




目录
引言:一张图改变 AI 发展轨迹?ImageNet 的传奇诞生
1.1 起源:李飞飞团队的 “野心”—— 让计算机 “看懂” 世界
1.2 核心规模:一组数据看懂 ImageNet 的 “体量”
1.4 ImageNet 与 ILSVRC:数据集与挑战赛的 “双向奔赴”
二、ImageNet 的核心价值:为什么它能引爆深度学习革命?
3.1 2012 年:AlexNet—— 深度学习的 “破冰者”
3.2 2013 年:ZFNet—— 优化网络结构的 “先行者”
3.3 2014 年:GoogLeNet—— 深度与宽度的 “平衡术”
3.4 2015 年:ResNet—— 突破 “深度诅咒” 的里程碑
四、实战:用 PyTorch 玩转 ImageNet(从加载数据到迁移学习)
4.2 实战 1:用预训练模型做 ImageNet 图像分类(直接运行)
4.3 实战 2:迁移学习 —— 用 ImageNet 预训练模型微调自己的数据集
Q3:为什么我的模型用 ImageNet 预训练后性能不好?

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言:一张图改变 AI 发展轨迹?ImageNet 的传奇诞生

如果你是 AI / 计算机视觉领域的开发者,哪怕是新手,也一定听过 ImageNet 的名字。但你可能不知道:这个看似 “只是一堆图片” 的数据集,曾直接引爆了深度学习的革命,让计算机视觉从 “人工设计特征” 的黑暗时代,一跃进入 “端到端学习” 的黄金期。
2012 年之前,计算机视觉领域的主流技术是 SIFT、HOG 等手工设计特征,图像分类准确率长期卡在 70% 左右,甚至不如三岁小孩的识别能力。而 2012 年的 ImageNet 挑战赛(ILSVRC)上,AlexNet 凭借 ImageNet 数据集训练,一举将 Top-5 错误率降到 16%,碾压所有传统方法,震惊了整个学术界。
从此,深度学习成为计算机视觉的绝对主流,ResNet、VGG、MobileNet 等经典模型相继诞生,人脸识别、自动驾驶、图像生成等应用遍地开花 —— 而这一切的起点,正是 ImageNet。
本文会竭力讲清 ImageNet 的来龙去脉:从它的诞生初衷、核心特点,到如何影响深度学习发展,再到普通人如何用 ImageNet 做实战开发。不管你是刚入门的 AI 新手,还是想夯实基础的开发者,读完这篇,你都能彻底搞懂 ImageNet 的价值与应用,还能亲手跑通 PyTorch 实战代码。
一、ImageNet 是什么?不止是 “图片合集”

1.1 起源:李飞飞团队的 “野心”—— 让计算机 “看懂” 世界
ImageNet 的诞生,源于斯坦福大学李飞飞团队的一个朴素愿望:让计算机像人类一样,具备识别和理解图像的能力。
2007 年,李飞飞团队发现了一个关键问题:当时的计算机视觉研究,缺乏大规模、高质量的标注图像数据集。传统数据集(如 MNIST、CIFAR-10)只有几千到几万张图,类别少(10-100 类),无法支撑复杂模型的训练 —— 就像让一个孩子只看 10 张动物图片,却要求他认识所有物种,显然不现实。
为了解决这个问题,李飞飞团队启动了 ImageNet 项目,目标是:构建一个覆盖人类生活中常见类别的、大规模、高质量的图像数据集,为计算机视觉研究提供 “燃料”。
这个项目耗时 5 年,最终在 2012 年正式发布,包含 1400 万张标注图像,覆盖 2 万多个类别 —— 相当于给计算机准备了一个 “图像图书馆”,让它能像人类一样,通过大量 “阅读” 学会识别不同事物。
1.2 核心规模:一组数据看懂 ImageNet 的 “体量”
ImageNet 的 “大”,不止是数量多,更在于覆盖范围广、标注质量高。关键数据如下(截至 2024 年公开数据):
| 维度 | 具体信息 |
|---|---|
| 总图像数量 | 约 1400 万张,其中 1200 万张有明确类别标注,500 万张有边界框标注(目标检测) |
| 类别数量 | 21841 个类别(ImageNet-21K 全量),常用子集 ILSVRC-2012 包含 1000 个类别 |
