




目录
前言:为什么 PyTorch 是深度学习新手的 “最优解”?
一、PyTorch 核心概念:用 “快递系统” 理解 3 大核心组件
1.2 计算图(Computation Graph):动态搭建的 “快递分拣流水线”
二、环境搭建:3 步搞定 PyTorch(Windows/Linux/Mac 通用)
2.1 步骤 1:安装 Anaconda(Python 环境管理器)
2.3 步骤 3:安装 PyTorch(CPU/GPU 版本)
三、实战 1:线性回归 —— 用 PyTorch 预测房价(最简单的深度学习模型)
四、实战 2:CNN 图像分类 —— 用 PyTorch 识别 CIFAR-10 数据集(小图片识别)
五、实战 3:RNN 文本生成 —— 用 PyTorch 写唐诗(序列数据处理)
六、PyTorch 新手避坑指南:10 个高频错误及解决方案
6.7 坑 7:数据加载时num_workers导致错误(Windows)
6.10 坑 10:张量无法转换为 NumPy(GPU 张量)

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()前言:为什么 PyTorch 是深度学习新手的 “最优解”?
你可能听说过 “深度学习框架” 这个词,但面对 TensorFlow、PyTorch、Keras 这些名字时,是不是像面对满桌菜系不知从何下筷?如果让我给新手推荐,PyTorch 一定是首选 —— 它就像深度学习界的 “Python”,简洁、灵活、易上手,连 Facebook(现 Meta)、特斯拉、斯坦福大学都在用它做科研和生产。

为什么说 PyTorch 比其他框架更适合新手?用一个比喻就能明白:
- 如果你把深度学习模型比作 “乐高机器人”,PyTorch 就是 “散装乐高积木”—— 你可以边拼边改,哪里不合适当场拆开重搭,调试起来一目了然;
- 而有些框架更像 “预制板建筑”—— 必须先画好完整图纸(定义计算图),才能动工,中途改设计要从头再来,新手很容易被劝退。
这篇博客我会用 “大白话 + 可运行代码” 的方式,从 0 开始带大家掌握 PyTorch:从环境搭建到核心概念,再到实战项目(房价预测、图像分类、唐诗生成),全程无晦涩公式,无学术黑话。哪怕你是刚学 Python 的新手,跟着敲代码也能快速入门,干货密度拉满!
一、PyTorch 核心概念:用 “快递系统” 理解 3 大核心组件

在写代码之前,我们先搞懂 PyTorch 的 3 个核心概念 ——张量(Tensor)、计算图(Computation Graph)、模型(Module)。用 “快递系统” 来类比,瞬间就能明白:
1.1 张量(Tensor):深度学习的 “数据快递箱”
张量是 PyTorch 中存储和处理数据的基本单位,简单说就是 “带 GPU 加速的多维数组”。就像快递系统中不同规格的箱子:
- 标量(0 维张量):单个数值,比如 “1kg 苹果”,对应 Python 的 int/float。示例:
torch.tensor(3.14) - 向量(1 维张量):一串数据,比如 “苹果 1kg、香蕉 2kg、橙子 3kg”,对应 Python 列表。示例:
torch.tensor([1, 2, 3]) - 矩阵(2 维张量):表格状数据,比如 “3 个客户的订单明细”,对应 Excel 表格。示例:
torch.tensor([[1,2], [3,4], [5,6]]) - 高阶张量(3 维及以上):多层表格叠起来,比如 “10 天内每天 3 个客户的订单”,常用在图像(高度 × 宽度 × 通道)、文本(句子数 × 单词数 × 词向量)等场景。示例:
torch.tensor([[[1,2], [3,4]], [[5,6], [7,8]]])
实战代码:创建和操作张量PyTorch 的张量操作和 NumPy 几乎一致,新手可以无缝迁移知识:
import torch
import numpy as np
# 1. 创建张量(支持从Python数据、NumPy数组转换)
# 标量
scalar = torch.tensor(3.14)
print("标量张量:", scalar) # 输出:tensor(3.1400)
print("标量值:", scalar.item()) # 转Python值:3.14
# 向量
vector = torch.tensor([1, 2, 3, 4])
print("向量张量:", vector) # 输出:tensor([1, 2, 3, 4])
print("向量形状:", vector.shape) # 输出:torch.Size([4])
# 矩阵
matrix = torch.tensor([[1, 2], [3, 4], [5, 6]])
print("矩阵张量:\n", matrix)
# 输出:
# tensor([[1, 2],
# [3, 4],
# [5, 6]])
# 2. 张量运算(加减乘除、矩阵乘法等)
a = torch.tensor([1, 2])
b = torch.tensor([3, 4])
print("a + b:", a + b) # 输出:tensor([4, 6])
print("a * b:", a * b) # 输出:tensor([3, 8])
# 矩阵乘法(用@符号或torch.matmul)
matrix1 = torch.tensor([[1, 2], [3, 4]])
matrix2 = torch.tensor([[5, 6], [7, 8]])
print("矩阵乘法:\n", matrix1 @ matrix2)
# 输出:
# tensor([[19, 22],
# [43, 50]])
# 3. 张量变形(reshape)
tensor = torch.tensor([1, 2, 3, 4, 5, 6])
reshaped = tensor.reshape(2, 3) # 改成2行3列
print("变形后:\n", reshaped)
