










DAnet
摘要
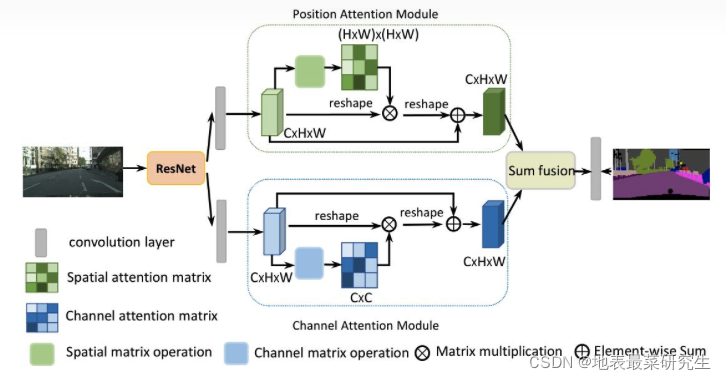
- 介绍:我们通过基于自我注意机制捕获丰富的上下文依赖关系来解决场景分割任务。与以往通过多尺度特征融合来捕获上下文的工作不同,我们提出了一个双注意网络(DANet)来自适应地集成局部特征与其全局依赖性。
- 文章思想:在扩展的FCN之上附加了两种类型的注意模块,它们分别模拟了空间维度和通道维度上的语义相互依赖关系。
- 文章亮点:将空间维度和通道维度上的语义信息分开进行提取,最后再做特征融合
- 模型评估:在不使用粗糙数据的情况下,在城市景观测试集上的平均IoU得分为81.5%。
ExFuse(基于GCN网络基础上进行改进)
摘要
- 背景介绍:现代语义分割框架通常使用特征融合的方式提升分割性能(例如Unet中的跳层连接),但是由于高级特征和低级特征之间存在差距,直接融合的效果并不是很好
- 文章思想: 在底层特征中引入语义信息,在高层特征中引入细节信息,这样会使后续融合更加有效(弥补高级特征图和低级特征图之间的巨大差距)
- 文章亮点: 提出了ExFuse,用来弥补高底层特征之间的差距
- 模型评估:在PASCAL VOC 2012数据集上取得87.9%的MIoU
算法详解
上图中对应Unet初级特征图包含清晰的轮廓等细节信息但是语义信息不明显,下面高级特征图包含清晰的语义信息(bus的位置)但是缺少清晰的边界信息。
下图对应ExFuse网络结构,将高级语义信息通过上采样方式与初级特征图进行融合,同时出击特征图通过下采样的方式与高级特征图进行融合,得到具有较好语义信息和空间信息的特征图像。【在低级特征中引入高级语义信息/在高级特征中引入低级空间信息】
- 一般而言,低级特征和高级特征相辅相成。假设存在一个极端例子,低级特征只编码了地籍信息(点线面),直观来讲,高级特征与这些“纯”低级特征的融合意义不大,因为后者的噪声太多,无法提供高分辨率的语义信息。
