






本来是想找一下多分类的混淆矩阵说明
但是发现网上的都是二分类,下面这种
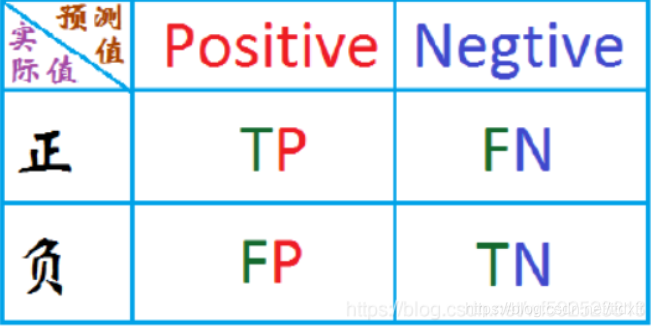
二分类的图转自博主,下面放上链接
https://blog.youkuaiyun.com/wf592523813/article/details/95202448
用自己的理解画了个多分类的混淆矩阵的表不知道对不对
和大家分享一下
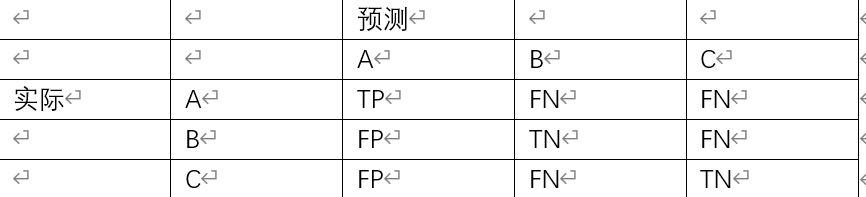
后来问了一下明白人,发现我这个不对TN不是这样归类的
因为如果按我这个来的话每一类分别算的准确率Acc都是一样的
应该是这样,为了简单举例
下面这个图是相对于B类而言的
多分类混淆矩阵TPTNFN
最新推荐文章于 2024-06-07 17:39:41 发布
 博客探讨了多分类混淆矩阵的正确构建方法,指出了一种常见错误的理解,即每个类别独立计算准确率。文中通过示例解释了混淆矩阵相对于某一特定类别的正确表示,并讨论了其对评估分类模型性能的重要性。
博客探讨了多分类混淆矩阵的正确构建方法,指出了一种常见错误的理解,即每个类别独立计算准确率。文中通过示例解释了混淆矩阵相对于某一特定类别的正确表示,并讨论了其对评估分类模型性能的重要性。

















 2597
2597

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









