




目录
1.3 Broker 选型:Redis vs RabbitMQ 怎么选?
二、环境搭建:3 步搞定 Celery 基础配置(Windows/Linux 通用)
6.1 Django + Celery:Web 应用异步处理
步骤 2:创建 Celery 配置文件(myblog/celery.py)
步骤 6:视图中调用任务(article/views.py)

class 卑微码农:
def __init__(self):
self.技能 = ['能读懂十年前祖传代码', '擅长用Ctrl+C/V搭建世界', '信奉"能跑就别动"的玄学']
self.发量 = 100 # 初始发量
self.咖啡因耐受度 = '极限'
def 修Bug(self, bug):
try:
# 试图用玄学解决问题
if bug.严重程度 == '离谱':
print("这一定是环境问题!")
else:
print("让我看看是谁又没写注释...哦,是我自己。")
except Exception as e:
# 如果try块都救不了,那就...
print("重启一下试试?")
self.发量 -= 1 # 每解决一个bug,头发-1
# 实例化一个我
我 = 卑微码农()前言:为什么你的 Python 程序需要 Celery?
你是否遇到过这些场景:用户注册后点击 “获取验证码”,页面转了 10 秒才响应;数据分析脚本跑了半小时,终端卡死只能强制关闭;定时生成的日报突然罢工,凌晨 3 点收到告警短信?这些问题的核心,都是同步任务阻塞了主线程,而 Celery 正是解决这类问题的 “终极武器”。

作为 Python 生态中最成熟的分布式任务队列,Celery 就像一个 “智能工厂”—— 主程序只需把耗时任务 “下单” 到队列,后台的 “工人”(Worker)会自动并行处理,主程序完全不会卡住。无论是异步处理、定时调度,还是分布式任务分发,Celery 都能轻松 hold 住。