# 输出:
# tensor([[1, 2, 3],
# [4, 5, 6]])
# 4. GPU加速(关键优势!)
if torch.cuda.is_available():
# 把张量移到GPU
tensor_gpu = tensor.to('cuda')
print("GPU张量:", tensor_gpu) # 输出带device='cuda:0'
else:
print("未检测到GPU,使用CPU")
核心优势:PyTorch 张量支持无缝切换 CPU/GPU,只需to('cuda')就能利用显卡加速计算,这对训练大型模型至关重要。
1.2 计算图(Computation Graph):动态搭建的 “快递分拣流水线”
计算图是 PyTorch 的 “灵魂”,它记录了张量的所有运算步骤,就像快递系统的 “分拣流水线”:包裹(张量)从起点进入,经过扫描、分类、运输(运算),最终送到终点(输出结果)。
但 PyTorch 的计算图是 “动态的”—— 你可以边运行边修改流水线。比如发现某个分拣步骤错了,不用停掉整条线,直接在运行中调整,这就是 PyTorch 比其他框架更灵活的原因。
最核心的应用:自动求导(反向传播)深度学习的本质是 “通过数据调整模型参数”,而参数调整依赖 “梯度”(导数)。PyTorch 的计算图能自动计算梯度,省去手动推导公式的麻烦:
# 自动求导示例:y = 2x² + 3x + 1,求x=1时的导数dy/dx
x = torch.tensor(1.0, requires_grad=True) # requires_grad=True:需要计算梯度
y = 2 * x**2 + 3 * x + 1
# 反向传播:计算梯度(从y往x回溯)
y.backward()
# 查看x的梯度(dy/dx = 4x + 3,x=1时结果为7)
print("x的梯度:", x.grad) # 输出:tensor(7.0)
这个过程就像:知道快递最终送达时间(y),自动反推每个分拣步骤(x 的运算)对时间的影响(梯度),从而优化流程 —— 这就是模型 “学习” 的核心逻辑。
1.3 模型(Module):可组装的 “智能分拣机”
如果说计算图是 “流水线步骤”,那模型就是 “完整的智能分拣机”—— 把一系列运算(线性层、卷积层等)组装起来,形成一个能 “输入数据、输出结果” 的完整系统。
PyTorch 用torch.nn.Module来定义模型,就像用乐高积木拼机器,每个积木是一个 “层”(如Linear线性层、Conv2d卷积层):
import torch.nn as nn
# 定义一个简单的线性回归模型(预测y = wx + b)
class LinearRegression(nn.Module):
def __init__(self):
super().__init__() # 初始化父类
# 定义一个线性层:1个输入特征→1个输出特征
self.linear = nn.Linear(in_features=1, out_features=1)
# 定义前向传播(数据流动路径)
def forward(self, x):
return self.linear(x) # 输入x经过线性层处理
# 创建模型实例
model = LinearRegression()
print("模型结构:", model)
# 输出:
# LinearRegression(
# (linear): Linear(in_features=1, out_features=1, bias=True)
# )
# 测试模型:输入一个x,看是否能输出预测值
x_test = torch.tensor([[2.0]]) # 注意形状:(样本数, 特征数)
y_pred = model(x_test)
print("预测结果:", y_pred) # 输出随机值(未训练的模型参数随机)
forward方法是模型的 “核心”,定义了数据如何从输入经过各层处理,最终输出结果。训练模型的过程,就是调整这些层的参数(如w和b),让预测结果越来越接近真实值。
二、环境搭建:3 步搞定 PyTorch(Windows/Linux/Mac 通用)

PyTorch 的环境搭建比想象中简单,推荐用 “Anaconda+PyTorch” 组合,避免版本冲突,新手也能轻松搞定。
2.1 步骤 1:安装 Anaconda(Python 环境管理器)
Anaconda 就像 “Python 环境的虚拟机”,能为不同项目创建独立环境,避免依赖冲突。
- 下载地址:https://www.anaconda.com/products/distribution
- 安装步骤:
- 双击安装包,勾选 “Add Anaconda3 to my PATH environment variable”(自动配置环境变量);
- 其他默认下一步,等待安装完成。
验证安装:打开终端(Windows 用 “Anaconda Prompt”),输入conda --version,输出版本号(如conda 23.11.0)说明成功。
2.2 步骤 2:创建并激活 PyTorch 环境
# 1. 创建环境(Python 3.9,环境名pytorch-env)
conda create -n pytorch-env python=3.9
# 2. 激活环境(Windows)
conda activate pytorch-env
# 2. 激活环境(Linux/Mac)
source activate pytorch-env
激活后终端前缀会显示(pytorch-env),表示当前在 PyTorch 环境中。
2.3 步骤 3:安装 PyTorch(CPU/GPU 版本)
PyTorch 分为 CPU 和 GPU 版本,按需选择:
- CPU 版本:适合新手、无独立显卡的电脑,安装简单;
- GPU 版本:需要 NVIDIA 显卡(支持 CUDA),训练速度比 CPU 快 10~100 倍。
安装方法(推荐官网生成命令)
- 打开 PyTorch 官网:https://pytorch.org/get-started/locally/
- 按自己的系统和需求选择:
- 系统(Windows/Linux/Mac);
- 安装方式(Pip);
- 计算平台(CPU 或 CUDA 版本,如 CUDA 11.8)。
- 复制生成的命令,在终端执行。
示例命令(CPU 版本,通用)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cpu
示例命令(GPU 版本,需 NVIDIA 显卡)
pip3 install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
2.4 验证安装成功
在终端输入python,进入 Python 环境,执行:
import torch
import torchvision
# 查看版本
print("PyTorch版本:", torch.__version__) # 输出如2.1.0
# 检查GPU是否可用
print("GPU是否可用:", torch.cuda.is_available()) # GPU版本输出True,CPU版本False
无报错且版本号正常,说明环境搭建成功!