| 标注类型 | 图像分类标注(每张图对应 1 个主类别)、目标检测标注(边界框 + 类别) |
| 图像来源 | 互联网公开爬取(如 Flickr、搜索引擎),经人工筛选和标注 |
| 数据格式 | JPEG 格式,图像分辨率不一(从几百 × 几百到几千 × 几千) |
举个直观的类比:
- ImageNet 的 1000 类子集(ILSVRC-2012),涵盖了日常生活中几乎所有常见事物:动物(猫、狗、老虎等)、植物(玫瑰、大树等)、交通工具(汽车、飞机等)、日常用品(手机、杯子等)、场景(沙漠、森林等);
- 每个类别平均有 1000 张图像,比如 “猫” 这个类别,包含不同品种(波斯猫、橘猫等)、不同姿态(站立、卧躺等)、不同场景(室内、户外等)的图像,确保模型能学习到全面的特征。
1.3 为什么 ImageNet 如此特殊?3 个核心特点
ImageNet 能成为深度学习的 “催化剂”,绝非偶然,它的 3 个核心特点,完美契合了深度神经网络的训练需求:
1.3.1 规模足够大:解决 “数据饥饿” 问题
深度神经网络是 “数据驱动” 的 —— 模型层数越多、参数越多,需要的训练数据就越多。比如 AlexNet 有 6000 万个参数,若用传统的 CIFAR-10(10 万张图)训练,必然会过拟合(模型 “死记硬背” 训练数据,无法泛化)。
而 ImageNet 的 1400 万张图像,给了深度模型足够的 “学习素材”,让模型能从海量数据中学习到图像的通用特征(如边缘、纹理、形状),而非个别图像的细节,从而具备强大的泛化能力。
1.3.2 标注质量高:人工标注 + 严格质控
数据集的价值不仅在于 “量”,更在于 “质”。ImageNet 的标注流程极其严格:
- 图像筛选:先通过算法过滤低质量、重复的图像,确保每张图都清晰、有明确主体;
- 人工标注:雇佣全球数千名标注员(主要是亚马逊 Mechanical Turk 平台),按照 WordNet 的分类体系给图像贴标签;
- 质量控制:采用 “多轮校验”—— 同一图像由 3 名标注员标注,若结果不一致,交给专家仲裁,确保标注准确率超过 95%。
高质量的标注,让模型能 “学对东西”—— 不会因为标注错误而学到错误的特征,这是模型性能的基础。
1.3.3 类别分布均衡 + 场景多样化
ImageNet 的类别分布相对均衡,每个类别都有足够多的样本,避免模型偏向少数类别;同时,图像的场景、光照、角度多样化,比如 “狗” 的图像包含白天、黑夜、室内、户外等不同场景,让模型能适应真实世界的复杂环境。
这种 “多样化” 的训练数据,让模型学到的特征更通用 —— 比如训练出的模型,不仅能识别 ImageNet 中的 “猫”,还能识别现实生活中从未见过的猫的图像。
1.4 ImageNet 与 ILSVRC:数据集与挑战赛的 “双向奔赴”
很多人会混淆 ImageNet 和 ILSVRC,其实两者是 “数据集” 与 “应用场景” 的关系:
- ImageNet:是基础数据集,包含 21841 个类别,1400 万张图像;
- ILSVRC(ImageNet Large Scale Visual Recognition Challenge):是基于 ImageNet 子集的国际挑战赛,始于 2010 年,每年举办一次,直到 2017 年停止。
ILSVRC 选用了 ImageNet 中 1000 个常见类别(每个类别约 1000 张图),总数据量约 120 万张,分为训练集(128 万张)、验证集(5 万张)、测试集(10 万张)。
挑战赛的核心任务包括:
- 图像分类(Image Classification):判断图像属于 1000 类中的哪一类;
- 目标检测(Object Detection):检测图像中多个目标的位置(边界框)和类别;
- 图像定位(Image Localization):定位图像中主要目标的位置。
ILSVRC 的意义重大:它为全球研究者提供了统一的评估标准,让不同模型可以公平对比,直接推动了深度学习模型的快速迭代 ——AlexNet、VGG、GoogLeNet、ResNet 等经典模型,都是在 ILSVRC 中脱颖而出的。
二、ImageNet 的核心价值:为什么它能引爆深度学习革命?
