对每类对象的概率怎么算的?
下面这段代码来自于darknet代码,通过它可以看的出来,计算方法是这个框有物体的置信度乘以每类的概率,为这个框中有某类目标的最后概率,这有点像是条件概率。
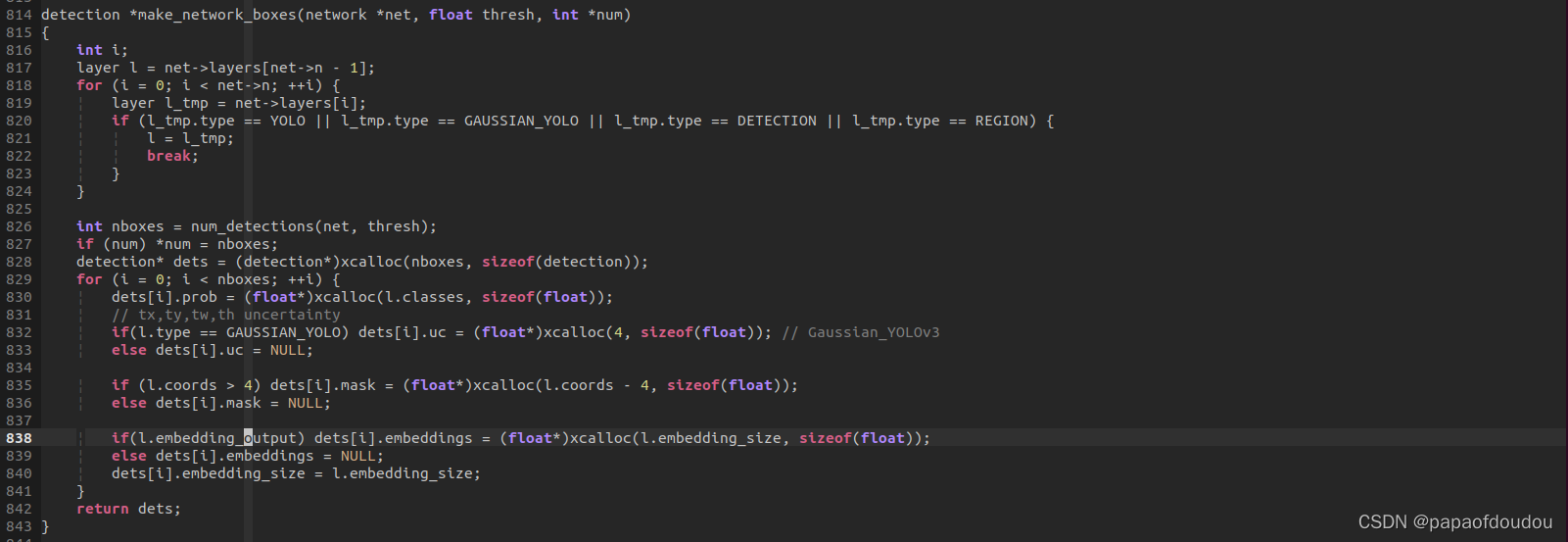
YOLO层数计算:
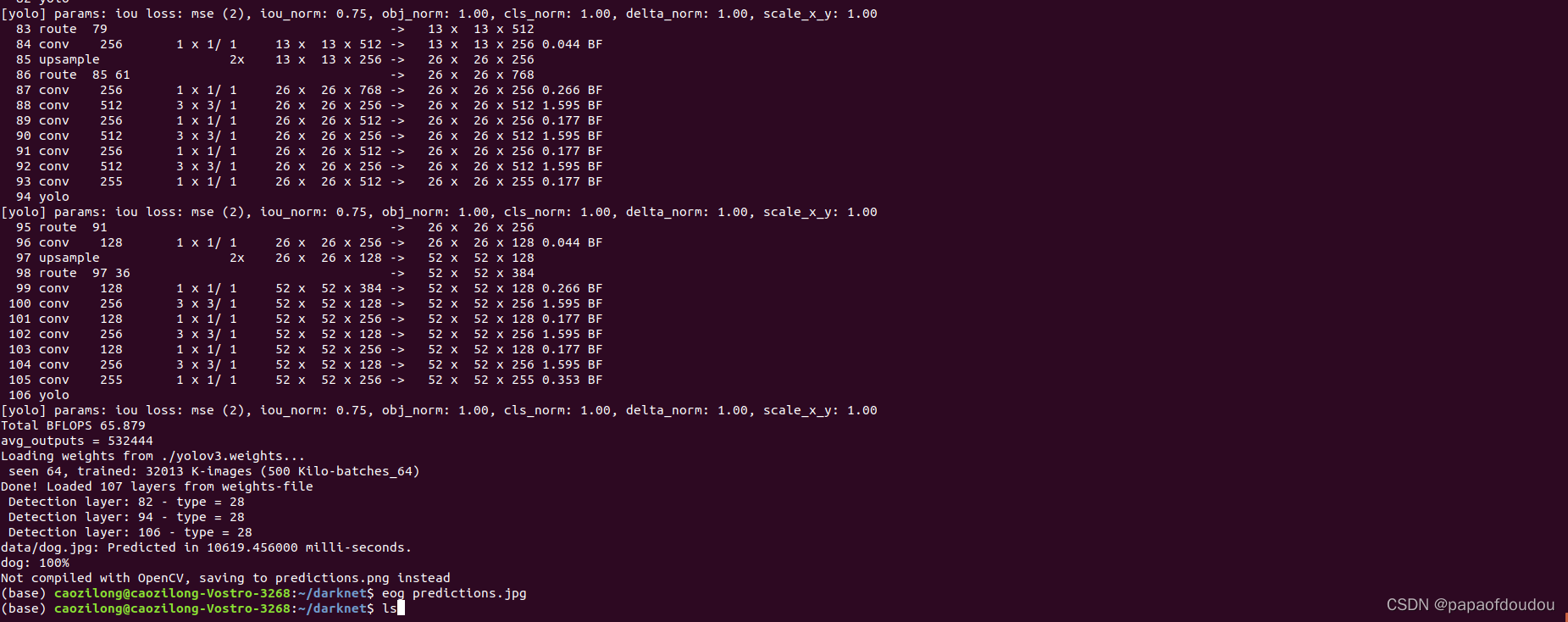
可以看到Detection layer一共有三层,分别是82,94,106。
Detection layer: 82 - type = 28
Detection layer: 94 - type = 28
Detection layer: 106 - type = 28
这个序号应该是yolov3.cfg文件中层数序号,执行命令:
grep "\[.*\]" cfg/yolov3.cfg