这篇博客我会结合 5 年生产环境踩坑经验,从基础概念到实战落地,再到性能调优,用最通俗的语言 + 可直接运行的代码,带你彻底掌握 Celery。不管你是 Web 开发者、数据分析师,还是运维工程师,读完这篇都能直接上手实操,让你的程序从 “卡成狗” 变 “飞一般”。
一、Celery 核心概念:5 分钟搞懂工作原理
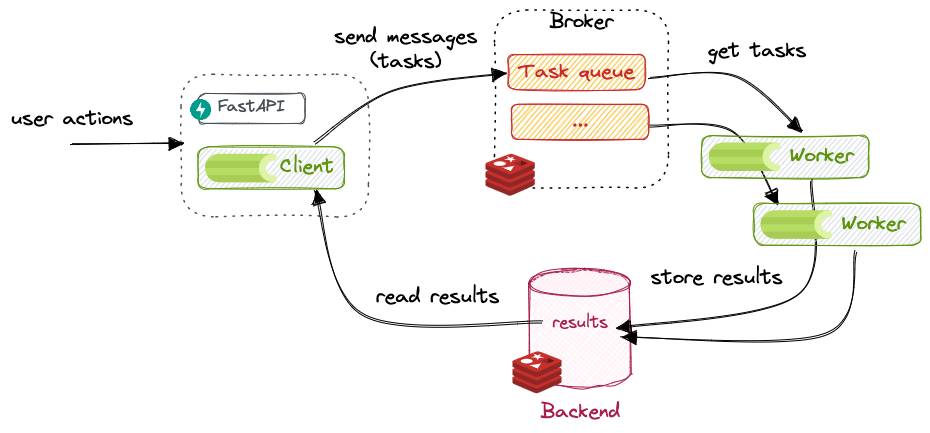
1.1 核心组件:“工厂四件套”
Celery 的架构并不复杂,核心就是四个组件,用一个 “餐厅运营” 的例子就能看懂:
- 生产者(Producer):发起任务的程序,比如用户点击 “发送验证码” 时的 Web 应用,相当于 “顾客下单”。
- Broker(消息代理):任务的 “中转站”,接收生产者的任务并转发给 Worker,相当于 “前台服务员”。常用 Redis 或 RabbitMQ,开发环境首选 Redis(配置简单),生产环境推荐 RabbitMQ(稳定性更强)。
- Worker(任务消费者):实际执行任务的进程,相当于 “后厨厨师”,可以在同一台机器或多台机器上运行,支持并行处理。
- Backend(结果后端):存储任务执行结果的 “仓库”,可选配置,相当于 “菜品上桌记录”。如果需要查询任务是否成功、获取返回值,就需要配置 Backend(常用 Redis 或数据库)。
- Beat(定时调度器):专门负责定时任务的 “闹钟”,相当于 “餐厅预定提醒”,支持 CRON 表达式,比 Linux 的 crontab 更灵活。
1.2 工作流程:一张图看懂任务生命周期
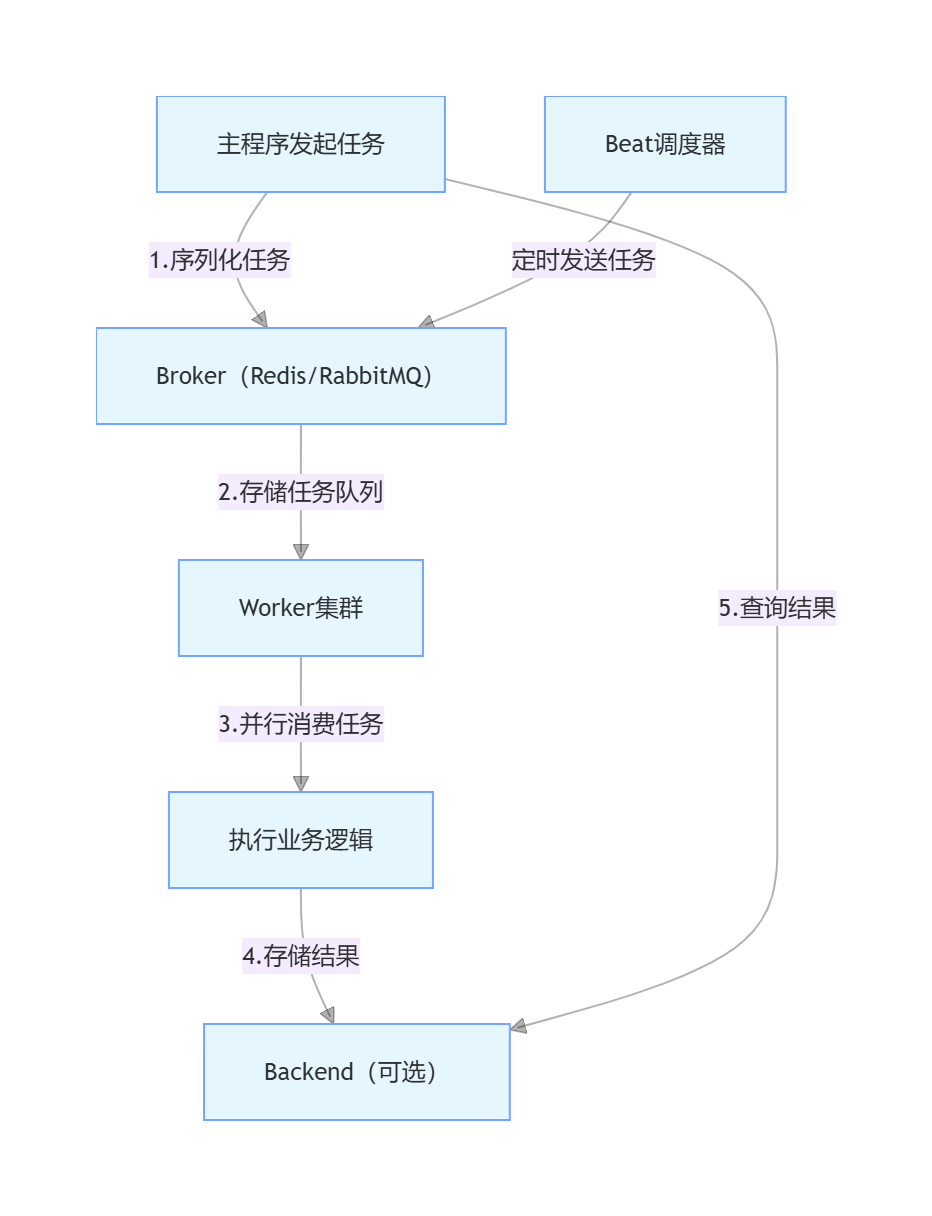
简单来说,任务的生命周期就四步:
- 主程序通过
delay()或apply_async()方法发起任务,任务会被序列化为 JSON 格式; - Broker 接收任务并存储到指定队列;
- Worker 实时监听 Broker,获取任务后反序列化,执行业务逻辑;
