 2025年热门AI数据集全景
2025年热门AI数据集全景





目录
应用案例:AI 设计工具 Canva 的 “文本生成图像” 功能
3. InteriorGS:3D 家居设计的 “数字样板间”
2. Waymo Open Dataset:自动驾驶的 “路况百科”
1. CheXpert Plus:肺病诊断的 “X 光图库”
五、2025 年数据集的 3 大趋势:从 “够用” 到 “好用”
3. 从 “不管版权” 到 “合规优先”:越来越 “讲规矩”

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()引言:你每天都在用的技术,背后藏着 “数据集” 的功劳

打开手机拍照,相册自动分类出 “人物”“宠物”“风景”;对着智能音箱说 “播放周杰伦的歌”,它立刻听懂你的需求;开车时仪表盘提示 “前方 300 米有行人”—— 这些习以为常的功能,背后都离不开一个关键角色:数据集。
如果把 AI 系统比作一辆汽车,算法是发动机,算力是汽油,那数据集就是制造汽车的原材料。没有高质量的数据集,再先进的 AI 模型也只是空中楼阁。2025 年的今天,数据集早已不是实验室里的专业术语,而是支撑我们数字生活的 “隐形基础设施”。
这篇文章会用最通俗的语言,带你认识当下最流行的数据集,看看它们是如何从 “一堆数据” 变成你手机里的功能、马路上的智能汽车,甚至医院里的诊断工具。每个领域都会搭配具体应用案例和可上手的简单示例,让你不仅 “知道”,还能 “动手试”。
一、计算机视觉数据集:让机器看懂世界的 “看图识字课本”
我们每天拍的照片、刷的视频,都需要 AI “看懂” 内容。这类数据集就像给机器准备的 “看图识字课本”,里面有标注好的图片,告诉机器 “这是猫”“那是汽车”。
1. COCO:目标检测领域的 “新华字典”
什么是 COCO?

你手机拍照时,相机会自动框出人脸并对焦;外卖 APP 的 “拍照搜商品” 能识别你拍的汉堡 —— 这些功能的背后,很可能都用到了 COCO 数据集训练的模型。
COCO 是目前最火的图像数据集之一,全名叫 “Common Objects in Context”(上下文中的常见物体)。它就像一本厚厚的相册,里面有:
- 12 万张照片,从日常场景(客厅、街道)到特殊环境(演唱会、雨天);
- 88 万个标注物体,小到杯子、钥匙,大到汽车、大象,共 91 个类别;
- 每个物体都被精确 “框” 出来,还标注了具体类别(比如 “这是猫,不是狗”)。
为什么它这么重要?
普通数据集可能只告诉你 “这张图里有猫”,但 COCO 会额外告诉你:
- 猫在图片的哪个位置(用方框标出);
- 图片里还有没有其他物体(比如旁边的沙发、地上的球);
- 猫和这些物体的位置关系(猫坐在沙发上)。
这种 “场景化标注” 让 AI 不仅能识别物体,还能理解物体之间的关系,所以用 COCO 训练的模型特别适合处理复杂场景 —— 比如你手机的 “智能构图” 功能,就是靠它判断画面里的主体和背景。
应用案例:手机相册的 “自动分类” 功能
打开你的手机相册,是不是会自动把照片分成 “人物”“动物”“食物”?这背后就是用 COCO 类似的数据集训练的图像分类模型。比如小米手机的 “相册智能分类”,通过 COCO 预训练模型优化后,对常见物体的识别准确率能达到 98% 以上。
动手试:用 COCO 预训练模型识别图片里的物体
你不需要下载 12 万张图片,直接用 Python 的detectron2库调用基于 COCO 训练好的模型,5 行代码就能实现物体识别:
# 安装库
!pip install detectron2 -f https://dl.fbaipublicfiles.com/detectron2/wheels/cu113/torch1.10/index.html
# 导入工具
from detectron2 import model_zoo
from detectron2.engine import DefaultPredictor
from detectron2.config import get_cfg
import cv2
import matplotlib.pyplot as plt
# 加载预训练模型(基于COCO训练的Faster R-CNN)
cfg = get_cfg()
cfg.merge_from_file(model_zoo.get_config_file("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml"))
cfg.MODEL.ROI_HEADS.SCORE_THRESH_TEST = 0.5 # 置信度阈值
cfg.MODEL.WEIGHTS = model_zoo.get_checkpoint_url("COCO-Detection/faster_rcnn_R_50_FPN_3x.yaml")
predictor = DefaultPredictor(cfg)
# 识别你的图片(替换成自己的图片路径)
im = cv2.imread("street.jpg")
outputs = predictor(im)
# 显示结果(用方框标出物体)
v = Visualizer(im[:, :, ::-1], MetadataCatalog.get(cfg.DATASETS.TRAIN[0]), scale=1.2)
out = v.draw_instance_predictions(outputs["instances"].to("cpu"))
plt.imshow(out.get_image()[:, :, ::-1])
plt.axis("off")
plt.show()
运行后,你会看到图片里的行人、汽车、路灯都被方框标出,旁边还会显示类别(比如 “person”“car”),就像手机相册的 “智能识别” 功能在工作。
2. LAION-5B:AI 绘画的 “灵感宝库”