三、实战 1:线性回归 —— 用 PyTorch 预测房价(最简单的深度学习模型)

线性回归是入门深度学习的 “Hello World”,核心是学习 “输入特征 x” 和 “输出值 y” 的线性关系(y = wx + b)。我们用 “房屋面积预测房价” 的场景实战,让模型学会根据面积估算价格。
3.1 场景说明
假设有一组数据:5 套房子的 “面积(平方米)” 和 “价格(万元)”,我们要搭建模型,根据面积预测房价。
| 房屋面积(x) | 房价(y) |
|---|---|
| 50 | 100 |
| 70 | 140 |
| 90 | 180 |
| 110 | 220 |
| 130 | 260 |
从数据能看出规律:房价≈面积 ×2(比如 50×2=100),模型需要 “学会” 这个关系。
3.2 完整代码实现
import torch
import torch.nn as nn
import numpy as np
import matplotlib.pyplot as plt
# ---------------------- 1. 准备数据 ----------------------
# 输入特征:房屋面积(5个样本,每个样本1个特征)
x = torch.tensor([[50.0], [70.0], [90.0], [110.0], [130.0]])
# 标签:房价(5个样本,每个样本1个标签)
y = torch.tensor([[100.0], [140.0], [180.0], [220.0], [260.0]])
# 可视化原始数据
plt.scatter(x.numpy(), y.numpy(), color='blue', label='真实数据')
plt.xlabel('房屋面积(平方米)')
plt.ylabel('房价(万元)')
plt.title('房屋面积与房价关系')
plt.legend()
plt.show()
# ---------------------- 2. 定义模型 ----------------------
class LinearRegressionModel(nn.Module):
def __init__(self):
super().__init__()
# 线性层:1个输入特征(面积)→1个输出特征(房价)
self.linear = nn.Linear(in_features=1, out_features=1)
def forward(self, x):
return self.linear(x) # 前向传播:x→线性层→输出
# 创建模型实例
model = LinearRegressionModel()
# ---------------------- 3. 定义损失函数和优化器 ----------------------
# 损失函数:均方误差(MSE),衡量预测值与真实值的差距
criterion = nn.MSELoss()
# 优化器:随机梯度下降(SGD),用于更新模型参数(w和b)
# lr=0.0001:学习率(步长,控制参数更新幅度)
optimizer = torch.optim.SGD(model.parameters(), lr=0.0001)
# ---------------------- 4. 训练模型 ----------------------
epochs = 10000 # 训练轮数(整个数据集训练10000次)
losses = [] # 记录每轮损失值
for epoch in range(epochs):
# 前向传播:用当前模型预测房价
y_pred = model(x)
# 计算损失(预测值与真实值的差距)
loss = criterion(y_pred, y)
losses.append(loss.item()) # 保存损失值
# 反向传播:计算梯度(自动求导)
optimizer.zero_grad() # 清空上一轮梯度(避免累积)
loss.backward() # 计算参数梯度
# 更新参数(w和b)
optimizer.step()
# 每1000轮打印一次损失
if (epoch + 1) % 1000 == 0:
print(f'轮数:{epoch+1}, 损失:{loss.item():.4f}')
# ---------------------- 5. 可视化训练过程 ----------------------
plt.plot(range(epochs), losses, color='red')
plt.xlabel('训练轮数')
plt.ylabel('损失值(MSE)')
plt.title('训练过程中损失的变化')
plt.show()
# ---------------------- 6. 查看模型学到的参数 ----------------------
# 线性层的参数:weight(w)和bias(b)
w = model.linear.weight.item()
b = model.linear.bias.item()
print(f'模型学到的参数:w={w:.2f}, b={b:.2f}')
print(f'预测公式:房价 = {w:.2f} × 面积 + {b:.2f}') # 接近 房价=2×面积+0
# ---------------------- 7. 模型预测 ----------------------
# 预测新数据:80平方米和150平方米的房价
x_new = torch.tensor([[80.0], [150.0]])
y_new_pred = model(x_new)
print(f'80平方米房价预测:{y_new_pred[0].item():.2f}万元(真实值约160万元)')
print(f'150平方米房价预测:{y_new_pred[1].item():.2f}万元(真实值约300万元)')
# 可视化预测结果(真实数据+预测直线)
x_range = torch.tensor([[40.0], [160.0]]) # 生成一系列面积值
y_range_pred = model(x_range)
plt.scatter(x.numpy(), y.numpy(), color='blue', label='真实数据')
plt.plot(x_range.numpy(), y_range_pred.detach().numpy(), 'r-', label='预测直线')
plt.scatter(x_new.numpy(), y_new_pred.detach().numpy(), color='green', s=100, label='新预测')
plt.xlabel('房屋面积(平方米)')
plt.ylabel('房价(万元)')
plt.title('房价预测:真实数据与模型预测')