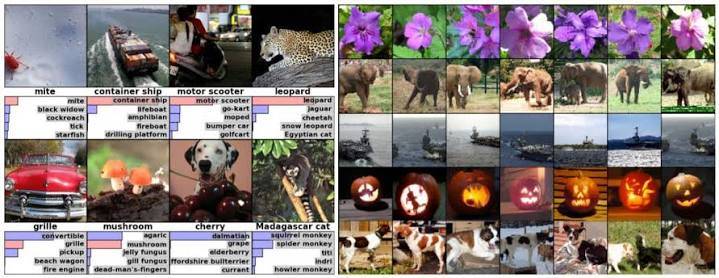
ImageNet 的价值,远不止是 “一个大的图像数据集”—— 它直接解决了计算机视觉领域的核心痛点,为深度学习的爆发提供了必要条件。
2.1 打破 “手工设计特征” 的瓶颈
在深度学习之前,计算机视觉的核心是 “手工设计特征”—— 研究者需要凭借经验,设计复杂的算法提取图像的特征(如边缘、纹理、颜色直方图),再用 SVM、决策树等传统机器学习算法分类。
这种方法的痛点很明显:
- 特征设计依赖人工经验,难度大、效率低;
- 手工特征的表达能力有限,无法捕捉图像的复杂语义(如 “猫的眼神”“狗的姿态”);
- 泛化能力差,在不同场景下性能急剧下降。
而 ImageNet 的出现,让 “端到端学习” 成为可能 —— 深度模型可以直接从海量标注图像中,自动学习到从低级到高级的特征:
- 低级特征:边缘、纹理、颜色;
- 中级特征:形状、局部结构(如猫的耳朵、狗的鼻子);
- 高级特征:语义信息(如 “这是一只猫”“这是一辆汽车”)。
这种 “自动特征学习”,彻底摆脱了对人工经验的依赖,让模型的性能实现了质的飞跃。
2.2 验证了深度学习的有效性,推动技术普及
在 2012 年之前,深度学习还处于 “小众研究” 阶段,很多人质疑它的实用性 —— 认为它参数太多、训练困难,不如传统方法稳定。
而 AlexNet 在 ILSVRC 2012 中的表现,给了深度学习最有力的证明:
- Top-5 错误率 16%,比第二名(传统方法)低 10 个百分点;
- 这种 “碾压式” 的优势,让整个学术界和工业界意识到深度学习的潜力;
- 越来越多的研究者开始转向深度学习,相关论文、框架、工具呈爆炸式增长。
可以说,ImageNet 就像 “深度学习的试金石”,用实实在在的性能数据,让深度学习从 “学术冷门” 变成了 “工业主流”。
2.3 奠定迁移学习的基础
迁移学习是当前 AI 应用的核心技术之一 —— 用在大规模数据集(如 ImageNet)上训练好的模型,微调后应用于小规模数据集的任务(如自己的图像分类任务)。
而 ImageNet 正是迁移学习的 “最佳基石”:
- 基于 ImageNet 训练的预训练模型(如 ResNet、VGG),已经学习到了图像的通用特征,这些特征在大多数视觉任务中都有用;
- 开发者不需要从零开始训练模型,只需用少量数据微调,就能达到很高的性能,大幅降低了 AI 应用的门槛。
比如你想做一个 “区分苹果和橘子” 的分类器,不需要收集 100 万张图像,只需用 ResNet 的预训练模型,微调 1000 张苹果和橘子的图像,就能达到 95% 以上的准确率 —— 这一切都要归功于 ImageNet 预训练模型的强大能力。
2.4 催生了深度学习框架的发展
训练深度模型需要强大的计算资源和高效的框架支持。ImageNet 的大规模训练需求,直接推动了深度学习框架的迭代:
- 为了训练 AlexNet,研究者开发了 CUDA 加速的卷积神经网络实现,让 GPU 能高效处理图像数据;
- 后续的 TensorFlow、PyTorch、Caffe 等框架,都针对 ImageNet 这类大规模数据集的训练做了优化,让普通开发者也能用上深度学习。
可以说,ImageNet 和深度学习框架是 “相互成就”——ImageNet 的需求推动了框架的发展,而框架的普及又让更多人能利用 ImageNet 做研究和应用。
三、ILSVRC 历年回顾:那些改变 AI 的经典模型

ILSVRC 挑战赛的历年结果,就是一部深度学习的发展简史。每一年的冠军模型,都带来了关键技术突破,至今仍影响着 AI 领域。
3.1 2012 年:AlexNet—— 深度学习的 “破冰者”
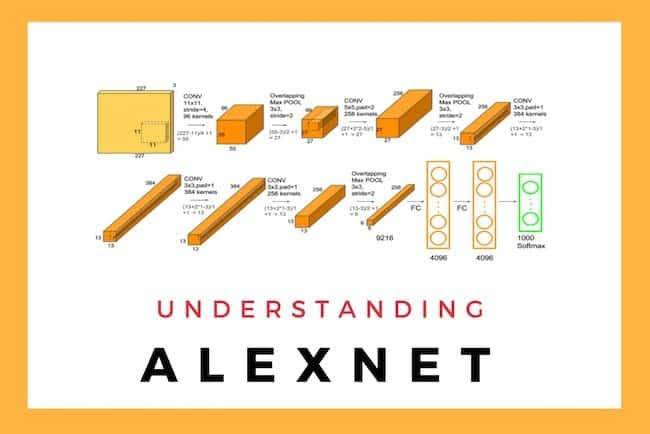
-
冠军团队:多伦多大学(Hinton 团队,Alex Krizhevsky 等人);
-
Top-5 错误率:16.4%(第二名传统方法为 26.2%);
-
核心创新:
- 首次将 ReLU 激活函数用于深度网络,解决了 Sigmoid 函数的梯度消失问题;
- 采用 Dropout 正则化,防止模型过拟合;
- 使用重叠池化(Overlapping Pooling),提升特征提取能力;
- 采用数据增强(镜像、裁剪、颜色抖动),充分利用训练数据;
- 首次大规模使用 GPU 训练深度网络,将训练时间从数月缩短到数天。
-
历史意义:AlexNet 的成功,标志着深度学习正式进入计算机视觉领域,开启了深度学习的黄金时代。
3.2 2013 年:ZFNet—— 优化网络结构的 “先行者”
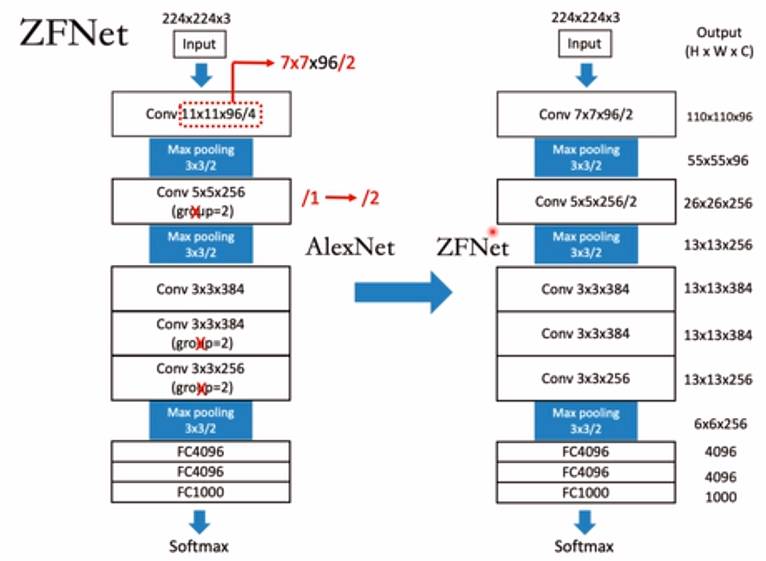
-
冠军团队:纽约大学(Matthew Zeiler 等人);
-
Top-5 错误率:11.7%;
-
核心创新:
- 通过可视化技术,分析了卷积层的特征提取过程,让人们第一次 “看到” 模型学到了什么;
- 优化了网络的卷积核大小和步长,让模型能更好地捕捉图像细节。
-
历史意义:证明了网络结构的细节优化能显著提升性能,同时推动了 “模型可视化” 的研究,帮助开发者理解模型的工作原理。
3.3 2014 年:GoogLeNet—— 深度与宽度的 “平衡术”
-
