







 本文详细介绍了如何使用pandas的pivot_table函数,包括参数解读、实例演示(如按年龄和姓名计数并填充缺失值),旨在帮助读者掌握数据透视操作。
本文详细介绍了如何使用pandas的pivot_table函数,包括参数解读、实例演示(如按年龄和姓名计数并填充缺失值),旨在帮助读者掌握数据透视操作。
1.获取帮助信息
import pandas as pd
df_1 = pd.read_excel('stu.xls')
help(df_1.pivot_table)2.函数
pivot_table(values=None, index=None, columns=None, aggfunc='mean', fill_value=None, margins=False, dropna=True, margins_name='All', observed=False, sort=True)
3.参数
index : 原表的表头名称。解释:透视表的第一列(透视表每一行的表头)
columns :原表的表头名称。解释:透视表的第一行(透视表每一列的表头)
values:原表的表头名称。解释:透视表内容,以哪列的数据为准。
aggfunc : 聚合函数,默认为平均值
np.sum() //求和;
np.prod() //所有元素相乘;
np.mean() //平均值;
np.std() //标准差;
np.var() //方差;
np.median() //中数;
np.power() //幂运算;
np.sqrt() //开方;
np.min() //最小值;
np.max() //最大值;
np.argmin() //最小值的下标;
np.argmax() //最大值的下标;
np.inf //无穷大;
np.exp(10) //以e为底的指数;
np.log(10) //对数
fill_value : 空缺数据,设置填充内容
margins : 是否添加行列的总计
dropna : 默认为True,如果列的所有值都是NaN,将不作为计算列,False时,被保留
margins_name : 汇总行列的名称,默认为All
observed : 是否显示观测值
sort : 结果是否排序4.案例

import pandas as pd
import numpy as np
df_1 = pd.read_excel('stu.xls')
#aggfunc='count' 计数
df_1_r = pd.pivot_table(df_1, index='年龄', columns='姓名', values='分数', aggfunc='count', margins=True,
margins_name='总计', fill_value=0)
df_1_r.to_excel('1.xlsx')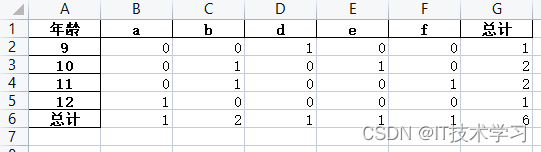


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