plt.legend()
plt.show()
3.3 关键代码解析
- 数据准备:用
torch.tensor创建输入 x(面积)和标签 y(房价),注意形状必须是(样本数, 特征数)(如(5,1)); - 模型定义:继承
nn.Module,用nn.Linear定义线性层,forward方法指定数据流动路径; - 损失函数与优化器:
- 损失函数
MSELoss:计算预测值与真实值的平均平方差,值越小说明预测越准; - 优化器
SGD:通过梯度下降更新参数(w 和 b),lr(学习率)是关键超参数,太大可能跳过最优值,太小则训练慢;
- 损失函数
- 训练循环:核心是 “前向传播→计算损失→反向传播→更新参数” 四步,重复多轮直到损失足够小;
- 参数查看:训练后模型的
weight(w)接近 2,bias(b)接近 0,完美学到 “房价 = 2× 面积” 的规律。
3.4 新手踩坑点
- 数据形状错误:输入 x 必须是二维张量
(样本数, 特征数),如果写成[50,70,90](1 维)会报错,需用reshape(-1,1)转换; - 学习率设置:
lr=0.001可能导致损失震荡不下降,lr=0.00001则训练太慢,建议从0.0001开始尝试; - 梯度清零:
optimizer.zero_grad()必须在loss.backward()前调用,否则梯度会累积,导致参数更新混乱。
四、实战 2:CNN 图像分类 —— 用 PyTorch 识别 CIFAR-10 数据集(小图片识别)
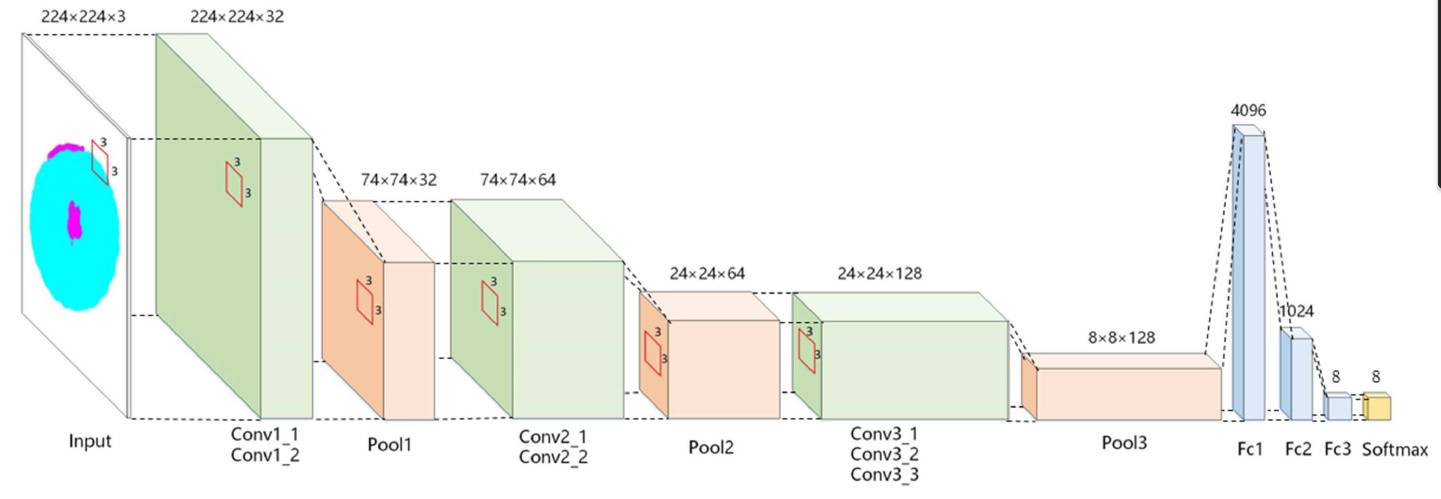
线性回归是 “数值预测”,而图像分类是 “类别预测”。我们用卷积神经网络(CNN) 识别 CIFAR-10 数据集(包含飞机、汽车、鸟等 10 类小图片),CNN 能自动提取图像特征(如边缘、纹理),是处理图像的 “神器”。
4.1 场景说明
CIFAR-10 数据集包含 60000 张 32×32 像素的彩色图片(3 通道:RGB),分为 10 类(每类 6000 张):['飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车']我们要搭建 CNN 模型,输入一张图片,输出它属于哪一类。
4.2 完整代码实现
import torch
import torch.nn as nn
import torch.optim as optim
import torchvision
import torchvision.transforms as transforms
import matplotlib.pyplot as plt
import numpy as np
# ---------------------- 1. 加载并预处理数据集 ----------------------
# 数据转换:将图片转为张量,并标准化(均值、标准差为ImageNet数据集的统计值)
transform = transforms.Compose([
transforms.ToTensor(), # 转为张量(0~1)
transforms.Normalize((0.5, 0.5, 0.5), (0.5, 0.5, 0.5)) # 标准化到[-1,1]
])
# 加载CIFAR-10训练集和测试集(自动下载到./data目录)
trainset = torchvision.datasets.CIFAR10(
root='./data', train=True, download=True, transform=transform
)
testset = torchvision.datasets.CIFAR10(
root='./data', train=False, download=True, transform=transform
)
# 数据加载器(批量加载数据,支持打乱顺序、多线程)
trainloader = torch.utils.data.DataLoader(
trainset, batch_size=64, shuffle=True, num_workers=2
)
testloader = torch.utils.data.DataLoader(
testset, batch_size=64, shuffle=False, num_workers=2
)
# 类别名称
classes = ('飞机', '汽车', '鸟', '猫', '鹿', '狗', '青蛙', '马', '船', '卡车')
# ---------------------- 2. 可视化训练集图片 ----------------------
def imshow(img):
img = img / 2 + 0.5 # 反标准化(从[-1,1]转回[0,1])
npimg = img.numpy()
plt.imshow(np.transpose(npimg, (1, 2, 0))) # 转换通道顺序(C×H×W→H×W×C)
plt.axis('off')
# 获取一批训练数据
dataiter = iter(trainloader)
images, labels = next(dataiter)
# 显示前6张图片
plt.figure(figsize=(10, 4))
for i in range(6):
plt.subplot(1, 6, i+1)
imshow(images[i])
plt.title(classes[labels[i]])
plt.tight_layout()
plt.show()
# ---------------------- 3. 定义CNN模型 ----------------------
class CNN(nn.Module):
def __init__(self):
super().__init__()
# 卷积部分:提取图像特征
self.conv_layers = nn.Sequential(
# 第1卷积块:卷积→激活→池化
nn.Conv2d(3, 32, 3, padding=1), # 3通道→32通道,3×3卷积核, padding=1保持尺寸
nn.ReLU(), # 激活函数(引入非线性)
nn.MaxPool2d(2, 2), # 2×2最大池化,尺寸减半(32×32→16×16)
# 第2卷积块
nn.Conv2d(32, 64, 3, padding=1), # 32通道→64通道
nn.ReLU(),
nn.MaxPool2d(2, 2), # 16×16→8×8
# 第3卷积块
nn.Conv2d(64, 64, 3, padding=1), # 64通道→64通道
nn.ReLU(),
nn.MaxPool2d(2, 2) # 8×8→4×4
)
# 全连接部分:分类
self.fc_layers = nn.Sequential(