- 执行结果(成功 / 失败 / 返回值)被存储到 Backend,主程序可随时查询。
1.3 Broker 选型:Redis vs RabbitMQ 怎么选?
很多新手第一步就卡在 Broker 选型上,其实核心看场景,一张表对比清楚:
| 特性 | Redis | RabbitMQ |
|---|---|---|
| 配置难度 | 低(5 分钟上手) | 中(需了解 AMQP 协议) |
| 性能 | 高(内存操作,适合短任务) | 中高(稳定优先,适合长任务) |
| 持久化 | 支持 AOF/RDB(需手动配置) | 默认持久化(消息不丢失) |
| 高可用 | 支持哨兵 / 集群模式 | 支持集群 + 镜像队列 |
| 适用场景 | 开发环境、I/O 密集型任务、小流量生产 | 大流量生产环境、金融级任务、复杂路由 |
新手建议:先从 Redis 入手,配置简单且足够支撑大部分场景;如果是支付、订单等核心业务,再迁移到 RabbitMQ。
二、环境搭建:3 步搞定 Celery 基础配置(Windows/Linux 通用)

2.1 安装依赖
首先安装 Celery 和 Broker(以 Redis 为例,最易上手):
# 基础安装(Celery+Redis)
pip install celery redis
# 可选依赖(生产环境必备)
pip install flower # 监控工具
pip install gevent # 协程池(提升I/O密集型任务性能)
pip install django-celery-results # Django集成用
2.2 启动 Redis 服务
- Windows:下载 Redis 安装包,双击
redis-server.exe,默认端口 6379(无需密码)。 - Linux:执行
redis-server /etc/redis/redis.conf,确保配置文件中bind 127.0.0.1(本地连接)或protected-mode no(允许远程连接)。
验证 Redis 是否可用:执行redis-cli ping,返回PONG说明启动成功。
2.3 第一个 Celery 程序:Hello World
创建项目结构(超简单,只需 2 个文件):
celery-demo/
├── tasks.py # 任务定义文件
└── main.py # 任务调用文件
步骤 1:定义任务(tasks.py)
from celery import Celery
# 1. 初始化Celery实例
# 第一个参数:项目名称(任意)
# broker:Redis连接地址(格式:redis://IP:端口/数据库编号)
# backend:结果存储地址(可选,和broker用同一个Redis即可)
app = Celery(
'celery_demo',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/1'
)
# 2. 定义异步任务(用@app.task装饰器)
@app.task(name='add_task') # name参数可选,用于指定任务唯一标识
def add(x, y):
"""简单的加法任务,模拟耗时操作"""
import time
time.sleep(2) # 模拟2秒耗时
return x + y
@app.task(name='multiply_task')
def multiply(x, y):
"""乘法任务,演示参数传递"""
return x * y
步骤 2:启动 Worker(关键步骤)
打开终端,进入celery-demo目录,执行启动命令:
# 格式:celery -A 模块名 worker -l 日志级别
celery -A tasks worker -l INFO
-A:指定 Celery 实例所在的模块(这里是 tasks.py);worker:启动 Worker 进程;-l INFO:日志级别为 INFO(可选,支持 DEBUG/INFO/WARNING/ERROR)。
启动成功后,终端会显示 Worker 信息,包括监听的队列、并发数等,类似这样:
[2025-11-07 10:00:00,000: INFO/MainProcess] Connected to redis://localhost:6379/0
[2025-11-07 10:00:00,000: INFO/MainProcess] celery@localhost ready.
步骤 3:调用任务(main.py)
from tasks import add, multiply
# 1. 异步调用任务(delay()是apply_async()的快捷方式)
task1 = add.delay(10, 20) # 发起加法任务
task2 = multiply.delay(5, 6) # 发起乘法任务
# 2. 查询任务状态和结果
print("任务1 ID:", task1.id) # 输出任务唯一ID,如:e3888888-xxxx-xxxx-xxxx-xxxxxxxxxxxx
print("任务1状态:", task1.status) # PENDING(等待中)/PROGRESS(执行中)/SUCCESS(成功)/FAILURE(失败)
# 3. 等待任务完成并获取结果(get()方法会阻塞,实际开发中慎用)
result1 = task1.get(timeout=10) # 超时时间10秒
result2 = task2.get(timeout=10)
print("加法结果:", result1) # 输出30
print("乘法结果:", result2) # 输出30
运行main.py,此时 Worker 终端会显示任务执行日志,主程序会在 2 秒后输出结果,全程不会阻塞。
踩坑提醒:如果启动 Worker 时提示 “Redis 连接失败”,检查 Redis 是否启动、IP 和端口是否正确,Linux 环境需确保 Redis 允许远程连接(修改redis.conf的bind参数)。
三、进阶用法:从基础到实战,覆盖 80% 场景

3.1 定时任务:Beat 调度器的正确用法
很多场景需要定时执行任务,比如每天凌晨 3 点生成报表、每小时同步数据、每周一发送周报。Celery 的 Beat 调度器比 Linux 的 crontab 更 Pythonic,支持精确到秒的调度。
步骤 1:配置定时任务(tasks.py)
在 Celery 实例后添加定时任务配置:
from celery import Celery
from celery.schedules import crontab # 导入CRON表达式支持
app = Celery(
'celery_demo',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/1'
)
# 配置定时任务
app.conf.beat_schedule = {
# 任务1:每10秒执行一次加法任务
'add-every-10-seconds': {
'task': 'add_task', # 对应任务的name参数
'schedule': 10.0, # 间隔时间(秒)
'args': (100, 200) # 固定参数
},
# 任务2:每天凌晨3点执行报表生成任务
'generate-report-daily': {
'task': 'generate_report',
'schedule': crontab(hour=3, minute=0), # CRON表达式:小时=3,分钟=0
'args': ('daily',)
},
# 任务3:每周一上午10点执行周报任务
'generate-report-weekly': {
'task': 'generate_report',
'schedule': crontab(hour=10, minute=0, day_of_week=1), # day_of_week=1表示周一(0=周日)
'args': ('weekly',)
}
}
