




一、什么是决策树?
1.概念的理解
机器学习中的决策树是一种基于树状结构进行回归或分类任务的监督学习算法。
决策树在解决分类或分类问题时与人类在决策的过程极为类似,;例(此例来源西瓜书)如:我们要对“这是一个好瓜吗”这样的问题进行决策时,通常会进行一系列的是否的判断或 “子决策” 。这样从决策的过程来看连续的分支就像倒置的树一样,决策树由此得名。
二、决策树的基本流程
在我们决策的过程时要明确我们要处理的问题是什么,也就是说决策树要做分类或回归问题前首先需要确定我们要判断或者要区分的特征是什么。假如我们要通过决策树算法解决一个这样的问题:在概念的理解部分中提到的“这是一个好瓜吗”,我们首先需要找到一个根节点;然后通过这个根节点判断或生成内部节点;最后得到一个完全没有字叶节点的节点得到判断结果。
在决策树中一般我们用图形“圆”用来表示内部节点,用图形“矩形”表示叶节点。其中“圆”表示特征;矩形表示一个类别。
1.划分选择
这时我们会发现一个问题:当人们去判断一个瓜的好坏时会先看瓜的表面是否有坏的地方,如果没有坏的部分,紧接着会拍一拍瓜听一下瓜的声音再进一步判断瓜是好瓜还是坏瓜,这是一个有优先级的先后顺序,如:瓜表面的色泽的优先级就比瓜的声音优先级高。因为我们看到这个瓜色泽不饱满甚至颜色泛黄我们就基本可以推断这个瓜是坏瓜。这样我们通过一次一次的判断最终就可以分辨出一个瓜是否为好瓜。
a.熵
可计算机并不是人类,那它又是怎么判断“色泽”和“声音”这两个特征的优先级的高低呢? 在介绍决策树是利用什么机制来分辨之前我们先介绍一个描述信息的量“熵”。
熵是一个描述物质混乱程度的量。要清楚它是一个描述程度的量,如一副新买的扑克牌它在未拆分前是1234567890JQK这样从小到大排列的我们将此时的状态称为1,紧接着我们将其打乱,将打乱后的状态称为2,那么2的熵就大于1的熵,打乱的过程也称之为熵增的过程。
由此可见我们每次对某一特征进行判断时会产生不一样的结果。假如有两个不一样的决策树A、B:A和B用不同的类别作为根节点,各产生两种不同的分类结果a1、a2、b1、b2。其中a1为三红一白、a2三白一红,b1为全白、b2为全红。从分类结果来看,A的熵要大于B的熵,假如我们要利用A、B两个决策树来区分球的颜色那么用B特征为节点的拟合效果就会更好。由于以A特征的分类特征过于混乱所以该特征目前可以看成无效特征。
随机变量X熵的定义为
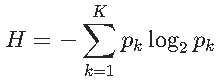
其中H越小熵越小,纯度越大,此时该特征分类效果越好。
b.信息增益
我们现在知道了什么是熵,在决策树生成的过程中如何利用熵来划分类别生成子节点呢,我们以ID3决策树为例,其用的便是信息增益。而C4.5和CART决策树分别则用的是信息增益比和基尼指数。
信息增益的概念则是:条件熵的减少程度,我们将特征的每个属性的熵乘以其在该特征下的条件概率便得到了该属性的条件熵,再用该属性的熵减去条件熵得到条件熵的减少程度便得到了信息增益,信息增益越大的我们就用该特征划分节点。
信息增益的公式为:
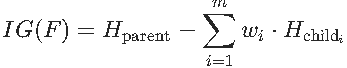
这样我们便可以使计算机也可以像人类一样通过信息增益的大小比较各特征的优先级来划分选择以哪个特征为根节点或接下来以什么特征为叶节点。

















 1224
1224

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