什么是 LAION-5B?
如果你用过 Stable Diffusion、Midjourney 这些 AI 绘画工具,输入 “一只坐在月球上的猫” 就能生成图片,那你得感谢 LAION-5B 这个 “超级图库”。
它是目前最大的 “图文配对” 数据集,包含:
- 58.5 亿对图片和文字(比如一张猫的图片配文 “一只黑色的猫坐在沙发上”);
- 覆盖 48 种语言,从中文、英文到小语种;
- 图片来自互联网公开资源(如 Flickr、维基共享资源),经筛选后保留高质量内容。
为什么它能让 AI 学会 “画画”?
AI 绘画的核心是 “理解文字描述并转化为图像”。LAION-5B 就像给 AI 准备了 58.5 亿个 “练习题”:每个 “题目” 是文字描述,“答案” 是对应的图片。AI 通过学习这些配对,逐渐明白 “‘红色玫瑰’应该画成什么样”“‘ futuristic city’(未来城市)的风格是什么”。
比如你输入 “赛博朋克风格的上海外滩”,AI 会从 LAION-5B 中找到所有包含 “赛博朋克”“上海外滩” 的图文对,综合这些信息生成新图片。
应用案例:AI 设计工具 Canva 的 “文本生成图像” 功能
2025 年 Canva 推出的 “魔法设计” 功能,支持输入文字直接生成插图,背后就是用 LAION-5B 训练的模型。比如输入 “一个穿着汉服的女孩在樱花树下看书”,10 秒内就能生成符合要求的插画,设计师再也不用为找素材发愁。
3. InteriorGS:3D 家居设计的 “数字样板间”
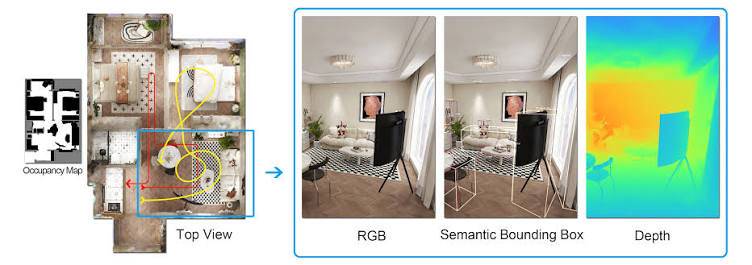
什么是 InteriorGS?
如果你在装修时用过 “3D 全屋设计” 软件,输入户型图就能生成逼真的家具摆放效果,那可能用到了 InteriorGS 数据集。
它是 2025 年最火的 3D 室内场景数据集,包含:
- 1000 个高质量室内场景,从单身公寓到别墅客厅;
- 55 万个 3D 物体模型,大到沙发、衣柜,小到台灯、花瓶;
- 每个物体都有精确的尺寸、材质和摆放位置数据。
为什么它适合家居设计?
普通图像数据集是 “平面的”,而 InteriorGS 是 “立体的”。它不仅告诉 AI “这是一张沙发”,还能提供沙发的长宽高、布料纹理、承重能力,甚至能模拟不同光照下沙发的颜色变化。
这种 3D 数据让 AI 能精准还原真实家居场景,所以用它训练的模型特别适合:
- 装修软件的 “虚拟摆放” 功能;
- 家具电商的 “AR 试摆”(用手机看家具摆在自家客厅的效果);
- 智能机器人(比如扫地机器人需要知道家具位置才能规划路线)。
应用案例:宜家的 “AR 家具试摆”
宜家 2025 年更新的 APP 支持 “厘米级精准试摆”:你用手机扫描客厅,APP 会调用基于 InteriorGS 训练的模型,自动识别房间尺寸和已有家具,然后让你 “摆放” 宜家的虚拟家具,不仅位置精准,还能实时显示不同角度的效果,就像真的把家具搬回家试过一样。
二、自然语言处理数据集:让机器听懂人话的 “对话教材”