# 定义报表生成任务
@app.task(name='generate_report')
def generate_report(report_type):
"""模拟生成报表"""
import time
import datetime
now = datetime.datetime.now().strftime("%Y-%m-%d %H:%M:%S")
time.sleep(3) # 模拟3秒生成时间
return f"{now} 成功生成{report_type}报表"
步骤 2:启动 Beat 调度器
Beat 需要单独启动,和 Worker 一起运行:
# 启动Beat(在新终端执行)
celery -A tasks beat -l INFO
# 保持Worker运行(之前的终端不要关)
celery -A tasks worker -l INFO
启动后,Beat 会按照配置的时间发送任务到 Broker,Worker 自动消费执行。终端会显示任务调度日志,比如每 10 秒执行一次add_task。
进阶技巧:如果需要动态添加 / 修改定时任务(比如在 Web 界面配置),可以使用django-celery-beat扩展,支持数据库存储定时任务,无需重启 Beat 进程。
3.2 任务路由:给不同任务分配 “专属 Worker”
实际项目中,任务类型不同,优先级和资源需求也不同。比如支付回调任务需要优先执行,而大数据分析任务耗时长、占用资源多。这时可以通过任务路由,将不同任务分配到不同队列,再启动专用 Worker 消费,避免资源抢占。
步骤 1:配置任务路由(tasks.py)
app = Celery(
'celery_demo',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/1'
)
# 配置任务路由规则
app.conf.task_routes = {
'payment_task': {'queue': 'high_priority'}, # 支付相关任务→高优先级队列
'data_analysis_task': {'queue': 'low_priority'}, # 数据分析任务→低优先级队列
'default': {'queue': 'default'} # 其他任务→默认队列
}
# 定义不同优先级任务
@app.task(name='payment_task')
def process_payment(order_id, amount):
"""支付回调任务(高优先级)"""
print(f"处理订单{order_id}支付,金额{amount}元")
return f"订单{order_id}支付处理成功"
@app.task(name='data_analysis_task')
def data_analysis(date_range):
"""数据分析任务(低优先级)"""
import time
time.sleep(10) # 模拟耗时分析
return f"{date_range}数据分析完成"
步骤 2:启动专用 Worker
分别启动消费不同队列的 Worker,指定并发数和资源限制:
# 启动高优先级队列Worker(并发数8,优先处理支付任务)
celery -A tasks worker -Q high_priority -c 8 -l INFO --hostname=worker.high
# 启动低优先级队列Worker(并发数4,处理数据分析任务)
celery -A tasks worker -Q low_priority -c 4 -l INFO --hostname=worker.low
# 启动默认队列Worker
celery -A tasks worker -Q default -c 4 -l INFO --hostname=worker.default
-Q:指定消费的队列名称;-c:设置并发数(默认等于 CPU 核心数);--hostname:给 Worker 命名,方便监控。
步骤 3:调用路由任务(main.py)
from tasks import process_payment, data_analysis
# 高优先级任务会进入high_priority队列
payment_task = process_payment.delay("ORDER123456", 99.9)
# 低优先级任务会进入low_priority队列
analysis_task = data_analysis.delay("2025-11-01至2025-11-07")
print(payment_task.get()) # 快速返回结果
print(analysis_task.get()) # 等待10秒后返回
3.3 任务重试与幂等性:避免重复执行的坑
网络波动、数据库临时不可用等情况会导致任务失败,Celery 支持自动重试,但必须保证任务的幂等性(多次执行结果一致),否则可能出现重复扣款、重复发送短信等严重问题。
示例:带重试机制的幂等性任务
@app.task(
name='send_sms',
retry_backoff=3, # 重试延迟时间:3秒、6秒、12秒...(指数退避)
retry_kwargs={'max_retries': 5}, # 最大重试5次
autoretry_for=(ConnectionError, TimeoutError) # 遇到这些异常自动重试
)
def send_sms(phone, content):
"""发送短信任务(幂等性设计)"""
# 幂等性关键:用唯一标识(如手机号+时间戳)避免重复发送
import hashlib
import time
from redis import Redis
redis_client = Redis(host='localhost', port=6379, db=2)
# 生成任务唯一标识
task_key = f"sms:{phone}:{hashlib.md5(content.encode()).hexdigest()}"
# 检查任务是否已执行(Redis分布式锁)
if redis_client.setnx(task_key, 1):
redis_client.expire(task_key, 300) # 5分钟过期
try:
# 模拟调用短信API
print(f"向手机号{phone}发送短信:{content}")
# 模拟网络波动(测试重试)
# raise ConnectionError("短信API连接失败")
return f"短信发送成功"
except Exception as e:
# 手动触发重试(也可以依赖autoretry_for自动重试)
raise send_sms.retry(exc=e)
else:
# 任务已执行,直接返回成功
return f"短信已发送,避免重复执行"
关键要点:
- 幂等性设计:通过 Redis 分布式锁、唯一任务标识等方式,确保任务多次执行不会产生副作用;
- 重试策略:使用
retry_backoff实现指数退避,避免频繁重试压垮 API; - 明确重试异常:只对可恢复的异常(如网络错误)重试,避免无效重试。
3.4 任务工作流:链式 / 并行任务编排
复杂场景需要多个任务按顺序或并行执行,比如电商订单处理流程:创建订单→扣减库存→支付确认→发送通知→数据归档。Celery 提供了chain(链式)、group(并行)、chord(并行 + 回调)等工作流原语,轻松实现任务编排。
示例 1:链式任务(按顺序执行)
from celery import chain
# 定义订单处理各步骤任务
@app.task(name='create_order')
def create_order(user_id, goods_id):
"""步骤1:创建订单"""
order_id = f"ORDER{user_id}{goods_id}{int(time.time())}"
print(f"创建订单:{order_id}")
return order_id
@app.task(name='reduce_stock')