如果将三个YOLO层序号减去2,便得到了上面打印的输出。
为什么要减2呢,感觉原因,1是第一层net层是网络配置层,不需要计算在内,二是网络层计算从0开始 :

28表示YOLO层,darknet针对不同类型的层定义了枚举类型。

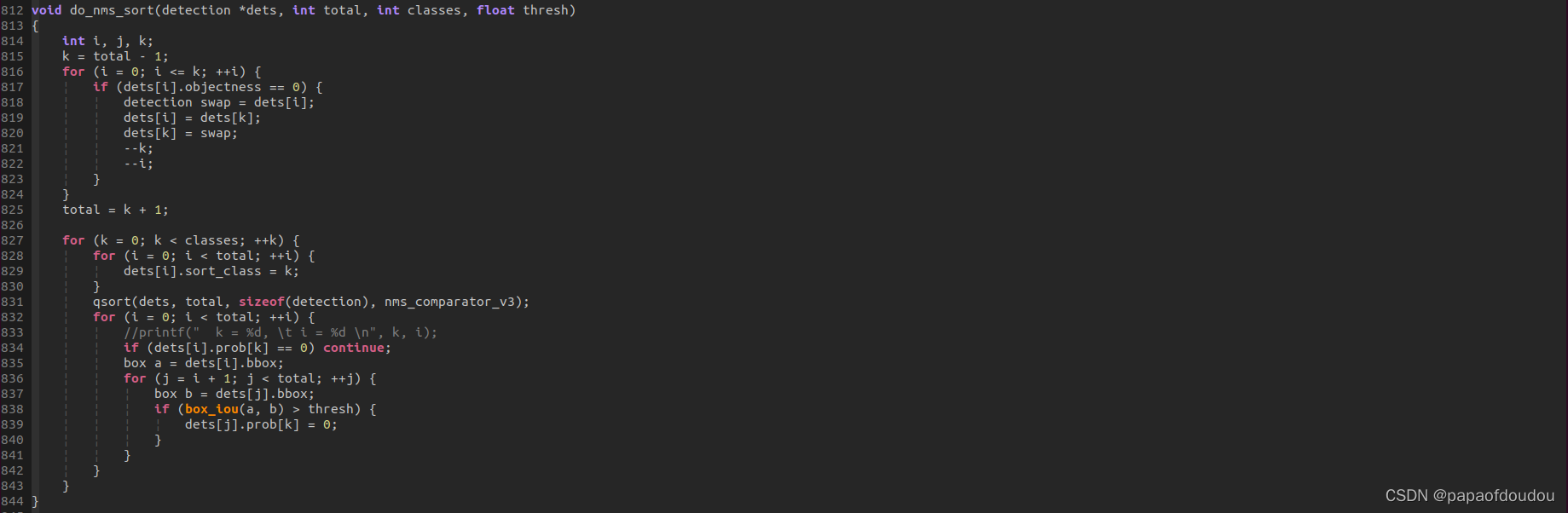
do_nms_sort的调用堆栈

可以看到NMS阀值设置的0.45
如果将NMS阀值设置的过于大,比如0.9,就是下面的样子:
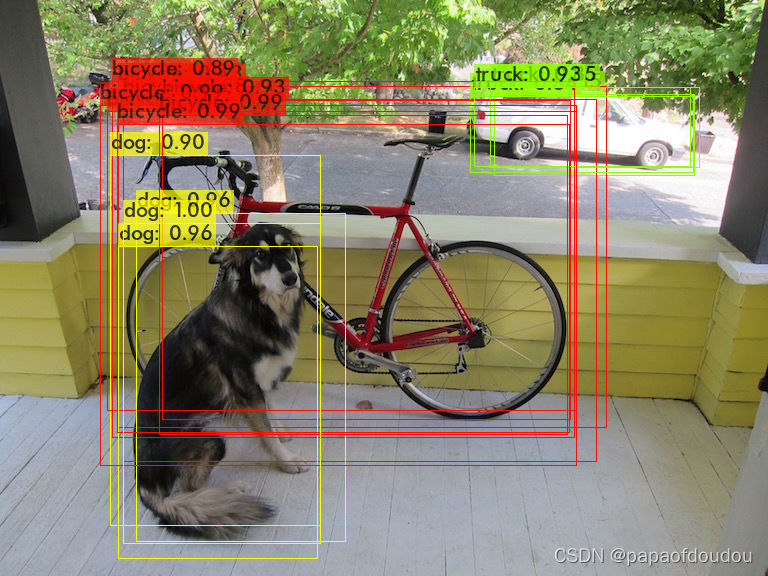
如果设置的过小,比如0.01,则是正常的。

而类别概率阀值则从另一个维度去限制框的输出:
./darknet detector test ./cfg/coco.data ./cfg/yolov3.cfg ./yolov3.weights data/dog.jpg -i 0 -thresh 0.01
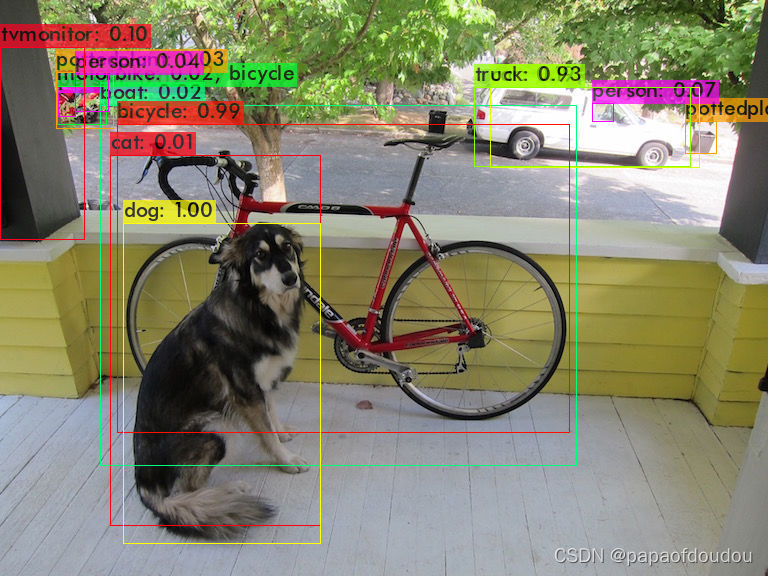
0.001