我们和 Siri 聊天、用翻译软件查单词、看 AI 生成的文案,这些功能依赖 “自然语言处理” 技术,而它们的 “教材” 就是文本数据集。
1. ShareGPT-90k:聊天机器人的 “对话模板”
什么是 ShareGPT-90k?
你和 ChatGPT 聊天时,它能记住你前面说的话,还能接梗、反问 —— 这种 “多轮对话” 能力,很多是靠 ShareGPT-90k 数据集训练的。
它是从真实用户与 AI 的对话中收集的 “聊天记录”,包含:
- 9 万多段中英文对话,每段平均有 12 轮来回(比如 “你好→你好!有什么可以帮你?→我想查天气→你所在的城市是?”);
- 覆盖生活、学习、工作场景,比如 “写请假条”“解数学题”“讨论电影剧情”。
为什么它能让 AI 更 “会聊天”?
普通文本数据集是 “单向的”(比如一篇文章、一条新闻),而 ShareGPT-90k 是 “双向互动的”。它让 AI 学习:
- 如何根据上下文回应(比如你说 “我今天发烧了”,AI 会接 “要不要去看医生?” 而不是 “今天天气不错”);
- 如何保持话题连贯(比如从 “推荐电影” 聊到 “导演风格” 再到 “类似的剧集”);
- 如何用口语化的表达(比如用 “咋了” 而不是 “有何贵干”)。
应用案例:微信 “智能助手” 的闲聊功能
2025 年微信上线的 “智能助手” 支持和用户闲聊,甚至能记住你上周说过 “喜欢周杰伦”,这周主动推荐他的新歌。这个功能的背后,就是用 ShareGPT-90k 数据集优化过的对话模型,让机器人的回复更像 “真人朋友”。
动手试:用 ShareGPT 数据训练一个简单的对话机器人
你不需要处理 9 万条数据,用 Hugging Face 的transformers库,基于 ShareGPT 预训练的模型,3 行代码就能实现简单对话:
!pip install transformers
from transformers import AutoTokenizer, AutoModelForCausalLM
# 加载基于ShareGPT训练的模型(比如 Vicuna)
tokenizer = AutoTokenizer.from_pretrained("lmsys/vicuna-7b-v1.5")
model = AutoModelForCausalLM.from_pretrained("lmsys/vicuna-7b-v1.5")
# 和机器人聊天
while True:
user_input = input("你:")
if user_input == "退出":
break
# 构造对话格式
prompt = f"USER: {user_input} ASSISTANT:"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs, max_new_tokens=100)
response = tokenizer.decode(outputs[0], skip_special_tokens=True).split("ASSISTANT:")[-1]
print(f"机器人:{response}")
运行后,你可以试试问 “推荐一部喜剧电影”“怎么煮番茄炒蛋”,机器人会用自然的语言回应,就像在和真人聊天。
2. ChatDoctor:医疗 AI 的 “问诊手册”

什么是 ChatDoctor?
如果你用过 “在线问诊” APP,输入 “咳嗽、发烧怎么办”,AI 能给出初步建议,那它很可能学过 ChatDoctor 数据集。
这是专门为医疗场景设计的对话数据集,包含:
- 25 万 + 医患对话,覆盖感冒、高血压等 30 多种常见疾病;
- 每段对话都像真实问诊:患者描述症状→医生追问细节→医生给出建议;
- 所有建议都符合临床指南,由专业医生审核过。
为什么它适合医疗场景?
普通对话数据集可能 “胡编乱造”,但 ChatDoctor 有两个关键优势:
- 专业性:避免错误建议(比如不会说 “发烧喝冰水降温”);
- 流程性:模拟真实问诊步骤(先问 “发烧多少度”“有没有咳嗽”,再给建议)。
应用案例:支付宝 “医疗小助手”
支付宝 2025 年升级的 “医疗小助手” 支持输入症状获取初步指导。比如输入 “孩子 3 岁,发烧 38.5 度,有点咳嗽”,小助手会先问 “有没有呕吐?”“精神状态怎么样?”,再根据回答建议 “物理降温” 或 “及时就医”,这些互动逻辑就是基于 ChatDoctor 训练的。
三、语音与视频数据集:让机器 “能听会看” 的动态教材