def reduce_stock(order_id, goods_id):
"""步骤2:扣减库存"""
print(f"订单{order_id}扣减商品{goods_id}库存")
return True
@app.task(name='confirm_payment')
def confirm_payment(order_id, amount):
"""步骤3:确认支付"""
print(f"订单{order_id}支付{amount}元成功")
return True
@app.task(name='send_notification')
def send_notification(order_id, user_id):
"""步骤4:发送通知"""
print(f"向用户{user_id}发送订单{order_id}支付成功通知")
return True
# 链式调用:前一个任务的返回值作为后一个任务的参数
workflow = chain(
create_order.s(1001, "GOODS001"), # s()表示任务签名,用于传递参数
reduce_stock.s("GOODS001"), # 接收前一个任务的order_id
confirm_payment.s(199.9), # 接收前一个任务的True(可忽略,仅传递自定义参数)
send_notification.s(1001) # 接收前一个任务的True
).apply_async()
# 获取最终结果
print(workflow.get()) # 输出:向用户1001发送订单ORDER1001GOODS00117309xxxx支付成功通知
示例 2:并行任务(同时执行)
from celery import group
# 定义3个并行执行的数据分析任务
@app.task(name='analysis_user')
def analysis_user(user_id):
"""分析单个用户数据"""
time.sleep(2)
return f"用户{user_id}数据分析完成"
# 并行执行多个任务
task_group = group(
analysis_user.s(1001),
analysis_user.s(1002),
analysis_user.s(1003)
).apply_async()
# 获取所有任务结果(等待所有任务完成)
results = task_group.get()
print(results) # 输出:['用户1001数据分析完成', '用户1002数据分析完成', '用户1003数据分析完成']
四、生产环境避坑指南:10 个血的教训

4.1 Worker 突然消失?优雅关闭是关键
现象:Worker 运行一段时间后突然消失,日志无报错,任务莫名中断。原因:Linux 系统默认会给后台进程发送SIGTERM信号(比如系统重启、内存不足时),Celery 未捕获信号导致强制关闭。解决方案:
- 配置 Worker 优雅关闭超时:
# tasks.py中添加配置
app.conf.worker_shutdown_timeout = 60 # 关闭前等待60秒,让正在执行的任务完成
app.conf.worker_cancel_long_running_tasks_on_shutdown = False # 不强制取消长任务
- 使用进程管理工具(如 Supervisor、systemd)启动 Worker,确保异常退出后自动重启。
4.2 任务丢失惨案?Broker 持久化配置要做好
现象:Redis 重启后,未执行的任务全部丢失;RabbitMQ 崩溃后,队列数据为空。原因:默认配置下,Broker 未启用持久化,数据只存在内存中。解决方案:
Redis 作为 Broker(推荐配置)
修改redis.conf,启用 AOF 持久化:
appendonly yes # 启用AOF持久化
appendfilename "appendonly.aof" # AOF文件名
appendfsync everysec # 每秒同步一次日志(性能与安全平衡)
auto-aof-rewrite-percentage 100 # AOF文件大小增长100%时重写
auto-aof-rewrite-min-size 64mb # 最小重写大小
同时启用 Redis 哨兵模式(Sentinel)或集群,避免单点故障。
RabbitMQ 作为 Broker(推荐配置)
创建队列时指定durable=True(持久化队列),任务发布时指定delivery_mode=2(持久化消息):
# 配置RabbitMQ持久化
app.conf.broker_transport_options = {
'queue_declare_arguments': {'x-queue-type': 'classic'},
'queue_durable': True # 队列持久化
}
# 任务发布时指定持久化
add.apply_async((10, 20), delivery_mode=2)
4.3 队列积压压垮服务器?监控 + 限流双管齐下
现象:任务提交速度远超 Worker 处理速度,队列积压数万条,Broker 内存飙升。原因:消费能力不足,未设置限流和监控告警。解决方案:
- 任务限流:给高频任务设置速率限制:
# 单个任务限流(每分钟最多100次)
@app.task(name='api_call_task', rate_limit='100/m')
def call_third_party_api(url):
"""调用第三方API的任务"""
import requests
response = requests.get(url)
return response.json()
# 全局限流(所有任务每秒最多500次)
app.conf.task_annotations = {'*': {'rate_limit': '500/s'}}
- 监控积压:使用 Flower 实时查看队列长度,设置告警阈值(如队列长度超过 1000 时告警);
- 扩容 Worker:增加低优先级队列的 Worker 数量,或使用协程池(gevent)提升并发:
bash
# 使用gevent协程池,适合I/O密集型任务(并发数可设为100+)
celery -A tasks worker -P gevent -c 200 -l INFO
4.4 内存泄露杀手?Worker 定期重启
现象:Worker 运行几天后,内存占用从几百 MB 飙升到几 GB,最终被系统 OOM 杀死。原因:Python 的垃圾回收机制无法完全释放循环引用的内存,长期运行会导致内存泄露。解决方案:
- 配置 Worker 最大内存限制,超过阈值自动重启:
app.conf.worker_max_memory_per_child = 300000 # 300MB(单位:KB)
- 定期重启 Worker:通过 Supervisor 配置
autorestart=true,或定时执行重启脚本。
4.5 任务参数不可序列化?这些类型不能传
现象:任务提交时报错kombu.exceptions.EncodeError: Object of type 'User' is not JSON serializable。原因:Celery 默认使用 JSON 序列化任务参数,而 Python 的自定义对象(如 Django 的 User 模型)、函数、类实例等不可序列化。解决方案:
- 只传递可序列化参数:ID、字符串、数字、列表、字典等;
- 复杂对象通过 ID 重建:
# 错误示例:传递自定义对象
user = User.objects.get(id=1001)
send_sms.delay(user, "验证码:123456") # 报错!User对象不可序列化
# 正确示例:传递ID,在任务中重建对象
send_sms.delay(user.id, "验证码:123456")
# 任务中重建对象
@app.task(name='send_sms')
def send_sms(user_id, content):