nn.Flatten(), # 展平特征图(64×4×4→1024)
nn.Linear(64 * 4 * 4, 64), # 1024→64
nn.ReLU(),
nn.Linear(64, 10) # 64→10(10个类别)
)
def forward(self, x):
x = self.conv_layers(x) # 卷积部分处理
x = self.fc_layers(x) # 全连接部分分类
return x
# 创建模型实例(自动检测GPU,优先使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = CNN().to(device)
print("模型运行设备:", device)
print("模型结构:\n", model)
# ---------------------- 4. 定义损失函数和优化器 ----------------------
criterion = nn.CrossEntropyLoss() # 交叉熵损失(多分类问题常用)
optimizer = optim.Adam(model.parameters(), lr=0.001) # Adam优化器(比SGD更智能)
# ---------------------- 5. 训练模型 ----------------------
epochs = 10 # 训练10轮
train_losses = []
train_accs = []
for epoch in range(epochs):
running_loss = 0.0
correct = 0
total = 0
# 遍历训练集
for i, data in enumerate(trainloader, 0):
# 获取输入和标签,并移到GPU(如果可用)
inputs, labels = data[0].to(device), data[1].to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播→计算损失→反向传播→更新参数
outputs = model(inputs)
loss = criterion(outputs, labels)
loss.backward()
optimizer.step()
# 统计损失和准确率
running_loss += loss.item()
_, predicted = torch.max(outputs.data, 1) # 取概率最大的类别
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 每200批打印一次中间结果
if i % 200 == 199:
print(f'轮数:{epoch+1}, 批次:{i+1}, 平均损失:{running_loss/200:.3f}')
running_loss = 0.0
# 计算本轮训练的准确率
train_acc = 100 * correct / total
train_losses.append(running_loss / len(trainloader))
train_accs.append(train_acc)
print(f'第{epoch+1}轮训练准确率:{train_acc:.2f}%')
print('训练完成!')
# ---------------------- 6. 在测试集上评估模型 ----------------------
model.eval() # 切换到评估模式(关闭Dropout等)
correct = 0
total = 0
class_correct = list(0. for i in range(10))
class_total = list(0. for i in range(10))
with torch.no_grad(): # 关闭梯度计算(节省内存)
for data in testloader:
images, labels = data[0].to(device), data[1].to(device)
outputs = model(images)
_, predicted = torch.max(outputs, 1)
total += labels.size(0)
correct += (predicted == labels).sum().item()
# 按类别统计准确率
c = (predicted == labels).squeeze()
for i in range(labels.size(0)):
label = labels[i]
class_correct[label] += c[i].item()
class_total[label] += 1
test_acc = 100 * correct / total
print(f'测试集总准确率:{test_acc:.2f}%')
# 打印每个类别的准确率
print("\n各类别准确率:")
for i in range(10):
print(f'{classes[i]}: {100 * class_correct[i] / class_total[i]:.2f}%')
# ---------------------- 7. 可视化预测结果 ----------------------
# 获取测试集图片并预测
dataiter = iter(testloader)
images, labels = next(dataiter)
images_gpu = images.to(device)
outputs = model(images_gpu)
_, predicted = torch.max(outputs, 1)
# 显示前6张图片的预测结果
plt.figure(figsize=(10, 4))
for i in range(6):
plt.subplot(1, 6, i+1)
imshow(images[i])
# 标题:真实标签 vs 预测标签(正确绿色,错误红色)
color = 'green' if predicted[i] == labels[i] else 'red'
plt.title(f'真实:{classes[labels[i]]}\n预测:{classes[predicted[i]]}', color=color)
plt.tight_layout()
plt.show()
# ---------------------- 8. 保存模型 ----------------------
torch.save(model.state_dict(), 'cifar10_cnn.pth')
print("\n模型参数已保存为:cifar10_cnn.pth")
4.3 核心知识点解析
-
CNN 为什么适合图像?