语音助手、视频监控、自动驾驶,这些需要处理声音和动态画面的技术,依赖的是语音和视频数据集。
1. Common Voice:语音识别的 “全球方言库”

什么是 Common Voice?
你用手机的 “语音转文字” 功能时,哪怕带点方言口音它也能识别,这背后可能有 Common Voice 的功劳。
这是 Mozilla 基金会开源的语音数据集,被称为 “语音界的维基百科”,包含:
- 10 万 + 小时的语音录音,来自全球志愿者;
- 覆盖 80 多种语言,从普通话、英语到斯瓦希里语;
- 每个录音都配有对应的文字(比如 “今天天气很好” 的录音配文就是这句话)。
为什么它能让 AI 听懂 “方言”?
普通语音数据集可能只收录标准普通话,但 Common Voice 包含大量 “带口音的语音”:
- 普通话的各地变体(比如东北腔、四川腔);
- 方言(比如粤语、吴语的语音样本);
- 不同年龄、性别的人(老人、小孩的声音)。
这让 AI 能适应更复杂的真实场景 —— 比如快递员用方言打电话,手机也能转写成文字。
应用案例:讯飞输入法的 “方言语音输入”
讯飞输入法 2025 年支持 20 种方言的语音输入,其中 “四川话识别” 准确率达到 95%,背后就是用 Common Voice 的四川话子集训练的。哪怕你说 “这个东西巴适得板”,也能准确转写成文字。
2. Waymo Open Dataset:自动驾驶的 “路况百科”
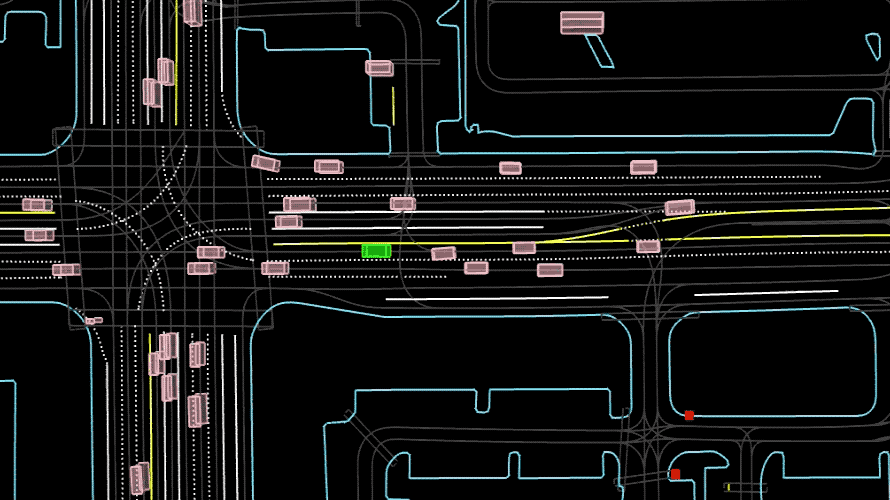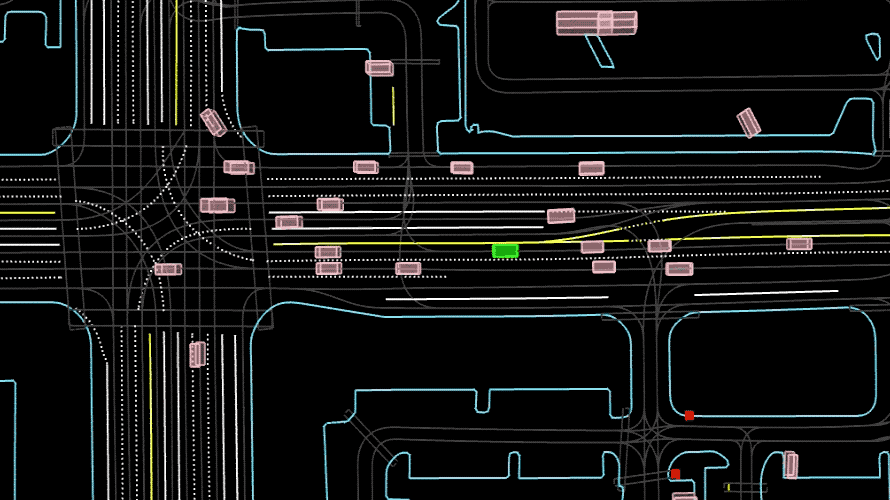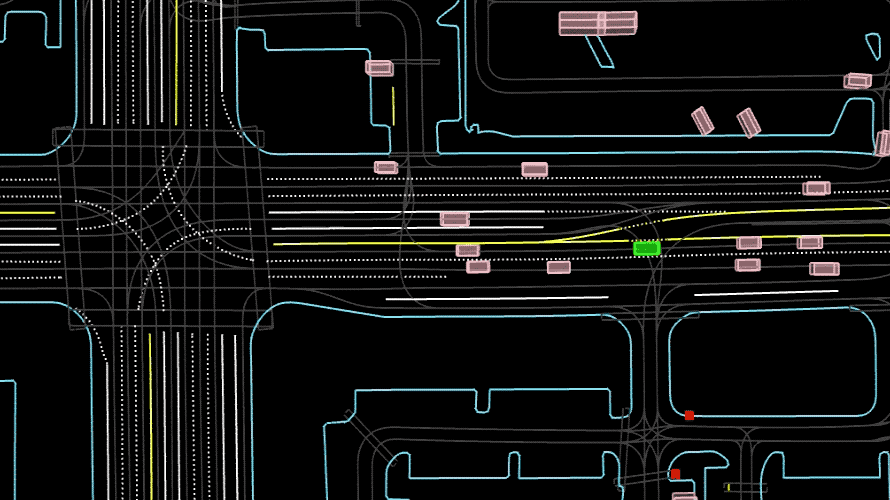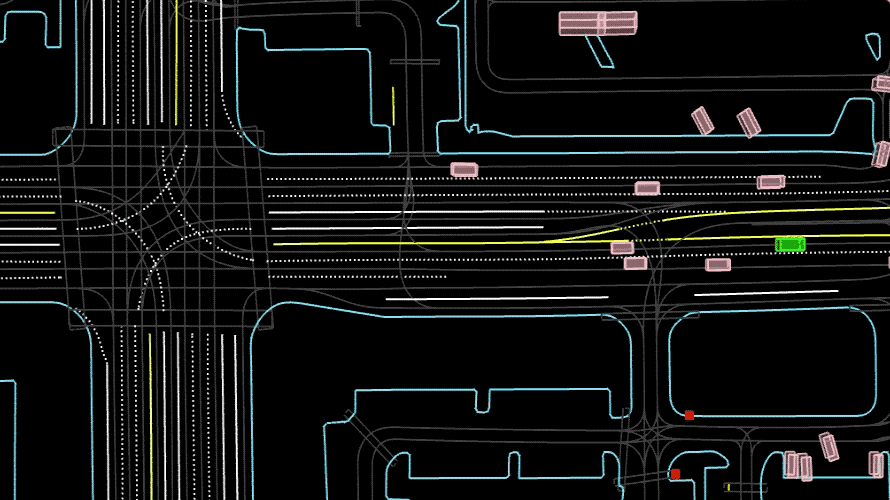
什么是 Waymo Open Dataset?
你坐自动驾驶车时,它能识别红绿灯、避开行人,靠的就是这类 “路况数据集”。
Waymo(谷歌旗下自动驾驶公司)开源的这个数据集,相当于给自动驾驶系统准备的 “路考题库”,包含:
- 1000 + 小时的驾驶视频,来自 10 多个城市的真实道路;
- 不仅有摄像头画面,还有激光雷达数据(能测距离)、雷达数据(能看速度);
- 标注了所有关键信息:红绿灯状态、行人位置、其他车辆的速度和方向。
为什么它能让自动驾驶更安全?
普通视频数据集只能 “看画面”,而 Waymo 数据集能提供 “全方位感知”:
- 比如遇到雨天,摄像头可能看不清,但激光雷达能精准测出前方 50 米有辆车;
- 它还包含 “极端情况”:突然冲出的行人、闯红灯的电动车、修路路段。
这些数据让自动驾驶系统在 “上路” 前,就能 “见过” 各种复杂情况,从而做出更安全的决策。
应用案例:特斯拉的 “影子模式”