user = User.objects.get(id=user_id) # 重建User对象
phone = user.phone
# 发送短信...
- 自定义序列化器(如 pickle),但不推荐(安全性和兼容性问题)。
4.6 其他高频坑点速查表
| 坑点 | 原因 | 解决方案 |
|---|---|---|
| 定时任务突然罢工 | Beat 进程崩溃未重启 | 用 Supervisor 管理 Beat,配置--pidfile |
| 任务执行超时 | 单个任务耗时过长 | 拆分长任务为小任务,设置task_time_limit |
| 结果后端撑爆 | 未设置结果过期时间 | app.conf.result_expires = 86400(24 小时) |
| Worker 并发数过高 | CPU / 内存资源耗尽 | 按 CPU 核心数设置并发(I/O 密集型可适当增加) |
| 跨机器 Worker 连不上 Broker | 防火墙拦截端口 | 开放 Redis(6379)/RabbitMQ(5672)端口 |
五、监控与运维:生产环境必备工具

5.1 Flower:Celery 监控神器(推荐)
Flower 是 Celery 官方推荐的监控工具,基于 Web 界面,支持实时查看任务状态、Worker 健康、队列积压等,还能远程重试 / 取消任务,堪称 “Celery 管理面板”。
安装与启动
# 安装
pip install flower
# 启动(默认端口5555)
celery -A tasks flower --port=5555 --broker=redis://localhost:6379/0
核心功能
-
访问
http://localhost:5555,进入 Web 界面:- Tasks:查看所有任务状态(成功 / 失败 / 重试),支持按 ID 搜索、重试失败任务;
- Workers:查看 Worker 在线状态、并发数、任务执行统计;
- Queues:查看各队列积压情况、任务处理速率;
- Monitor:实时监控任务执行曲线、Worker 资源占用。
-
生产环境配置:
# 启用认证(用户名:admin,密码:123456)
celery -A tasks flower --basic_auth=admin:123456 --port=5555
# 持久化任务历史(重启不丢失)
celery -A tasks flower --persistent=True --db=flower.db
5.2 命令行工具:快速排查问题
Celery 提供了celery inspect和celery status等命令,用于快速查看集群状态:
# 查看所有在线Worker
celery -A tasks status
# 查看已注册的任务
celery -A tasks inspect registered
# 查看Worker当前正在执行的任务
celery -A tasks inspect active
# 查看队列长度
celery -A tasks inspect queues
# 清空指定队列(慎用!生产环境避免误操作)
celery -A tasks purge -Q low_priority
5.3 日志配置:问题追溯的关键
生产环境必须配置详细日志,以便排查任务失败原因:
# tasks.py中添加日志配置
import logging
from celery.utils.log import get_task_logger
# 配置日志格式
logging.basicConfig(
level=logging.INFO,
format='%(asctime)s - %(name)s - %(levelname)s - %(message)s',
handlers=[
logging.FileHandler('celery.log'), # 写入文件
logging.StreamHandler() # 输出到终端
]
)
# 获取任务专用logger
task_logger = get_task_logger(__name__)
@app.task(name='error_prone_task')
def error_prone_task():
try:
# 模拟出错
1 / 0
except Exception as e:
# 记录异常日志
task_logger.error(f"任务执行失败:{str(e)}", exc_info=True)
raise
日志会同时输出到终端和celery.log文件,包含时间、任务名、错误堆栈等信息,方便快速定位问题。
六、框架集成实战:2 个真实项目案例

6.1 Django + Celery:Web 应用异步处理
Django 是 Python 最流行的 Web 框架,结合 Celery 可以解决耗时操作阻塞请求的问题(如文件上传、邮件发送、数据导出)。
步骤 1:项目配置
假设 Django 项目名为myblog,应用名为article,项目结构如下:
plaintext
myblog/
├── myblog/
│ ├── __init__.py
│ ├── settings.py
│ ├── celery.py # Celery配置文件
│ └── urls.py
└── article/
├── tasks.py # 任务定义
├── views.py # 视图
└── templates/
步骤 2:创建 Celery 配置文件(myblog/celery.py)
import os
from celery import Celery
from django.conf import settings
# 设置Django环境变量
os.environ.setdefault('DJANGO_SETTINGS_MODULE', 'myblog.settings')
# 初始化Celery实例
app = Celery('myblog')
# 从Django settings中读取Celery配置(前缀为CELERY_)
app.config_from_object('django.conf:settings', namespace='CELERY')
# 自动发现所有应用中的tasks.py文件
app.autodiscover_tasks(lambda: settings.INSTALLED_APPS)
步骤 3:修改 myblog/init.py
# 确保Django启动时加载Celery app
from .celery import app as celery_app
__all__ = ('celery_app',)
步骤 4:在 settings.py 中添加配置
# Celery配置
CELERY_BROKER_URL = 'redis://localhost:6379/0'
CELERY_RESULT_BACKEND = 'redis://localhost:6379/1'
CELERY_ACCEPT_CONTENT = ('json',)
CELERY_TASK_SERIALIZER = 'json'
CELERY_RESULT_SERIALIZER = 'json'
CELERY_TIMEZONE = 'Asia/Shanghai'
CELERY_TASK_TIME_LIMIT = 300 # 任务超时时间(5分钟)
CELERY_RESULT_EXPIRES = 86400 # 结果保留24小时
步骤 5:定义任务(article/tasks.py)
from celery import shared_task
from django.core.mail import send_mail