- 相反,如果低级特征包含更多的语义信息,比如,编码相对明确的语义框再做融合会简单不少——良好的分割结果可以通过对齐高级特征图和低级特征中的语义框而获得
- 相似的,“纯”高级特征的空间信息也很少,不能充分利用第几特征;但是,通过潜入额外的高分辨率特征,高级特征从而有机会通过对其最近的低级语义框来实现自我优化【对应上图第二个模型】
【梳理】
- 低级特征:卷积网络开始的几层,分辨率比较高,包含较多空间信息,但是包含语义信息较少
- 高级特征:从神经网络中提取出的深层特征,分辨率低,高度语义化,但空间信息较少
【不同特征融合方式】
- 高低尺度跳层连接(U-shape)
- ASPP模块融合多尺度信息(空洞)
- PSPNet的空间金字塔池化(池化)
【算法结构】
输入图像大小【512*512】
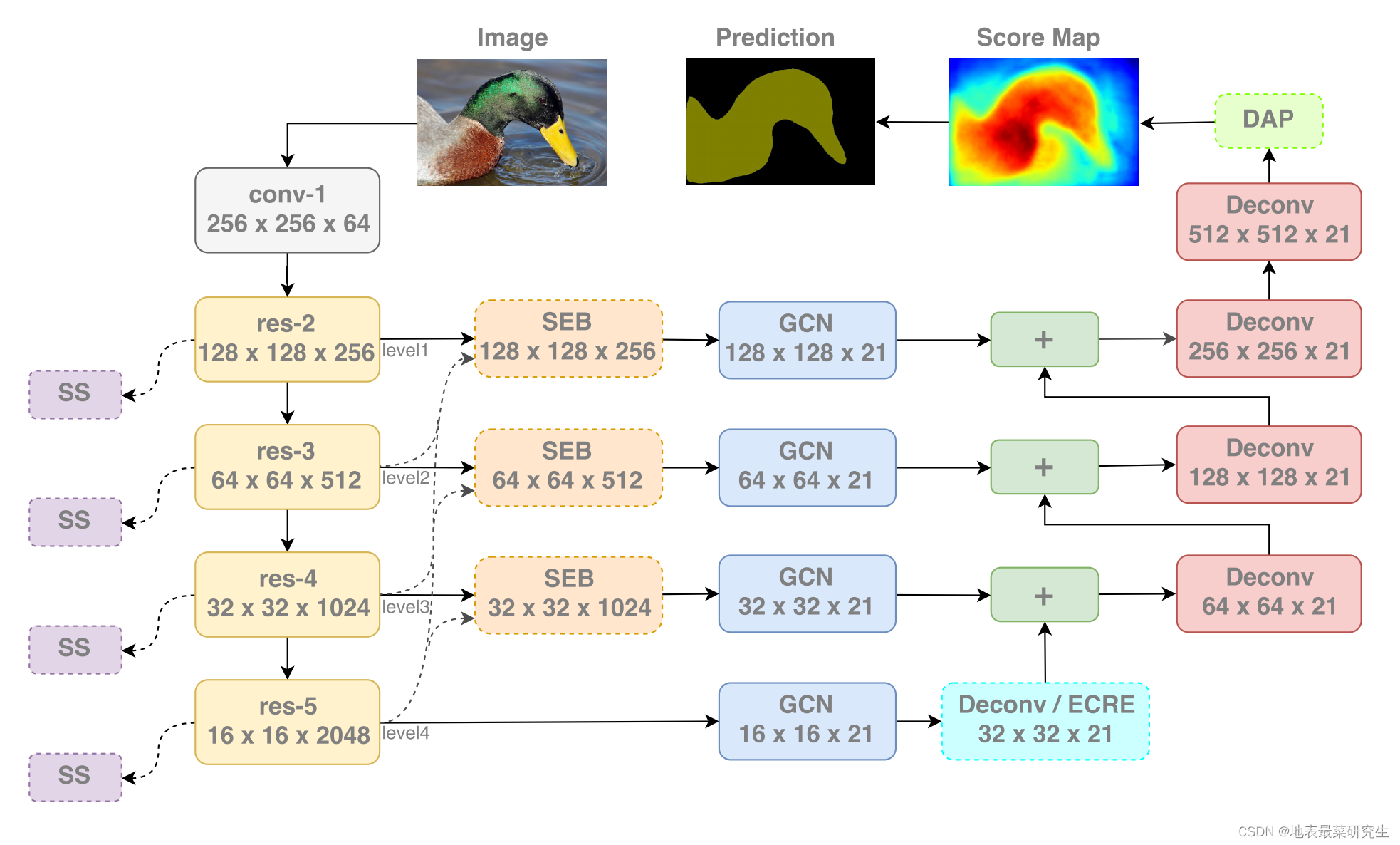
高级特征和低级特征之间存在差距,通过实验表明,从res-5~res2这几个特征之间的融合情况来看,添加了res-2与res-3之后,效果只提升了0.24%(参照原文Table1),所以生硬的将高级特征与低级特征进行融合并不能取得很好的效果。
本文思路就是将更多的高级语义信息集成到低级空间信息中,同时也将低级空间信息集成到高级语义信息中。
实验数据集以PASCAL VOC 2012为主,以未改进的GCN为Baseline 取得的分数为76.0%
- 【Layer Rearrangement层】层重组
本文使用ResNeXt作为特征提取网络,将ResNeXt101中的 {3, 4, 23, 3}网络架构方式,更换为 {8, 8, 9, 8}并且调整通道参数,以保证最终的计算复杂度。 - 【Semantic Supervision层】语义监督层(这里SS层之间如何定义权重未详细说明,下文DFN使用固定的参数实现,注意下文DFN中实现方式)