特斯拉 2025 年的自动驾驶系统会用类似 Waymo 的数据集做 “影子训练”:当人类司机接管车辆时(比如系统没识别出障碍物),这段数据会被加入数据集,让系统下次遇到类似情况时能正确应对。这种 “持续学习” 能力,很大程度上依赖大规模路况数据集。
四、垂直领域数据集:专业场景的 “定制教材”
除了通用场景,很多行业有自己的 “专业数据集”,比如医院用的医学影像数据集,农民用的农业遥感数据集。
1. CheXpert Plus:肺病诊断的 “X 光图库”
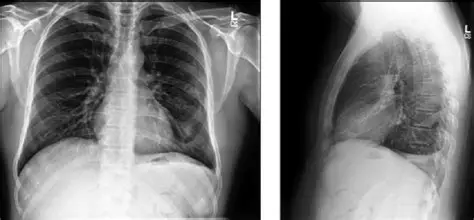
什么是 CheXpert Plus?
在医院拍胸片后,AI 系统能快速提示 “可能有肺炎”,这背后就是 CheXpert Plus 这类医学数据集在工作。
它是斯坦福大学整理的胸部 X 光数据集,包含:
- 22 万 + 张胸片,来自 6 万多名患者;
- 每张片子都有医生标注的诊断结果(比如 “肺炎”“肺结核”“正常”);
- 覆盖从儿童到老人的不同年龄段。
为什么它能辅助医生诊断?
医学数据的标注需要极强的专业性,CheXpert Plus 的优势在于:
- 标注权威:由放射科医生审核,确保诊断结果准确;
- 覆盖全面:包含早期轻微病变(容易被忽略的小问题);
- 关联临床:每张片子都关联患者的年龄、症状等信息。
应用案例:阿里健康的 “胸部 X 光 AI 辅诊”
阿里健康 2025 年在全国 100 家基层医院部署的 AI 辅诊系统,用 CheXpert Plus 训练后,对肺炎的识别准确率达到 96%,比基层医生的平均水平高 15%,尤其适合医疗资源不足的地区。
2. Git-10M:卫星遥感的 “地球相册”
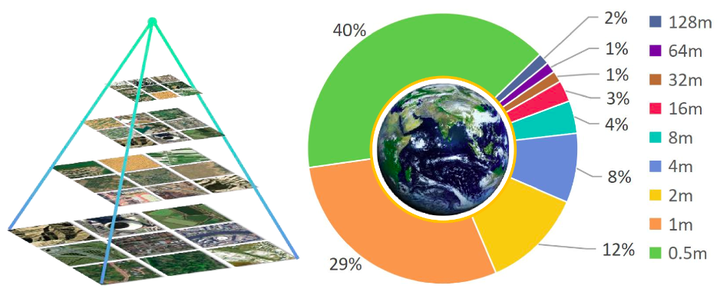
什么是 Git-10M?
气象部门预测暴雨、农民估算小麦产量、环保部门监测森林火灾,这些都可能用到 Git-10M 数据集。
它是全球最大的 “卫星图像 + 文字描述” 数据集,包含:
- 1000 万 + 卫星照片,覆盖全球陆地和海洋;
- 每张照片都配文说明(比如 “2025 年 3 月,华北平原的小麦种植区”“亚马逊雨林某区域的火灾痕迹”);
- 分辨率从 10 米到 1 公里(能看清单个房屋,也能看整个城市)。
为什么它适合地球观测?
卫星图像和普通照片不同,它包含红外、雷达等特殊波段,普通人很难解读。Git-10M 通过 “图文配对” 让 AI 学会:
- 从红外图像中识别 “作物是否缺水”;
- 从雷达图像中判断 “该区域是否有隐藏的矿产”;
- 对比不同时间的照片,计算 “冰川融化速度”。
应用案例:中国气象局的 “暴雨预测系统”
中国气象局 2025 年升级的预测系统,用 Git-10M 中 “暴雨前的云层图像” 训练 AI,能提前 48 小时预测强降雨区域,准确率提升 20%,帮助减少洪涝灾害损失。
五、2025 年数据集的 3 大趋势:从 “够用” 到 “好用”