- 卷积层(
Conv2d):用卷积核 “滑动扫描” 图片,提取局部特征(如边缘、角点),32/64 是卷积核数量(越多特征越丰富); - 池化层(
MaxPool2d):缩小图片尺寸(如 32×32→16×16),减少计算量,同时保留关键特征; - 全连接层(
Linear):将卷积层提取的特征 “汇总”,输出 10 个类别的概率。
- 卷积层(
-
数据预处理关键步骤:
ToTensor():将图片(0~255)转为张量(0~1);Normalize():标准化到 [-1,1],让模型训练更稳定;DataLoader:批量加载数据,支持多线程加速,shuffle=True打乱训练集顺序。
-
训练技巧:
- 设备切换:
to(device)将模型和数据移到 GPU,训练速度提升明显; - 评估模式:
model.eval()关闭 Dropout、BatchNorm 等训练特有的层,确保评估准确; - 梯度关闭:
with torch.no_grad()在评估时关闭梯度计算,节省内存。
- 设备切换:
4.4 运行结果与优化
- 训练 10 轮后,测试集准确率约 70%~75%,能正确识别大部分图片;
- 优化方向:增加训练轮数(20~30 轮)、添加
nn.Dropout(0.5)防止过拟合、使用数据增强(transforms.RandomHorizontalFlip()等)、调整学习率。
五、实战 3:RNN 文本生成 —— 用 PyTorch 写唐诗(序列数据处理)

图像用 CNN,文本等 “序列数据”(按顺序排列的数据)用循环神经网络(RNN/LSTM) 处理。我们用 LSTM 模型学习唐诗的规律,自动生成新的唐诗(比如输入 “床前明月光”,续写完整诗句)。
5.1 场景说明
用唐诗数据集(约 5 万首)训练模型,模型输入一句诗的前几个字,能自动预测下一个字,逐步生成完整诗句。例如:输入:“春眠不觉晓”生成:“春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。”
5.2 完整代码实现(简化版,聚焦核心逻辑)
import torch
import torch.nn as nn
import torch.optim as optim
import numpy as np
import os
import re
from collections import Counter
# ---------------------- 1. 准备数据(唐诗预处理) ----------------------
# 加载唐诗数据集(假设数据文件为tangshi.txt,每行一首诗)
def load_data(path='tangshi.txt'):
if not os.path.exists(path):
# 实际使用时可下载数据集,这里用示例数据替代
with open(path, 'w', encoding='utf-8') as f:
f.write('床前明月光,疑是地上霜。举头望明月,低头思故乡。\n')
f.write('春眠不觉晓,处处闻啼鸟。夜来风雨声,花落知多少。\n')
f.write('锄禾日当午,汗滴禾下土。谁知盘中餐,粒粒皆辛苦。\n')
with open(path, 'r', encoding='utf-8') as f:
poems = f.readlines()
# 数据清洗:保留中文、逗号、句号
poems = [re.sub(r'[^\u4e00-\u9fa5,。]', '', p) for p in poems]
poems = [p for p in poems if len(p) > 5] # 过滤太短的诗
return poems
# 加载并预处理数据
poems = load_data()
print(f'加载唐诗数量:{len(poems)}')
print('示例唐诗:', poems[:3])
# 构建字表(将字映射到索引)
all_chars = [c for poem in poems for c in poem]
char_counts = Counter(all_chars)
chars = [c for c, _ in char_counts.most_common()] # 按频率排序
char2idx = {c: i+1 for i, c in enumerate(chars)} # 索引从1开始,0留作填充
char2idx['<PAD>'] = 0 # 填充标记
idx2char = {i: c for c, i in char2idx.items()}
vocab_size = len(char2idx) # 词汇表大小
print(f'词汇表大小(不同字的数量):{vocab_size}')
# 生成训练数据(输入:前n个字,输出:下一个字)
seq_length = 5 # 输入序列长度(用前5个字预测第6个)
input_seqs = []
target_chars = []
for poem in poems:
# 将诗转为索引序列
poem_idx = [char2idx[c] for c in poem if c in char2idx]
# 滑动窗口生成样本
for i in range(len(poem_idx) - seq_length):
input_seqs.append(poem_idx[i:i+seq_length]) # 输入:前5个索引
target_chars.append(poem_idx[i+seq_length]) # 输出:第6个索引
# 转为张量
input_tensor = torch.tensor(input_seqs, dtype=torch.long)
target_tensor = torch.tensor(target_chars, dtype=torch.long)
print(f'训练样本数量:{len(input_tensor)}')
print(f'输入形状:{input_tensor.shape},目标形状:{target_tensor.shape}')
# 创建数据集和数据加载器
dataset = torch.utils.data.TensorDataset(input_tensor, target_tensor)
dataloader = torch.utils.data.DataLoader(
dataset, batch_size=32, shuffle=True
)
# ---------------------- 2. 定义LSTM模型 ----------------------
class PoetryLSTM(nn.Module):
def __init__(self, vocab_size, embedding_dim=128, hidden_dim=256):
super().__init__()
self.embedding = nn.Embedding(
num_embeddings=vocab_size, # 词汇表大小
embedding_dim=embedding_dim # 字向量维度(每个字用128维向量表示)
)
self.lstm = nn.LSTM(
input_size=embedding_dim,
hidden_size=hidden_dim, # LSTM隐藏层维度
batch_first=True # 输入形状为(batch, seq_len, feature)
)
self.fc = nn.Linear(hidden_dim, vocab_size) # 输出层:预测下一个字的概率
def forward(self, x, hidden=None):
# 嵌入层:索引→字向量(batch, seq_len)→(batch, seq_len, embedding_dim)
x = self.embedding(x)
# LSTM层:返回输出和隐藏状态
lstm_out, hidden = self.lstm(x, hidden) # hidden=(h0, c0)
# 取最后一个时间步的输出(用于预测下一个字)
last_out = lstm_out[:, -1, :]
# 输出层:预测每个字的概率
output = self.fc(last_out)
return output, hidden
# 创建模型(使用GPU)
device = torch.device("cuda:0" if torch.cuda.is_available() else "cpu")
model = PoetryLSTM(vocab_size).to(device)
print("模型结构:\n", model)
# ---------------------- 3. 定义损失函数和优化器 ----------------------
criterion = nn.CrossEntropyLoss()
optimizer = optim.Adam(model.parameters(), lr=0.001)
# ---------------------- 4. 训练模型 ----------------------
epochs = 20 # 训练20轮
for epoch in range(epochs):
running_loss = 0.0
for i, (inputs, targets) in enumerate(dataloader):
inputs, targets = inputs.to(device), targets.to(device)
# 清零梯度
optimizer.zero_grad()
# 前向传播
outputs, _ = model(inputs)
loss = criterion(outputs, targets)
# 反向传播+更新参数
loss.backward()
optimizer.step()
running_loss += loss.item()
# 打印每轮损失
avg_loss = running_loss / len(dataloader)
print(f'轮数:{epoch+1}, 平均损失:{avg_loss:.4f}')
print('训练完成!')