冠军团队:Google;
-
Top-5 错误率:6.67%;
-
核心创新:
- 提出 Inception 模块,在同一层中使用不同大小的卷积核(1×1、3×3、5×5),同时捕捉局部和全局特征;
- 引入 1×1 卷积核,减少参数数量,降低计算成本;
- 取消全连接层,用平均池化替代,进一步减少参数。
-
历史意义:GoogLeNet 展示了 “多尺度特征融合” 的有效性,同时解决了深度网络参数过多、计算量大的问题,为后续高效网络的设计提供了思路。
3.4 2015 年:ResNet—— 突破 “深度诅咒” 的里程碑
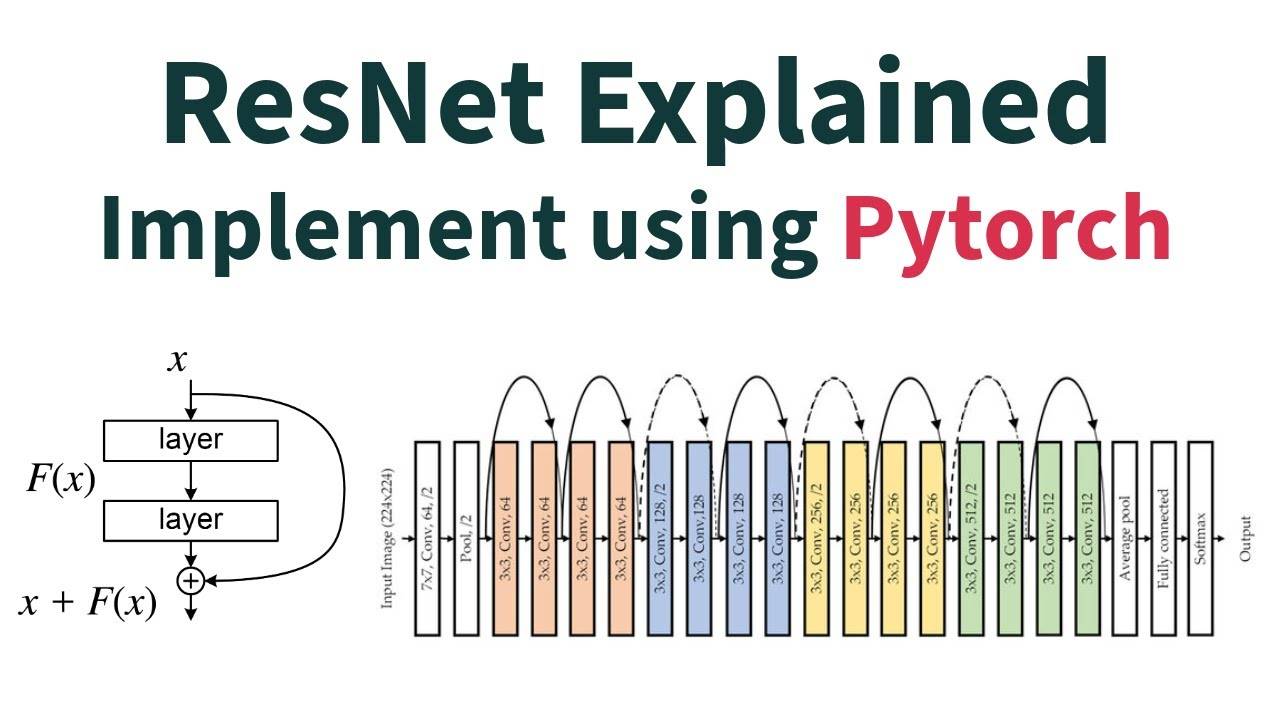
-
冠军团队:微软亚洲研究院(何恺明等人);
-
Top-5 错误率:3.57%(首次超过人类水平,人类在该任务上的错误率约 5%);
-
核心创新:
- 提出残差连接(Residual Connection),通过 “跳层连接” 解决深层网络的梯度消失问题,让网络能训练到 152 层(之前的模型大多在 20-30 层);
- 简化网络结构,使用批量归一化(Batch Normalization)加速训练。
-
历史意义:ResNet 彻底打破了 “网络越深性能越好,但训练越难” 的困境,证明了深层网络的巨大潜力,至今仍是最常用的预训练模型之一。
3.5 2016-2017 年:极致优化与任务扩展
- 2016 年冠军:SENet(Top-5 错误率 2.99%),提出注意力机制(Squeeze-and-Excitation),让模型能自动关注重要特征;
- 2017 年冠军:Mask R-CNN(扩展到实例分割任务),将目标检测和分割结合,进一步拓展了计算机视觉的应用场景。
2017 年后,ILSVRC 停止举办,因为深度学习在图像分类任务上的性能已经接近理论极限,研究者开始转向更复杂的任务(如自动驾驶、图像生成、多模态学习)。但 ImageNet 和 ILSVRC 留下的技术遗产,仍在持续影响着 AI 领域的发展。
四、实战:用 PyTorch 玩转 ImageNet(从加载数据到迁移学习)
了解了 ImageNet 的理论后,我们来做实战 —— 用 PyTorch 加载 ImageNet 数据集、使用预训练模型做图像分类、通过迁移学习微调模型。所有代码都可直接运行,新手也能轻松上手。
4.1 准备工作:环境配置与数据集获取
4.1.1 环境配置
首先安装必要的库:
pip install torch torchvision pillow matplotlib numpy
- 推荐 Python 版本:3.8-3.10;
- PyTorch 版本:1.10 以上(支持 torchvision 的 ImageNet 加载)。
4.1.2 数据集获取
ImageNet 的完整数据集需要在官网申请授权(免费用于学术研究),申请通过后可下载 ILSVRC-2012 子集(约 138GB)。
如果只是想快速体验,不需要下载完整数据集 ——torchvision 提供了预训练模型,我们可以用这些模型直接做推理,或用自己的小规模数据集做迁移学习。
4.2 实战 1:用预训练模型做 ImageNet 图像分类(直接运行)
我们用 PyTorch 的torchvision.models加载预训练的 ResNet50 模型,对一张图像进行分类,预测它属于 ImageNet 的 1000 类中的哪一类。
4.2.1 完整代码
import torch
import torchvision.models as models
import torchvision.transforms as transforms
from PIL import Image
import matplotlib.pyplot as plt
# 1. 加载预训练模型(ResNet50,在ImageNet上训练好的)
model = models.resnet50(pretrained=True)
model.eval() # 切换到评估模式,关闭Dropout等
# 2. 图像预处理:必须和训练时的预处理一致
# ImageNet的预训练模型要求输入图像尺寸为224×224,归一化参数固定
transform = transforms.Compose([
transforms.Resize(256), # 先缩放至256×256
transforms.CenterCrop(224), # 中心裁剪到224×224
transforms.ToTensor(), # 转换为Tensor(0-1)
transforms.Normalize(
mean=[0.485, 0.456, 0.406], # ImageNet的均值
std=[0.229, 0.224, 0.225] # ImageNet的标准差
)
])
# 3. 加载并预处理图像(替换为你的图像路径)
image_path = "dog.jpg" # 示例:一张狗的图像
image = Image.open(image_path).convert("RGB") # 确保是RGB图像
plt.imshow(image)
plt.title("输入图像")
plt.axis("off")
plt.show()
