MapReduce1
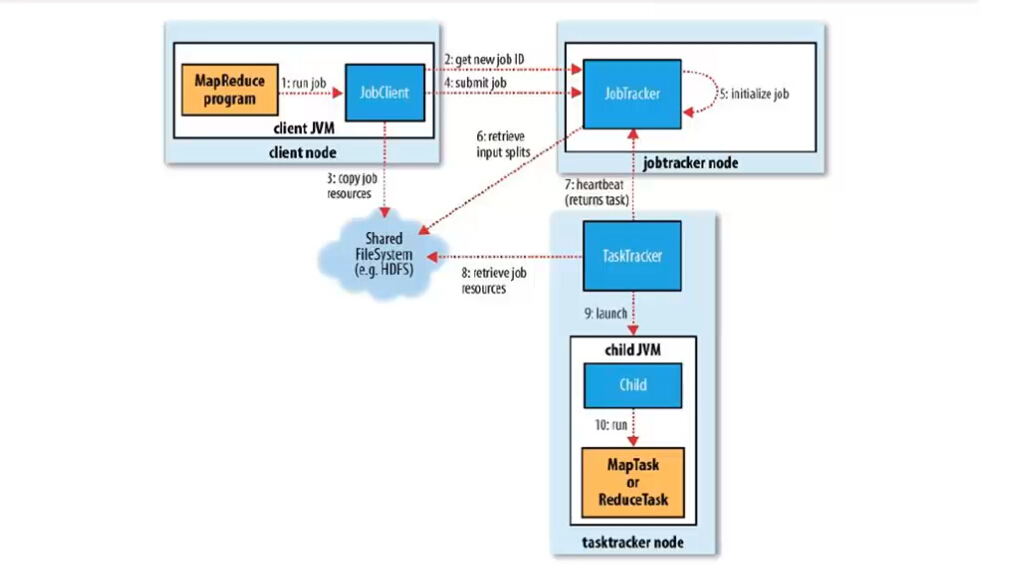
分为6个步骤:
1、作业的提交
1)、客户端向jobtracker请求一个新的作业ID(通过JobTracker的getNewJobId()方法获取,见第2步
2)、计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个以ID命名的jobtracker的文件系统中(HDFS),见第3步
3)、告知jobtracker作业准备执行,见第4步
2、作业的初始化
4)、JobTracker收到对其submitJob()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,见第5步
5)、作业调度器首先从共享文件系统HDFS中获取客户端已经计算好的输入分片,见第6步
6)、为每个分片创建一个map任务和reduce任务,以及作业创建和作业清理的任务。
3、任务的分配
7)、tasktracker定期向jobtracker发送“心跳”,表明自己还活着。见第7步
8)、jobtracker为tasktracker分配任务,对于map任务,jobtracker会考虑tasktracker的网络位置,选取一个距离其输入分片文件最近的tasktracker,对于reduce任务,jobtracker会从reduce任务列表中选取下一个来执行。
4、任务的执行
9)、从HDFS中把作业的jar文件复制到tasktracker所在的文件系统,实现jar文件本地化,同时,tasktracker将应用程序所需的全部文件从分布式缓存中复制到本地磁盘,见第8步,并且tasktracker为任务新建一个本地工作目录,并把jar文件的内容解压到这个文件夹下,然后新建一个taskRunner实例运行该任务
10)、TaskRunner启动一个新的JVM(见第9步)来运行每个任务(见第10步)
5、进度和状态的更新
11)、任务运行期间,对其进度progress保持追踪。对map进度是已经处理输入所占的比例。对于reduce任务,分三部分,与shuffle的三个阶段相对应。
Shuffle是系统执行排序的过程。是mapreduce的心脏。
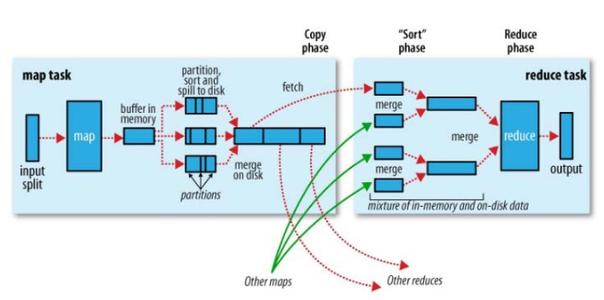
对于map端而言:每个map任务都有一个环形内存缓冲区,默认是0.8,当缓冲区达到阈值时便开始把内容溢出spill到磁盘,在写入磁盘之前,线程会根据数据最终要传的reducer把数据划分成相应的分区,每个分区中,按键值进行内排序,如果有combine(使结果更紧凑),会在combine完成之后再写入磁盘。
对于reducer端而言,map的输出文件位于tasktracker的本地磁盘,每个map任务完成的时间可能不同,只要有一个完成,就会复制其输出(这就是复制阶段),然后把map的输出进行merge合并,然后直接把数据输入到reduce函数,完成输出。