提出另一种改进低级特征的方式,直接将辅助监督分配到编码器网络早期的阶段。但是通过实验表明,对于ResNet或ResNeXt模型,深度监督训练是无用的,甚至损害了分类的准确性(见表2)。因此,我们的语义监督进行评估方法主要关注于提高低层次特性的质量(提升mIoU质量),而不是提高主干模型本身(降低了一点分类精确度)。 - 【Semantic Embedding Branch】语义嵌入分支
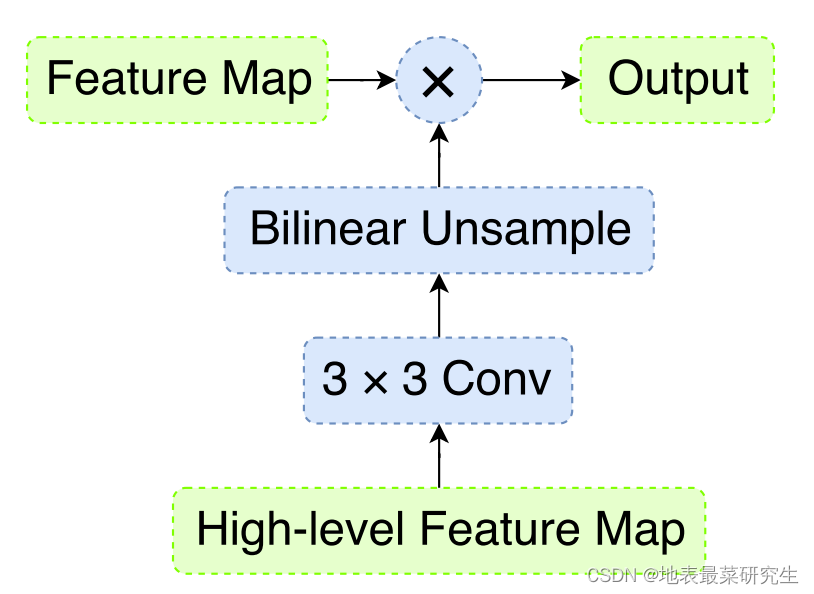
如上面示意图是SEB模块,通过将高级语义特征图进行卷积双线性插值的方式扩展到与上面一层特征图相同尺寸并进行拼接,得到输出进入GCN模块。
DFN
摘要
- 背景介绍:现代语义分割算法会存在类内不一致和类间不一致的问题
- 算法组成: 提出DFN网络,包括平滑网络和边界网络两部分
- 具体作用: 平滑网络用于解决雷内不一致问题,通过引入注意力机制和全局平均吃花选择更具代表性的特征;边界网络通过深度语义边界监督更好的区分双边特征
- 模型评估:在PASCAL VOC 2012和Cityscapes数据集中得到了86.2%和80.3%的MIoU
引言
语义分割所学习到的特征容易混淆
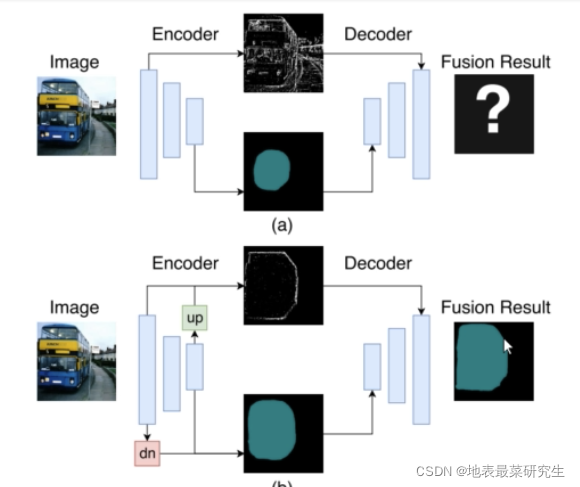
- 有相同语义标签但是形状不一样(类内不一致),如下图a与b
- 具有不用的语义标签但是外观相似的两个块(类间不一致),如下图d与e

本文从宏观角度看待语义分割就是将一致的语义标签分给一类事物,而不是每个像素。
这里提出了DFN网络(Discriminative Feature Network),同时考虑类内一致性和类间差异性。包含两个重要自网络【smmoth network/border network】平滑网络/边界网络 - 平滑网络:用来解决类内不一致问题【融合:多尺度信息/全局上下文信息】