NMS去重的关键代码:
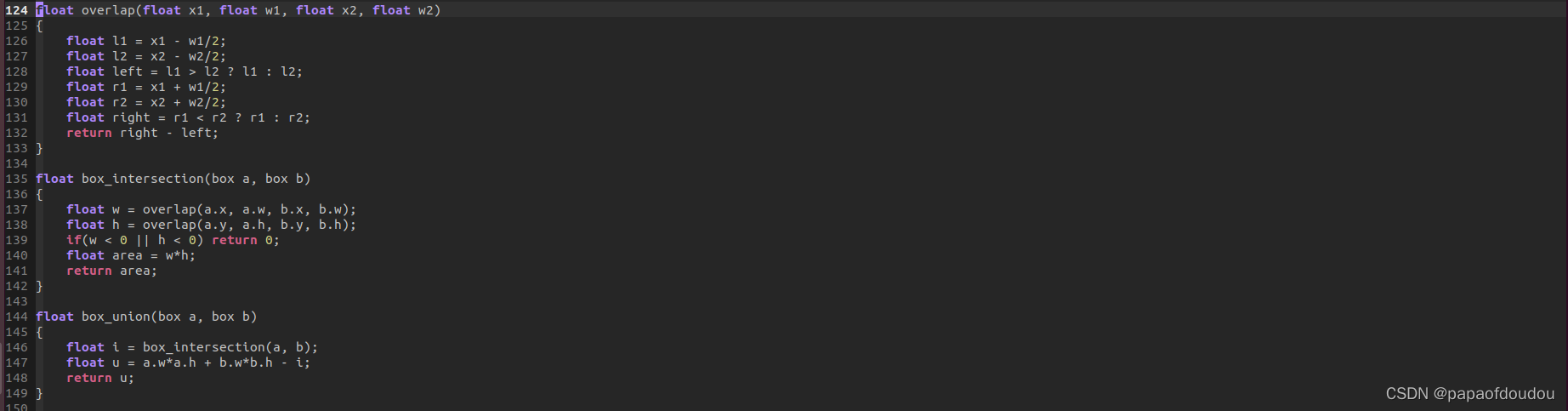
阀值和IOU交并比是一个单位的概念

#include <stdio.h>
#include <stdlib.h>
typedef struct box {
float x, y, w, h;
} box;
float overlap(float x1, float w1, float x2, float w2)
{
float l1 = x1 - w1/2;
float l2 = x2 - w2/2;
float left = l1 > l2 ? l1 : l2;
float r1 = x1 + w1/2;
float r2 = x2 + w2/2;
float right = r1 < r2 ? r1 : r2;
return right - left;
}
float box_intersection(box a, box b)
{
float w = overlap(a.x, a.w, b.x, b.w);
float h = overlap(a.y, a.h, b.y, b.h);
if(w < 0 || h < 0) return 0;
float area = w*h;
return area;
}
float box_union(box a, box b)
{
float i = box_intersection(a, b);
float u = a.w*a.h + b.w*b.h - i;
return u;
}
float box_iou(box a, box b)
{
float I = box_intersection(a, b);
float U = box_union(a, b);
if (I == 0 || U == 0) {
return 0;
}
printf("I = %f, U = %f.\n", I, U);
return I / U;
}
int main(void)
{
box a, b;
a.x = 6;
a.y = 6;
a.w = 100;
a.h = 100;
b.x = 1210;
b.y = 1210;
b.w = 1000;
b.h = 1000;
float iou = box_union(a, b);
float iou_r = box_iou(a, b);
printf("%s line %d, iou = %f, iou_r=%f.\n", __func__, __LINE__, iou, iou_r);
return 0;
}BOX 结构体X,Y是中心点坐标。
如何调试darknet?