6、作业的完成
可以看得出原来的 map-reduce 架构是简单明了的,在最初推出的几年,也得到了众多的成功案例,获得业界广泛的支持和肯定,但随着分布式系统集群的规模和其工作负荷的增长,原框架的问题逐渐浮出水面,主要的问题集中如下:
JobTracker 是 Map-reduce 的集中处理点,存在单点故障。
JobTracker 完成了太多的任务,造成了过多的资源消耗,当 map-reduce job 非常多的时候,会造成很大的内存开销,潜在来说,也增加了 JobTracker fail 的风险,这也是业界普遍总结出老 Hadoop 的 Map-Reduce 只能支持 4000 节点主机的上限。
在 TaskTracker 端,以 map/reduce task 的数目作为资源的表示过于简单,没有考虑到 cpu/ 内存的占用情况,如果两个大内存消耗的 task 被调度到了一块,很容易出现 OOM。
在 TaskTracker 端,把资源强制划分为 map task slot 和 reduce task slot, 如果当系统中只有 map task 或者只有 reduce task 的时候,会造成资源的浪费,也就是前面提过的集群资源利用的问题。
源代码层面分析的时候,会发现代码非常的难读,常常因为一个 class 做了太多的事情,代码量达 3000 多行,,造成 class 的任务不清晰,增加 bug 修复和版本维护的难度。
从操作的角度来看,现在的 Hadoop MapReduce 框架在有任何重要的或者不重要的变化 ( 例如 bug 修复,性能提升和特性化 ) 时,都会强制进行系统级别的升级更新。更糟的是,它不管用户的喜好,强制让分布式集群系统的每一个用户端同时更新。这些更新会让用户为了验证他们之前的应用程序是不是适用新的 Hadoop 版本而浪费大量时间。
YARN(MapReduce2)
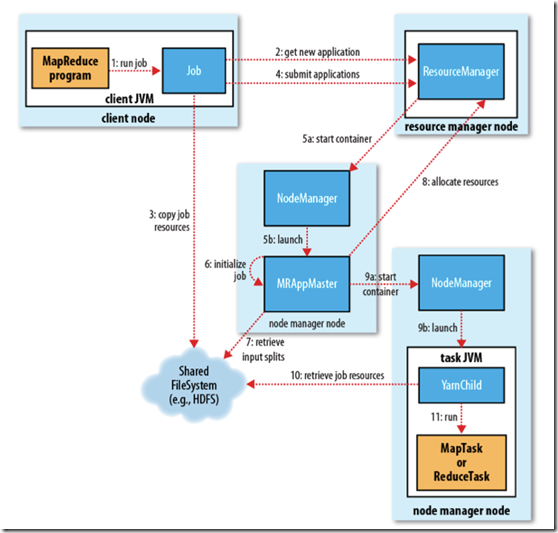
分6步执行:
1、作业提交
1)、客户端向ResourceManager请求一个新的作业ID,ResourceManager收到后,回应一个ApplicationID,见第2步
2)、计算作业的输入分片,将运行作业所需要的资源(包括jar文件、配置文件和计算得到的输入分片)复制到一个(HDFS),见第3步
3)、告知ResourceManager作业准备执行,并且调用submitApplication()提交作业,见第4步
2、作业初始化
4)、ResourceManager收到对其submitApplication()方法的调用后,会把此调用放入一个内部队列中,交由作业调度器进行调度,并对其初始化,然后为该其分配一个contain容器,见第5步
5)、并与对应的NodeManager通信见第5a步,要求它在Contain中启动ApplicationMaster见第5b步
6)、ApplicationMaster启动后,会对作业进行初始化,并保持作业的追踪见第6步.