- 边界网络:用来区分外观相似但是语义不一致的patch,普通语义分割忽略了位间区别,这里通过边界网络通过放大两个物体之间的不同点。使用Focal loss 监督边界信息【***Focl loss适合用于二分类问题 ***】
文章贡献
- 从宏观角度看待语义分割问题,而不是从像素任务的微观角度看待。
- 提出DFN网络同时解决类内不一致和类间一致性的问题
- 提出了smooth network 平滑网络,使用全局上下文(globale context)和(通道注意力机制Channel attention block)来增强类内一致性
- 设计了使用深度监督的自上而下的边界网络botton-up的 Border Network来增大语义边界两侧的特征差异。【重新定义了语义边界】
【Botton-up 和top-down】
- Botton-up是从下往上以数据驱动的,不需要借鉴上下文信息
- top-down相反,需要依赖于上下文信息,例如通过上下文辨别某个潦草的字。
相关工作
- Encoder-Decoder编码器解码器框架介绍:Segnet对池化层进行索引/Unet进行跳跃连接/GCN使用较大的卷积核提取更多特征,但这些网络忽略了全局上下文global context,且未考虑不同结算特征之间的差距
论文算法结构
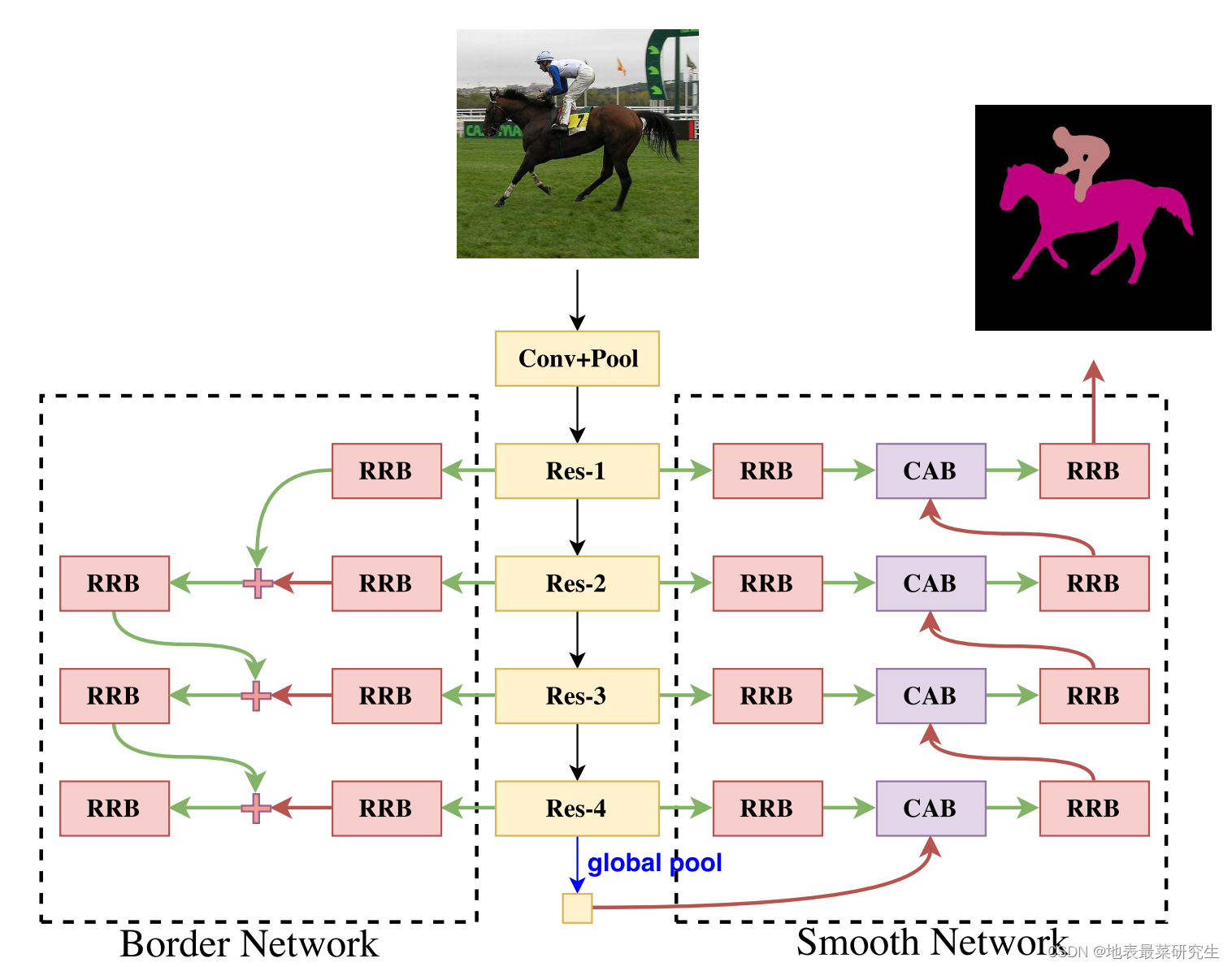
DFN整体网络结构如上图,通过堆叠RRB模块,实现Border Network 和 Smoooth Network。
- Border Network【提升边界定位的精确度】
- 1、主要思想 :利用多监督,使网络学习到的特征具有很强的不一致性。利用button-up的结构,获取更多的语义信息
- 2、优点:该模块可以从低阶网络获得边界信息,从高阶网络获取语义信息,再进行融合,避免缺失某类信息的情况出现。高阶语义信息具有优化低阶边缘信息的作用。