YOLOV3有多少层?
从程序看,有107层。
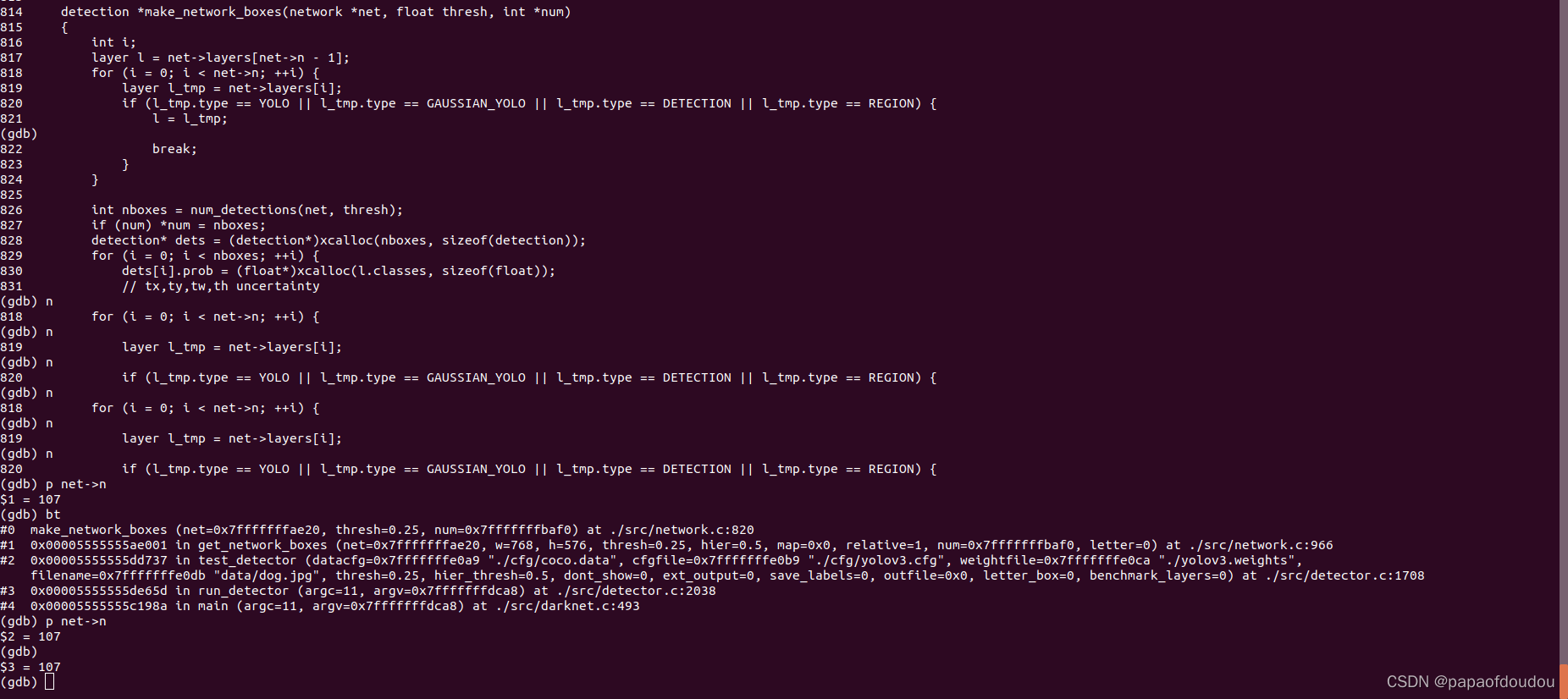
YOLOV3后处理的入口
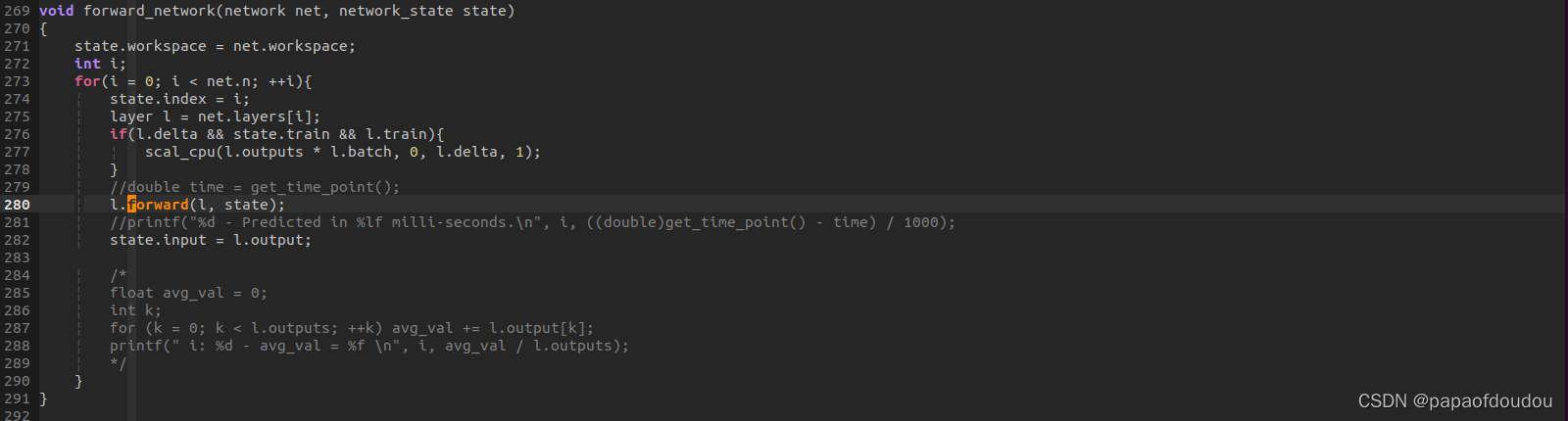
forward_network前向推理
YOLO层的核心逻辑