# 预处理图像
input_tensor = transform(image).unsqueeze(0) # 增加batch维度(模型要求输入为[batch, channel, H, W])
# 4. 模型推理(禁用梯度计算,加快速度)
with torch.no_grad():
output = model(input_tensor)
# 5. 解析结果:获取Top-5概率最高的类别
# 加载ImageNet的1000类标签(从torchvision获取)
from torchvision.datasets import ImageNet
# 注意:ImageNet标签需要手动下载,这里提供简化版标签(前10类示例,完整标签见文末)
# 完整标签可从:https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt 下载
imagenet_classes = [
"tench, Tinca tinca",
"goldfish, Carassius auratus",
"great white shark, white shark, man-eater, man-eating shark, Carcharodon carcharias",
"tiger shark, Galeocerdo cuvieri",
"hammerhead, hammerhead shark",
"electric ray, crampfish, numbfish, torpedo",
"stingray",
"cock",
"hen",
"ostrich, Struthio camelus",
# ... 此处省略其他990类,完整标签见文末链接
]
# 获取Top-5索引
_, top5_indices = torch.topk(output, 5, dim=1)
top5_indices = top5_indices.squeeze().numpy()
# 计算概率(softmax)
probabilities = torch.softmax(output, dim=1).squeeze().numpy()
# 打印结果
print("Top-5预测结果:")
for i, idx in enumerate(top5_indices):
print(f"{i+1}. 类别:{imagenet_classes[idx]},概率:{probabilities[idx]:.4f}")
4.2.2 代码解释
- 预训练模型:
models.resnet50(pretrained=True)加载在 ImageNet 上训练好的 ResNet50 模型,包含 1200 万张图像的训练经验; - 图像预处理:必须和训练时一致,否则模型性能会大幅下降 ——ImageNet 预训练模型的输入要求是 224×224 的 RGB 图像,且经过特定的归一化;
- 推理过程:用
torch.no_grad()禁用梯度计算,加快推理速度;torch.topk获取概率最高的 5 个类别; - 结果解析:通过 softmax 将模型输出转换为概率,结合 ImageNet 的类别标签,得到最终预测结果。
4.2.3 运行效果
如果输入一张狗的图像,输出可能如下:
Top-5预测结果:
1. 类别:golden retriever,概率:0.9876
2. 类别:Labrador retriever,概率:0.0089
3. 类别:Chesapeake Bay retriever,概率:0.0021
4. 类别:Irish setter,概率:0.0008
5. 类别:flat-coated retriever,概率:0.0004
4.3 实战 2:迁移学习 —— 用 ImageNet 预训练模型微调自己的数据集
实际应用中,我们很少直接使用 ImageNet 的 1000 类分类,更多是用预训练模型做迁移学习,解决自己的任务(如区分 “猫和狗”“苹果和橘子”)。
下面以 “猫和狗分类” 为例,展示如何用 ResNet50 的预训练模型做迁移学习。
4.3.1 数据集准备
假设我们的数据集结构如下(可从Kaggle 猫和狗数据集下载):
data/
├── train/
│ ├── cat/
│ │ ├── cat001.jpg
│ │ ├── cat002.jpg
│ │ └── ...
│ └── dog/
│ ├── dog001.jpg
│ ├── dog002.jpg
│ └── ...
└── val/
├── cat/
│ ├── cat001.jpg
│ └── ...
└── dog/
├── dog001.jpg
└── ...
- 训练集:各 1000 张猫和狗的图像;
- 验证集:各 200 张猫和狗的图像。
4.3.2 迁移学习完整代码
import torch
import torch.nn as nn
import torch.optim as optim
from torch.utils.data import DataLoader
import torchvision.models as models
import torchvision.transforms as transforms
from torchvision.datasets import ImageFolder