- 使用focal loss 监督Border Network的输出。
- 最底层的global pooling的作用
- 添加global pooling,网络从原来的扁平化Unet变为一个V形的网络,提升上下文信息。
- Smooth Network【解决大尺度和复杂场景下分类错误的问题】
- 1、问题1:不同尺度的感受野产生的特征具有不同程度的判别能力,会导致输出结果不一致。(曾有网络提出,感受野越大越好)
- 2、作用1:用高阶信息的一致性指导低阶信息从而提升预测效果
- 3、现有方法大致分为两种类型:一是“Backbone style”,如PSPNet、 Deeplab,将不同尺度的全局信息嵌入PSP模块或ASPP模块来提高网络的 一致性(consistency);二是“Encoder - Decoderstyle”,如 RefineNet、GCN,即利用不同阶段固有的多尺度语境,但缺乏具有强一 致性的全局语境
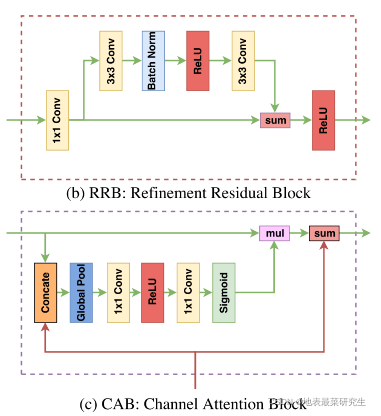
- 4、CAB优点及作用:具体见论文P3、P4,其中包括sigmoid的作用
DFN实验设置
- 损失函数:loss = FocalLoss + CrossEntropy, λ={0.05,0.1,0.5,0.75,1},论文结论λ=0.1时效果最好
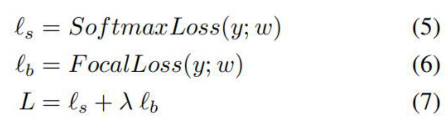
- 优化器:SGD + momentum 0.9
- 学习率:0.0001(“poly”方法调整学习率,power=0.9) (之前网网络讲过poly方法)
- batchsize:32
- 数据预处理:mean subtraction,
- 随机水平翻转,{0.5, 0.75,1,1.5,1.75}比例缩放


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