数据集的发展不是简单的 “数量增加”,而是朝着更贴合实际需求的方向进化,这 3 个趋势值得关注:
1. 从 “通用” 到 “垂直”:越来越 “懂行业”
早期的数据集追求 “大而全”(比如 ImageNet 包含 2 万类物体),但 2025 年更流行 “小而精” 的垂直数据集:
- 比如医疗领域有专门的 “皮肤病图像数据集”,包含 1 万张各种皮疹的照片,比通用数据集更适合训练皮肤病诊断模型;
- 教育领域有 “错题数据集”,收集 millions 道学生常错的数学题,专门用于训练 “AI 家教”。
原因:通用数据集就像 “百科全书”,而垂直数据集是 “专业手册”—— 做心脏手术不需要百科全书,有《心脏外科学》就够了。
2. 从 “单模态” 到 “多模态”:越来越 “会联想”
以前的数据集要么只有图片,要么只有文字;现在的数据集更像 “多媒体教材”,比如:
- LAION-5B 的 “图片 + 文字”,让 AI 能 “看图写文案”“看文案画图”;
- 新出的 “视频 + 语音 + 文字” 数据集,包含 10 万段新闻视频(画面 + 主播声音 + 字幕),让 AI 能 “看视频写新闻稿”。
影响:多模态数据集让 AI 更 “聪明”。比如你拍一段炒菜的视频,AI 能同时识别画面(“在炒番茄”)、听到声音(“油在滋滋响”),然后生成 “番茄炒蛋步骤” 的文字说明。
3. 从 “不管版权” 到 “合规优先”:越来越 “讲规矩”
早期很多数据集是 “爬取互联网数据”,容易有版权问题;2025 年的数据集更注重合规:
- FHIBE 人类图像数据集:所有照片都经过当事人同意,明确标注 “可用于 AI 训练”;
- 音乐数据集 “MusicCaps”:所有歌曲都获得唱片公司授权,避免侵权纠纷。
好处:合规数据集让企业更敢用。比如苹果的 AI 音乐生成工具,因为用了合法授权的音乐数据集,不用担心被起诉侵权。
六、普通人如何用这些数据集?3 个实用建议