# ---------------------- 5. 生成唐诗 ----------------------
def generate_poem(start_str, max_len=20, temperature=0.7):
"""
生成唐诗
start_str:起始字符串(如“床前明月光”)
temperature:控制生成多样性(0~1,越小越保守,越大越随机)
"""
model.eval() # 评估模式
with torch.no_grad():
# 起始字符串转为索引
input_seq = [char2idx[c] for c in start_str if c in char2idx]
if len(input_seq) < seq_length:
# 不足seq_length时填充
input_seq = [0]*(seq_length - len(input_seq)) + input_seq
input_tensor = torch.tensor([input_seq], dtype=torch.long).to(device)
poem = start_str # 生成的诗
hidden = None # LSTM隐藏状态
for _ in range(max_len):
# 预测下一个字
output, hidden = model(input_tensor, hidden)
# 按temperature调整概率分布
output = output / temperature
probs = torch.softmax(output, dim=1).cpu().numpy()[0]
# 按概率采样下一个字(不是取最大概率,增加多样性)
next_idx = np.random.choice(len(probs), p=probs)
next_char = idx2char[next_idx]
# 更新诗和输入序列
poem += next_char
input_seq = input_seq[1:] + [next_idx]
input_tensor = torch.tensor([input_seq], dtype=torch.long).to(device)
# 如果遇到句号,结束生成
if next_char == '。':
break
return poem
# 测试生成功能
print("\n生成唐诗示例:")
print(generate_poem("床前明月光", max_len=30))
print(generate_poem("春眠不觉晓", max_len=30))
print(generate_poem("锄禾日当午", max_len=30))
# 保存模型
torch.save(model.state_dict(), 'tangshi_lstm.pth')
print("\n模型参数已保存为:tangshi_lstm.pth")
5.3 核心知识点解析
-
文本预处理关键步骤:
- 构建字表:将每个字映射到唯一索引(如 “床”→1,“前”→2),让模型能处理文本;
- 生成样本:用滑动窗口截取序列(如 “床前明月光”→输入 “床前明月”,输出 “光”),让模型学习 “上下文→下一个字” 的规律。
-
LSTM 模型核心组件:
- 嵌入层(
Embedding):将字索引转为低维向量(如 128 维),捕捉字的语义(比如 “月” 和 “明” 的向量距离近); - LSTM 层:处理序列数据,记住前文信息(比如 “举头望” 后面更可能接 “明月”);
- 输出层:预测下一个字的概率分布。
- 嵌入层(
-
文本生成技巧:
- 温度参数(
temperature):控制生成多样性,0.7 左右效果较好(太接近 0 会重复,太大则混乱); - 采样而非取最大概率:用
np.random.choice按概率采样,避免生成固定句式。
- 温度参数(
5.4 运行结果与优化
- 用示例数据训练后,生成的诗句可能不太通顺,但能模仿唐诗的格式(五言、带标点);
- 优化方向:使用更大的唐诗数据集(数万首)、增加训练轮数(50~100 轮)、调大
embedding_dim和hidden_dim、使用双向 LSTM(nn.LSTM(bidirectional=True))。
六、PyTorch 新手避坑指南:10 个高频错误及解决方案

学习 PyTorch 时,新手很容易在细节上踩坑,这里总结 10 个最常见的问题及解决方法:
6.1 坑 1:张量在 CPU 和 GPU 之间不匹配
现象:报错 “RuntimeError: Expected all tensors to be on the same device”。原因:模型在 GPU,输入数据在 CPU(或反之),设备不一致。解决方案:确保模型和数据在同一设备:
device = torch.device("cuda" if torch.cuda.is_available() else "cpu")
model = model.to(device) # 模型移到设备
inputs = inputs.to(device) # 数据移到设备
6.2 坑 2:忘记转换数据类型
现象:报错 “RuntimeError: Expected floating point tensor for input, got Long tensor”。原因:输入数据是LongTensor(整数),但模型需要FloatTensor(浮点数)。解决方案:用.float()转换:
inputs = inputs.float() # 转为浮点型
6.3 坑 3:梯度计算相关错误
现象:报错 “RuntimeError: Trying to backward through a tensor that does not require gradients”。原因:对不需要梯度的张量调用backward()。解决方案:创建张量时指定requires_grad=True(仅对需要求导的参数):
x = torch.tensor(1.0, requires_grad=True) # 需要计算梯度
6.4 坑 4:数据形状不符合模型要求
现象:报错 “RuntimeError: Expected 4-dimensional input for 4-dimensional weight, but got 3-dimensional input”。原因:CNN 输入需要 4 维(batch×channel×height×width),但给了 3 维(少了 batch 维度)。解决方案:用unsqueeze(0)增加 batch 维度:
img = img.unsqueeze(0) # 从(3,32,32)→(1,3,32,32)
6.5 坑 5:训练时未切换模型模式
现象:评估时准确率波动大,和训练时差距大。原因:模型在train模式(默认),Dropout、BatchNorm等层会影响评估。解决方案:评估前切换到eval模式:
model.eval() # 评估模式
with torch.no_grad(): # 关闭梯度计算
# 评估代码...
6.6 坑 6:学习率设置不当
现象:损失不下降(太大)或下降极慢(太小)。解决方案:从0.001开始尝试,用学习率调度器动态调整:
# 学习率每3轮乘以0.1
scheduler = optim.lr_scheduler.StepLR(optimizer, step_size=3, gamma=0.1)
# 训练循环中调用
scheduler.step()
6.7 坑 7:数据加载时num_workers导致错误(Windows)
现象:Windows 系统中,num_workers>0时报错 “BrokenPipeError”。原因:Windows 多进程支持问题。解决方案:Windows 下num_workers=0,或用if __name__ == '__main__':包裹主代码。
6.8 坑 8:模型保存与加载错误
现象:加载模型时参数不匹配,报错 “size mismatch”。原因:保存 / 加载方式不对,或模型结构有变化。解决方案:
- 保存参数:
torch.save(model.state_dict(), 'model.pth') - 加载参数:
model.load_state_dict(torch.load('model.pth'))
6.9 坑 9:过拟合(训练准确率高,测试准确率低)
现象:模型在训练集表现好,在新数据上表现差。解决方案:
- 添加
nn.Dropout(0.5)层随机丢弃神经元; - 增加数据量或使用数据增强;
- 减少模型参数(如减小隐藏层维度)。
6.10 坑 10:张量无法转换为 NumPy(GPU 张量)
现象:报错 “TypeError: can't convert cuda:0 device type tensor to numpy”。原因:GPU 上的张量不能直接转 NumPy。解决方案:先移到 CPU 再转换:
tensor_cpu = tensor.cpu() # 移到CPU
arr = tensor_cpu.numpy() # 转NumPy
七、PyTorch 学习路线:从入门到实战高手

掌握基础后,可按以下路线进阶,逐步成为 PyTorch 高手:
7.1 入门阶段(1~2 个月)
- 核心 API:熟练使用张量操作、
nn.Module、损失函数、优化器; - 基础模型:线性回归、逻辑回归、简单 CNN/RNN;
- 实战项目:用 PyTorch 复现鸢尾花分类、波士顿房价预测。
7.2 进阶阶段(2~3 个月)
- 高级层:
nn.Transformer(Transformer 模型)、nn.BatchNorm(批量归一化); - 训练技巧:学习率调度、早停(Early Stopping)、混合精度训练;
- 实战项目:CIFAR-10 图像分类(准确率 85%+)、LSTM 文本分类。
7.3 实战阶段(3~6 个月)
- 预训练模型:用
torchvision加载 ResNet、VGG 等预训练模型,实现迁移学习; - 自然语言处理:用 Hugging Face 库(与 PyTorch 兼容)微调 BERT 模型;
- 部署:用
TorchScript优化模型,导出为 ONNX 格式,部署到移动端或服务器。
7.4 高级阶段(6 个月以上)
- 源码阅读:理解 PyTorch 自动求导、分布式训练的底层实现;
- 自定义层:实现论文中的新型网络层;
- 分布式训练:用
torch.distributed实现多 GPU / 多机训练,处理大规模数据。
八、总结:PyTorch 入门的核心是 “动手实战”
很多人觉得深度学习难,是因为被 “神经网络”“反向传播” 等术语吓退了。但用 PyTorch 学习时,你会发现:这些复杂概念都被封装成了简单的 API,你不需要推导公式,只需调用nn.Linear、loss.backward(),就能让模型自己 “学习”。
这篇博客从环境搭建到实战项目(线性回归、CNN 图像分类、LSTM 文本生成),再到避坑指南和学习路线,覆盖了 PyTorch 入门的核心内容。新手可以按 “线性回归→CNN→RNN” 的顺序学习,每个项目都动手敲代码、调参数,感受模型从 “随机预测” 到 “精准输出” 的过程 —— 这才是深度学习最有趣的地方。
记住:PyTorch 的优势在于 “灵活” 和 “易用”,不要害怕犯错,每一次调试都是一次进步。当你能用它解决实际问题(比如给图片分类、生成文本)时,你会发现深度学习其实没那么神秘!
如果觉得这篇博客有帮助,欢迎点赞、收藏、转发!有任何问题,欢迎在评论区留言,我会第一时间回复~



















 34
34

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