精华都在forward_yolo_layer函数处理中,函数开头直接将输入拷贝到输出,表示本层网络无需处理,而是直接进行后处理的逻辑。
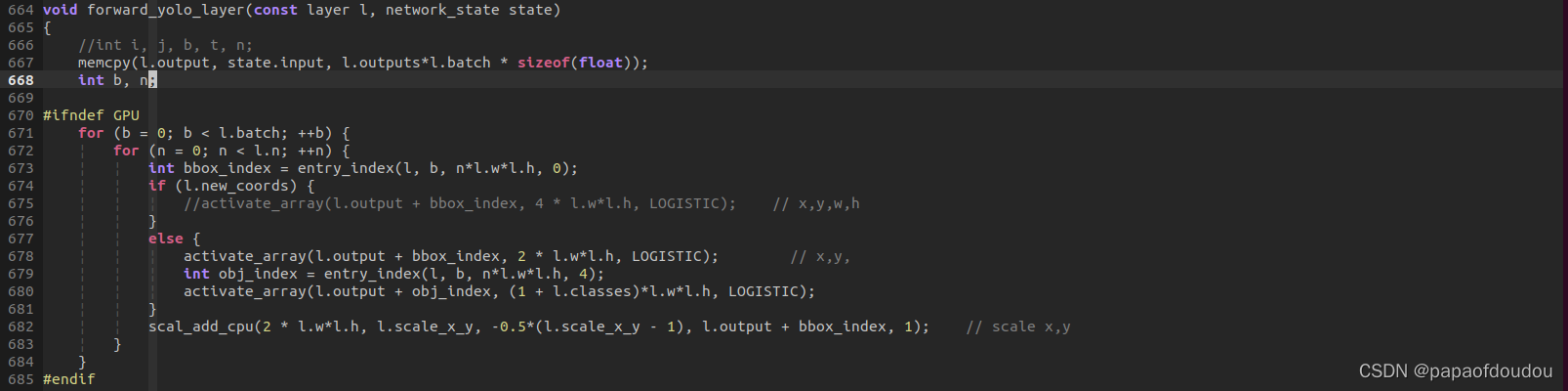
调试如下,由于是单帧图像推理,所以这里BATCH为1,然后数据量为13*13*255=43095