from django.conf import settings
from .models import Article, ArticleViewLog
@shared_task(name='send_article_notification')
def send_article_notification(article_id, subscriber_emails):
"""给订阅者发送新文章通知邮件"""
article = Article.objects.get(id=article_id)
subject = f"【新文章发布】{article.title}"
message = f"亲爱的订阅者,{article.author}发布了新文章《{article.title}》,快去阅读吧!\n链接:{settings.SITE_DOMAIN}/article/{article.id}/"
send_mail(
subject=subject,
message=message,
from_email=settings.DEFAULT_FROM_EMAIL,
recipient_list=subscriber_emails,
fail_silently=False
)
return f"已向{len(subscriber_emails)}个订阅者发送通知"
@shared_task(name='export_article_statistics')
def export_article_statistics(date_range, email):
"""导出文章访问统计报表(耗时操作)"""
import pandas as pd
from datetime import datetime
start_date, end_date = date_range.split('-')
start_date = datetime.strptime(start_date, '%Y%m%d')
end_date = datetime.strptime(end_date, '%Y%m%d')
# 查询统计数据
logs = ArticleViewLog.objects.filter(
view_time__range=(start_date, end_date)
).values('article__title', 'view_time', 'ip')
# 生成Excel报表
df = pd.DataFrame(list(logs))
filename = f"article_statistics_{start_date.strftime('%Y%m%d')}_{end_date.strftime('%Y%m%d')}.xlsx"
df.to_excel(filename, index=False)
# 发送报表到邮箱
send_mail(
subject=f"文章访问统计报表({date_range})",
message="您好,附件为文章访问统计报表,请查收!",
from_email=settings.DEFAULT_FROM_EMAIL,
recipient_list=[email],
fail_silently=False,
attachments=[(filename, open(filename, 'rb'), 'application/vnd.openxmlformats-officedocument.spreadsheetml.sheet')]
)
return f"报表已发送到{email}"
步骤 6:视图中调用任务(article/views.py)
from django.shortcuts import render, redirect
from django.http import JsonResponse
from .models import Article
from .tasks import send_article_notification, export_article_statistics
def publish_article(request):
if request.method == 'POST':
title = request.POST.get('title')
content = request.POST.get('content')
author = request.user
# 创建文章
article = Article.objects.create(title=title, content=content, author=author)
# 获取订阅者邮箱(模拟数据)
subscriber_emails = ['user1@example.com', 'user2@example.com']
# 异步发送通知(不阻塞当前请求)
send_article_notification.delay(article.id, subscriber_emails)
return redirect('article_detail', article_id=article.id)
return render(request, 'publish_article.html')
def export_statistics(request):
if request.method == 'POST':
date_range = request.POST.get('date_range') # 格式:20251101-20251107
email = request.POST.get('email')
# 异步导出报表
task = export_article_statistics.delay(date_range, email)
return JsonResponse({
'status': 'success',
'task_id': task.id,
'message': '报表正在生成,将发送到您的邮箱'
})
return render(request, 'export_statistics.html')
步骤 7:启动服务
# 启动Redis
redis-server
# 启动Celery Worker
celery -A myblog worker -l INFO
# 启动Django服务
python manage.py runserver
此时用户发布文章后,页面会立即跳转,邮件发送在后台异步执行;导出报表时,用户可以继续操作其他功能,报表生成完成后会自动发送到邮箱。
6.2 数据处理:Celery 并行处理大数据
数据分析场景中,经常需要处理海量数据(如日志分析、数据清洗),Celery 的并行任务可以充分利用多核 CPU,提升处理效率。
示例:并行清洗用户行为日志
from celery import Celery, group
import pandas as pd
import os
app = Celery(
'data_processing',
broker='redis://localhost:6379/0',
backend='redis://localhost:6379/1'
)
@app.task(name='clean_log_file')
def clean_log_file(file_path):
"""清洗单个日志文件(过滤无效数据、格式化时间)"""
# 读取日志文件(假设格式:时间,用户ID,行为,IP)
df = pd.read_csv(file_path, header=None, names=['time', 'user_id', 'action', 'ip'])