import matplotlib.pyplot as plt
import numpy as np
# 1. 数据预处理
# 训练集:数据增强(提升泛化能力)
train_transform = transforms.Compose([
transforms.Resize(256),
transforms.RandomResizedCrop(224), # 随机裁剪(数据增强)
transforms.RandomHorizontalFlip(), # 随机水平翻转
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 验证集:无数据增强,只做常规预处理
val_transform = transforms.Compose([
transforms.Resize(256),
transforms.CenterCrop(224),
transforms.ToTensor(),
transforms.Normalize(mean=[0.485, 0.456, 0.406], std=[0.229, 0.224, 0.225])
])
# 加载数据集(ImageFolder自动根据文件夹名称分类)
train_dataset = ImageFolder(root="data/train", transform=train_transform)
val_dataset = ImageFolder(root="data/val", transform=val_transform)
# 创建DataLoader(批量加载数据)
train_loader = DataLoader(train_dataset, batch_size=32, shuffle=True, num_workers=4)
val_loader = DataLoader(val_dataset, batch_size=32, shuffle=False, num_workers=4)
# 类别名称(ImageFolder自动生成,0=cat,1=dog)
class_names = train_dataset.classes
print(f"类别:{class_names}")
# 2. 加载预训练模型并修改输出层
# 加载ResNet50预训练模型
model = models.resnet50(pretrained=True)
# 冻结特征提取层(只训练分类头)
for param in model.parameters():
param.requires_grad = False # 冻结所有参数
# 修改输出层:ImageNet是1000类,我们的任务是2类
num_ftrs = model.fc.in_features # 获取全连接层的输入特征数
model.fc = nn.Linear(num_ftrs, 2) # 替换为2类输出
# 3. 设置训练参数
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 移到GPU(如果有)
criterion = nn.CrossEntropyLoss() # 交叉熵损失(分类任务)
optimizer = optim.SGD(model.fc.parameters(), lr=0.001, momentum=0.9) # 只优化分类头
# 4. 训练函数
def train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs=10):
train_losses = []
val_losses = []
val_accs = []
for epoch in range(num_epochs):
# 训练阶段
model.train()
running_loss = 0.0
for inputs, labels in train_loader:
inputs = inputs.to(device)
labels = labels.to(device)
# 前向传播
outputs = model(inputs)
loss = criterion(outputs, labels)
# 反向传播+优化
optimizer.zero_grad()
loss.backward()
optimizer.step()
running_loss += loss.item() * inputs.size(0)
# 计算训练集平均损失
epoch_train_loss = running_loss / len(train_loader.dataset)
train_losses.append(epoch_train_loss)
# 验证阶段
model.eval()
running_val_loss = 0.0
correct = 0
total = 0
with torch.no_grad():
for inputs, labels in val_loader:
inputs = inputs.to(device)
labels = labels.to(device)
outputs = model(inputs)
loss = criterion(outputs, labels)