DARKNET网络名各层解析:
darknet非线性激活函数的类型:

darknet图像量化,不过此量化可能非彼量化

l.scale_x_y为1,所以下面红色的行注释掉不影响结果的正确性。
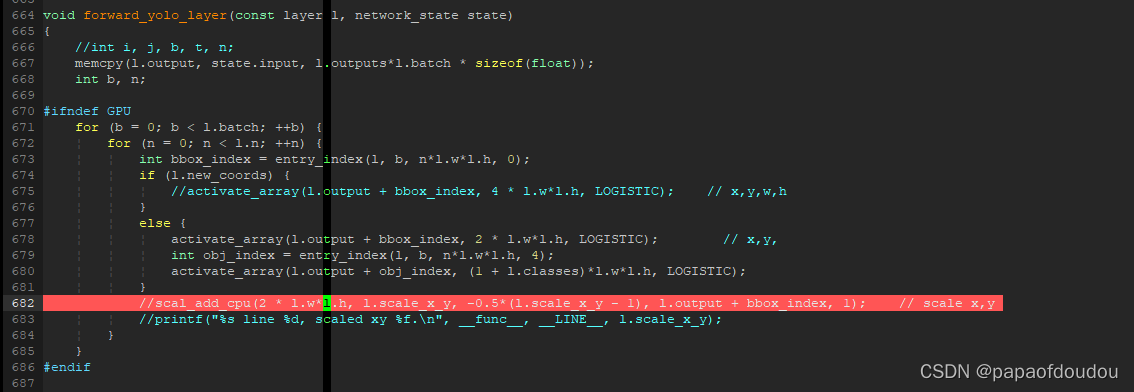
get_yolo_detections的作用
注释掉,貌似框没有变化,所以它的作用就是没有作用?



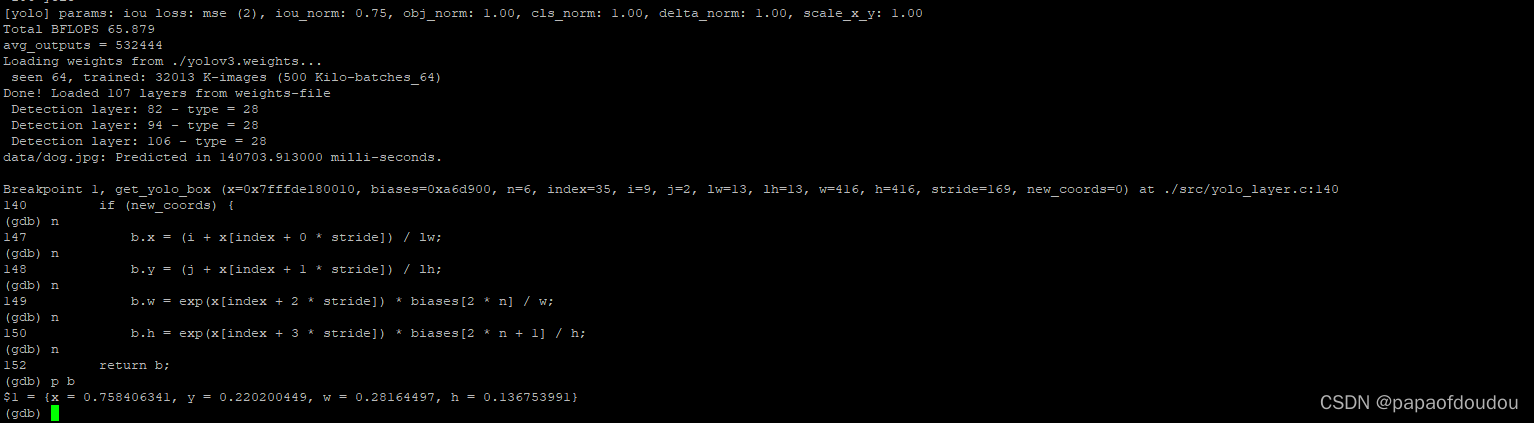
get_yolo_box得到的是浮点数,并且是相对于13*13图的坐标位置:
何谓部署,部署的三大目标:
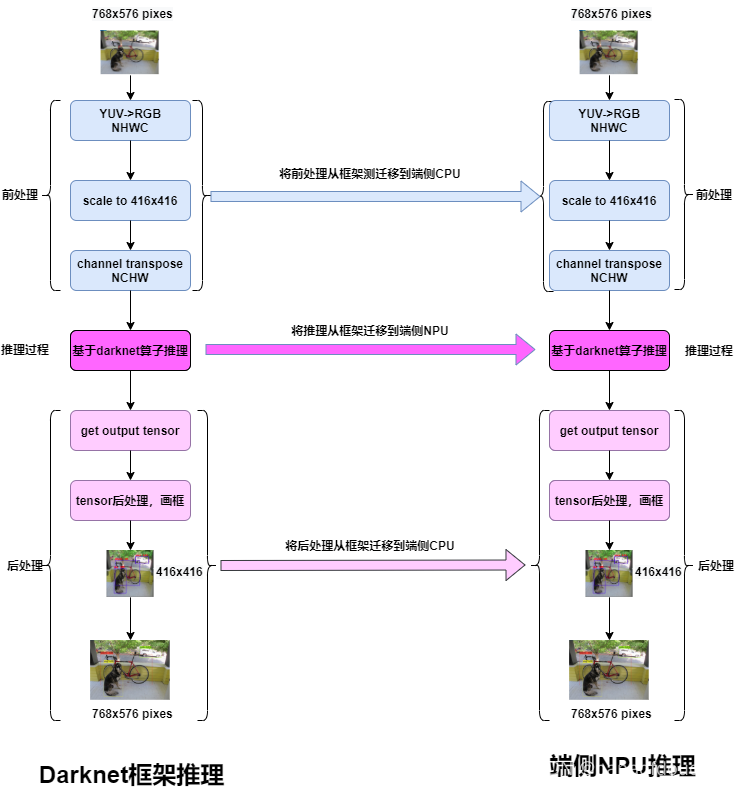
部署的三大目标:
1.前处理从框架迁移到端侧NPU.
2.推理从框架算子迁移到NPU端.
3.将后处理从框架迁移到端侧NPU.
带GPU的demo推理调用堆栈