7)、ApplicationMaster从HDFS中共享资源,,接受客户端计算的输入分片为每个分片。见第7步
3、任务分配
8)、ApplicationMaster想ResourceManager注册,这样就可以直接通过RM查看应用的运行状态,然后为所有的map和reduce任务获取资源,见第8步
4、任务执行
9)、ApplicationMaster申请到资源后,与NodeManager进行交互,要求它在Contain容器中启动执行任务。见第9a、9b步
5、进度和状态的更新
10)、各个任务通过RPC协议umbilical接口向ApplicationMaster汇报自己的状态和进度,方便ApplicationMaster随时掌握各个任务的运行状态。用户也可以向ApplicationMaster查询运行状态。
6、作业完成
11)、应用完成后,ApplicationMaster向ResourceManager注销并关闭自己。
新旧MR对比
让我们来对新旧 MapReduce 框架做详细的分析和对比,可以看到有以下几点显著变化:
首先客户端不变,其调用 API 及接口大部分保持兼容,这也是为了对开发使用者透明化,使其不必对原有代码做大的改变 ( 详见 2.3
Demo 代码开发及详解),但是原框架中核心的 JobTracker 和 TaskTracker 不见了,取而代之的是 ResourceManager, ApplicationMaster 与 NodeManager 三个部分。
我们来详细解释这三个部分,首先 ResourceManager 是一个中心的服务,它做的事情是调度、启动每一个 Job 所属的 ApplicationMaster、另外监控 ApplicationMaster 的存在情况。细心的读者会发现:Job 里面所在的 task 的监控、重启等等内容不见了。这就是 AppMst 存在的原因。ResourceManager 负责作业与资源的调度。接收 JobSubmitter 提交的作业,按照作业的上下文 (Context) 信息,以及从 NodeManager 收集来的状态信息,启动调度过程,分配一个
Container 作为 App Mstr
NodeManager 功能比较专一,就是负责 Container 状态的维护,并向 RM 保持心跳。
ApplicationMaster 负责一个 Job 生命周期内的所有工作,类似老的框架中 JobTracker。但注意每一个 Job(不是每一种)都有一个 ApplicationMaster,它可以运行在 ResourceManager 以外的机器上。
Yarn 框架相对于老的 MapReduce 框架什么优势呢?我们可以看到:
这个设计大大减小了 JobTracker(也就是现在的 ResourceManager)的资源消耗,并且让监测每一个 Job 子任务 (tasks) 状态的程序分布式化了,更安全、更优美。
在新的 Yarn 中,ApplicationMaster 是一个可变更的部分,用户可以对不同的编程模型写自己的 AppMst,让更多类型的编程模型能够跑在 Hadoop 集群中,可以参考 hadoop Yarn 官方配置模板中的
mapred-site.xml 配置。
对于资源的表示以内存为单位 ( 在目前版本的 Yarn 中,没有考虑 cpu 的占用 ),比之前以剩余 slot 数目更合理。
老的框架中,JobTracker 一个很大的负担就是监控 job 下的 tasks 的运行状况,现在,这个部分就扔给 ApplicationMaster 做了,而 ResourceManager 中有一个模块叫做 ApplicationsMasters( 注意不是 ApplicationMaster),它是监测 ApplicationMaster 的运行状况,如果出问题,会将其在其他机器上重启。
Container 是 Yarn 为了将来作资源隔离而提出的一个框架。这一点应该借鉴了 Mesos 的工作,目前是一个框架,仅仅提供 java 虚拟机内存的隔离 ,hadoop 团队的设计思路应该后续能支持更多的资源调度和控制 , 既然资源表示成内存量,那就没有了之前的 map slot/reduce slot 分开造成集群资源闲置的尴尬情况。

























 843
843

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