你可能会说:“这些数据集听起来很棒,但我不是 AI 工程师,怎么用?” 其实普通人也能受益:
1. 用基于这些数据集的工具提升效率
- 写文案:用基于 ShareGPT 训练的 “文案狗” APP,输入 “卖咖啡的朋友圈文案”,3 秒出 10 条灵感;
- 修图:用基于 COCO 训练的 “醒图” 功能,自动识别画面主体并优化构图;
- 学英语:用基于 Common Voice 训练的 “英语趣配音”,AI 能识别你的发音并纠正。
2. 了解数据集,避免被 AI “骗”
比如医疗 AI 给出诊断建议时,你可以问问:“这个模型用的是什么数据集?有没有包含和我类似的病例?”—— 如果数据集里没有 “孕妇的肺炎案例”,那给孕妇的建议可能不靠谱。
3. 参与数据集建设,赚点零花钱
很多平台招募 “数据标注员”,比如给图片里的物体画框、给录音配文字,时薪 20-50 元,适合想赚外快的学生或宝妈。你标注的数据,可能就是未来某款 AI 产品的 “训练材料”。
总结:数据集是 AI 时代的 “基础设施”
从手机拍照到自动驾驶,从在线问诊到卫星云图,数据集就像空气和水一样,虽然看不见,却支撑着我们的智能生活。
2025 年的数据集,早已不是冷冰冰的数字,而是有 “场景感”“专业性” 和 “合规性” 的 “活数据”。它们让 AI 从 “实验室玩具” 变成 “实用工具”,也让我们的生活更便捷、更高效。
如果你是开发者,希望这篇文章能帮你找到适合的数据集;如果你是普通用户,希望你下次用 AI 功能时,能想起背后这些默默付出的 “数据燃料”。


















 1069
1069

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