running_val_loss += loss.item() * inputs.size(0)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 计算验证集平均损失和准确率
epoch_val_loss = running_val_loss / len(val_loader.dataset)
epoch_val_acc = correct / total
val_losses.append(epoch_val_loss)
val_accs.append(epoch_val_acc)
# 打印日志
print(f"Epoch {epoch+1}/{num_epochs}")
print(f"Train Loss: {epoch_train_loss:.4f} | Val Loss: {epoch_val_loss:.4f} | Val Acc: {epoch_val_acc:.4f}")
# 绘制训练曲线
plt.figure(figsize=(12, 4))
# 损失曲线
plt.subplot(1, 2, 1)
plt.plot(train_losses, label="Train Loss")
plt.plot(val_losses, label="Val Loss")
plt.xlabel("Epoch")
plt.ylabel("Loss")
plt.legend()
plt.title("Loss Curve")
# 准确率曲线
plt.subplot(1, 2, 2)
plt.plot(val_accs, label="Val Accuracy", color="orange")
plt.xlabel("Epoch")
plt.ylabel("Accuracy")
plt.legend()
plt.title("Accuracy Curve")
plt.tight_layout()
plt.show()
return model
# 5. 开始训练(10个epoch)
model = train_model(model, train_loader, val_loader, criterion, optimizer, num_epochs=10)
# 6. 模型推理示例
def predict_image(image_path, model, transform, class_names):
image = Image.open(image_path).convert("RGB")
plt.imshow(image)
plt.axis("off")
plt.show()
input_tensor = transform(image).unsqueeze(0).to(device)
model.eval()
with torch.no_grad():
output = model(input_tensor)
_, predicted = torch.max(output, 1)
probability = torch.softmax(output, dim=1).squeeze()[predicted.item()].item()
print(f"预测结果:{class_names[predicted.item()]},概率:{probability:.4f}")
# 测试一张猫的图像
predict_image("data/val/cat/cat001.jpg", model, val_transform, class_names)
# 测试一张狗的图像
predict_image("data/val/dog/dog001.jpg", model, val_transform, class_names)
4.3.3 迁移学习核心逻辑
- 冻结特征提取层:预训练模型的前几层已经学习到了通用特征(如边缘、纹理),这些特征对我们的任务也有用,所以冻结这些层的参数,只训练最后一层全连接层;
- 修改输出层:将原来的 1000 类输出,替换为我们任务的 2 类输出(猫 / 狗);
- 数据增强:训练集使用随机裁剪、水平翻转等数据增强技术,提升模型的泛化能力;
- 微调优化:只优化分类头的参数,训练速度快,且不需要大量数据就能达到高准确率。
4.3.4 预期效果
经过 10 个 epoch 的训练,验证集准确率通常能达到 95% 以上 —— 这比从零开始训练模型(准确率可能只有 70% 左右)高出很多,充分体现了 ImageNet 预训练模型的价值。
五、ImageNet 的影响与后续发展

ImageNet 不仅改变了计算机视觉,还对整个 AI 领域产生了深远影响,同时也催生了更多更先进的数据集和技术。
5.1 对 AI 领域的三大影响
5.1.1 确立 “数据驱动” 的 AI 发展路线
ImageNet 的成功,让 “大规模高质量数据集 + 深度学习模型” 成为 AI 发展的主流路线 —— 后续的自然语言处理(如 BERT 用 BookCorpus 和 Wikipedia 数据集)、语音识别(如 LibriSpeech 数据集),都沿用了这一思路。
5.1.2 推动 AI 工业化落地
基于 ImageNet 预训练模型的迁移学习,大幅降低了 AI 应用的门槛 —— 企业不需要投入大量资源收集和标注数据,就能快速开发出高质量的视觉应用(如安防监控、医疗影像分析、智能驾驶)。
