










使用cherry studio创建知识库,连接ollama的bge-m3模型失败,报错404
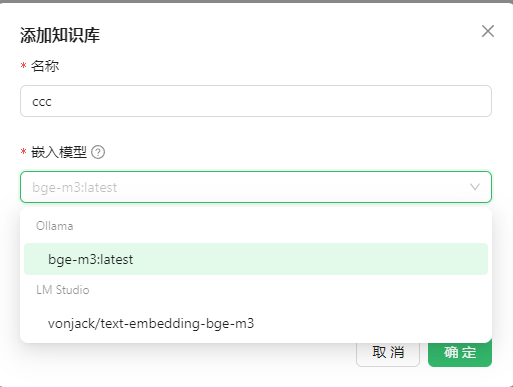
重新安装ollama和cherry studio,版本分别为0.6.2和1.1.18,添加知识库成功不报错
使用cherry studio创建知识库,连接ollama的bge-m3模型失败,报错404
重新安装ollama和cherry studio,版本分别为0.6.2和1.1.18,添加知识库成功不报错
 8327
883
4717
8327
883
4717

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言


