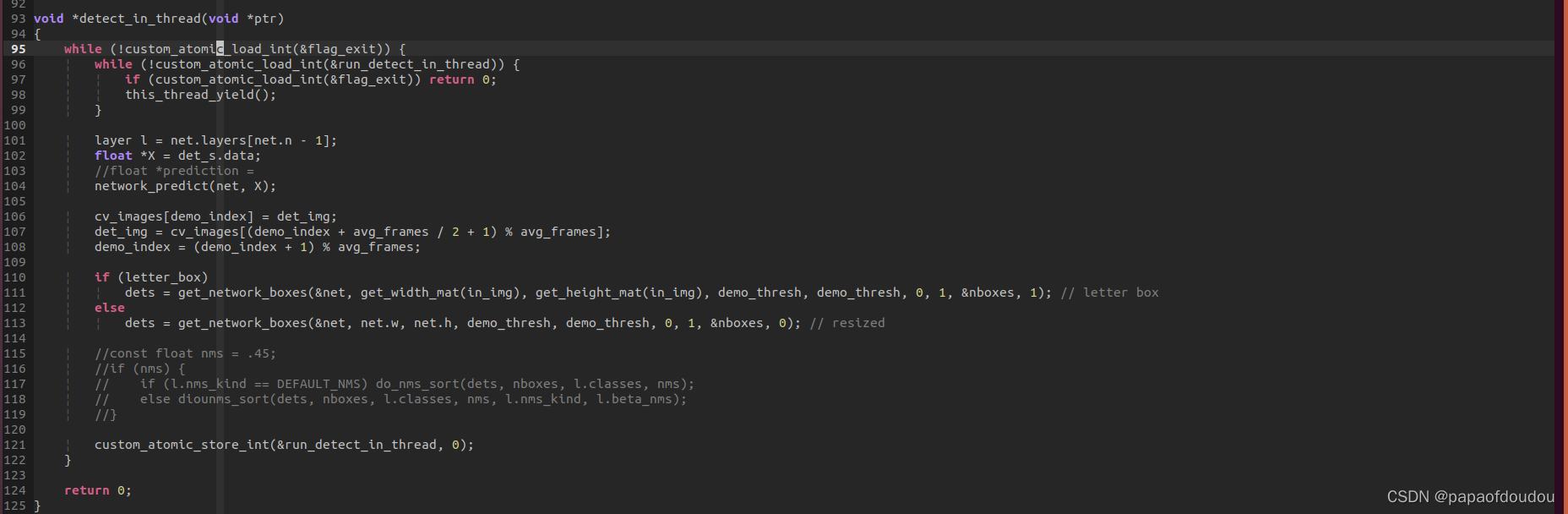
darknet视频帧检测帧率统计逻辑


可以看到,根据算法,FPS确实有一个逐渐增加的过程。
cjson的转换



















 6936
6936

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