# 数据清洗
df = df.dropna() # 删除空值
df = df[df['user_id'].str.isdigit()] # 过滤无效用户ID
df['time'] = pd.to_datetime(df['time'], errors='coerce') # 格式化时间
df = df.dropna(subset=['time']) # 删除时间格式错误的数据
# 保存清洗后的数据
output_dir = 'cleaned_logs'
os.makedirs(output_dir, exist_ok=True)
output_path = os.path.join(output_dir, os.path.basename(file_path))
df.to_csv(output_path, index=False)
return {
'file': file_path,
'original_rows': len(df) + len(df.dropna()),
'cleaned_rows': len(df),
'output_path': output_path
}
@app.task(name='merge_cleaned_data')
def merge_cleaned_data(results):
"""合并所有清洗后的文件"""
cleaned_files = [result['output_path'] for result in results]
# 合并所有CSV文件
df_list = [pd.read_csv(file) for file in cleaned_files]
merged_df = pd.concat(df_list, ignore_index=True)
# 保存合并结果
merged_path = 'merged_cleaned_logs.csv'
merged_df.to_csv(merged_path, index=False)
# 统计总数据量
total_rows = len(merged_df)
unique_users = merged_df['user_id'].nunique()
return {
'merged_path': merged_path,
'total_rows': total_rows,
'unique_users': unique_users,
'files_processed': len(cleaned_files)
}
def batch_process_logs(log_dir):
"""批量处理日志目录下的所有文件"""
# 获取所有日志文件
log_files = [os.path.join(log_dir, f) for f in os.listdir(log_dir) if f.endswith('.csv')]
# 并行清洗所有文件,然后合并结果(chord:并行任务+回调)
from celery import chord
workflow = chord(
[clean_log_file.s(file) for file in log_files],
merge_cleaned_data.s()
).apply_async()
# 获取最终结果
result = workflow.get()
print(f"处理完成!合并文件:{result['merged_path']},总数据量:{result['total_rows']},独立用户数:{result['unique_users']}")
return result
# 执行批量处理
if __name__ == '__main__':
batch_process_logs('logs')
执行效果:如果logs目录下有 10 个日志文件,每个文件 10 万行数据,串行处理需要 10 分钟,而 Celery 并行处理只需 2 分钟左右(取决于 CPU 核心数),效率提升 5 倍以上。
七、性能调优:让 Celery 跑得更快

7.1 核心调优参数
根据任务类型(I/O 密集型 / CPU 密集型)调整配置,能显著提升性能:
| 参数名称 | 作用 | 推荐值(I/O 密集型) | 推荐值(CPU 密集型) |
|---|---|---|---|
| worker_concurrency(-c) | Worker 并发数 | CPU 核心数 ×5~10 | CPU 核心数 ×1~2 |
| worker_pool(-P) | 并发池类型 | gevent/eventlet | prefork(默认) |
| task_prefetch_multiplier | 任务预取倍数 | 64~128 | 1 |
| worker_max_tasks_per_child | 每个 Worker 处理多少任务后重启 | 1000~5000 | 100~500 |
| worker_max_memory_per_child | 每个 Worker 最大内存限制 | 300MB~1GB | 1GB~2GB |
7.2 调优实践
- I/O 密集型任务(如 API 调用、数据库查询、文件读写):
- 使用 gevent 协程池,提升并发量:
celery -A tasks worker -P gevent -c 200 -l INFO
- 增大预取倍数,减少 Broker 交互开销:
app.conf.task_prefetch_multiplier = 128
app.conf.celery_disable_rate_limits = True # 禁用速率限制(提升吞吐量)
- CPU 密集型任务(如数据计算、加密解密):
- 使用 prefork 池(默认),避免协程切换开销:
celery -A tasks worker -c 4 -l INFO # 并发数=CPU核心数
- 预取倍数设为 1,避免任务阻塞:
app.conf.task_prefetch_multiplier = 1
- 拆分大任务为小任务,并行执行:
# 大任务:计算1~1000000的质数和(耗时久)
# 拆分为10个小任务:每个任务计算10万个数的质数和
- 序列化优化:
- 对于大数据量任务,使用 msgpack 序列化(比 JSON 更快、体积更小):
pip install msgpack
app.conf.accept_content = ('json', 'msgpack')
app.conf.task_serializer = 'msgpack'
app.conf.result_serializer = 'msgpack'
八、总结:Celery 最佳实践
- 选型原则:开发环境用 Redis,生产环境核心业务用 RabbitMQ;
- 任务设计:保持任务幂等性、参数可序列化、拆分长任务;
- 部署规范:用 Supervisor/systemd 管理 Worker/Beat,配置日志和自动重启;
- 监控告警:部署 Flower,监控队列积压、Worker 状态,设置阈值告警;
- 性能调优:根据任务类型调整并发池和参数,I/O 密集型用 gevent,CPU 密集型用 prefork。
Celery 看似复杂,但只要掌握核心概念和避坑要点,就能轻松应对大部分异步和定时任务场景。从个人项目到大型分布式系统,Celery 都能提供稳定、高效的任务处理能力,让你的 Python 程序告别阻塞,性能翻倍。
如果觉得这篇博客有帮助,欢迎点赞、收藏、转发!如果遇到具体问题,欢迎在评论区留言,我会第一时间回复~



















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