5.1.3 促进跨领域研究
ImageNet 的技术成果,不仅用于图像分类,还被拓展到目标检测、语义分割、图像生成等多个任务,甚至影响了自然语言处理、强化学习等领域的发展(如注意力机制、预训练 - 微调范式)。
5.2 ImageNet 的局限性与后续数据集
尽管 ImageNet 成就巨大,但它也存在一些局限性:
- 类别偏向:主要覆盖英文世界的常见类别,对小众类别、非英文场景的覆盖不足;
- 标注单一:主要是类别标注和简单的边界框标注,缺乏更细粒度的标注(如物体的姿态、属性);
- 数据过时:部分图像是 2010 年前后爬取的,可能不符合当前的视觉场景;
- 缺乏多样性:图像主要来自互联网,对特殊场景(如极端天气、罕见视角)的覆盖不足。
为了弥补这些不足,后续出现了很多更先进的数据集:
- COCO(Common Objects in Context):支持目标检测、实例分割、人体关键点检测等多个任务,标注更丰富;
- OpenImages:规模更大(900 万张图像,6000 多个类别),标注类型更多(边界框、分割、关系标注);
- ImageNet-21K:ImageNet 的全量版本,包含 21841 个类别,适合更细粒度的分类任务;
- WebLi:谷歌推出的大规模无标注图像数据集,通过自监督学习训练模型,减少对人工标注的依赖。
这些数据集在 ImageNet 的基础上,进一步推动了计算机视觉的发展,但 ImageNet 作为 “开创者” 的地位,至今无人能替代。
5.3 未来趋势:从有监督到无监督 / 自监督学习
ImageNet 是有监督学习的典范,但人工标注大规模数据集的成本极高(ImageNet 的标注成本超过 1000 万美元)。未来的发展趋势是无监督学习和自监督学习—— 不需要人工标注,通过模型自动从海量无标注数据中学习特征。
比如:
- 谷歌的 SimCLR、MoCo 等自监督学习模型,在无标注图像上训练,再微调后性能接近有监督模型;
- OpenAI 的 CLIP 模型,通过图像和文本的配对数据,实现跨模态学习,不需要专门的图像分类标注。
但这些技术的发展,依然离不开 ImageNet 奠定的基础 —— 正是 ImageNet 证明了 “大规模数据能训练出强泛化能力的模型”,才推动了后续无监督学习的探索。
六、常见问题解答(FAQ)

Q1:普通人如何获取 ImageNet 数据集?
A1:ImageNet 的完整数据集需要在官网申请授权,用于学术研究是免费的,商业用途需要付费。如果只是想体验预训练模型,不需要下载完整数据集 ——torchvision、TensorFlow Hub 等平台提供了预训练模型,可直接用于推理和迁移学习。
Q2:ImageNet 的 1000 类标签在哪里获取?
A2:完整的 1000 类标签可从 PyTorch 的官方仓库下载:https://raw.githubusercontent.com/pytorch/hub/master/imagenet_classes.txt。
Q3:为什么我的模型用 ImageNet 预训练后性能不好?
A3:可能的原因:
- 图像预处理不符合预训练模型的要求(如尺寸不对、归一化参数错误);
- 数据集与 ImageNet 的分布差异太大(如医疗影像、卫星图像),需要更多的微调数据;
- 冻结 / 微调的层选择不当(如复杂任务需要微调更多层);
- 模型选择不合适(如小数据集用过大的模型容易过拟合)。
Q4:ImageNet 还适合现在的研究和开发吗?
A4:对于基础研究(如模型结构创新),ImageNet 仍可作为基准数据集;对于实际应用,更推荐使用 COCO、OpenImages 等更丰富的数据集,或结合自监督学习模型。但 ImageNet 的预训练模型依然是迁移学习的常用选择,尤其是在数据量较小的场景。
七、总结:ImageNet 的传奇与启示

ImageNet 的传奇,不仅在于它是一个 “大的图像数据集”,更在于它引爆了深度学习革命,改变了 AI 领域的发展轨迹。它的成功,给我们带来了三个重要启示:
- 数据是 AI 的燃料:没有大规模高质量的数据,再复杂的模型也无法发挥作用;
- 开源共享推动进步:ImageNet 免费向学术界开放,让全球研究者能基于同一数据集做研究,加速了技术迭代;
- 范式创新的力量:ImageNet 与深度学习的结合,开创了 “预训练 - 微调” 的范式,这种范式至今仍是 AI 应用的核心。
对于 AI 开发者来说,ImageNet 不仅是一个数据集,更是一个 “技术标杆”—— 它让我们明白,AI 的进步离不开数据、模型和算法的协同发展。如今,虽然有了更先进的数据集和技术,但 ImageNet 所代表的 “用数据驱动 AI 进步” 的理念,依然是我们探索 AI 未来的重要指引。
如果你是刚入门的 AI 新手,建议从 ImageNet 的预训练模型开始,亲手跑通实战代码,感受深度学习的魅力;如果你是资深开发者,不妨回头看看 ImageNet 的发展历程,或许能从中获得新的灵感。



















 7222
7222

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









