






 本文指导如何在本地使用LMDeploy部署InternLM-Chat-7B模型,涉及创建conda环境、安装所需包、解决ModuleNotFoundError,以及通过对话、网页和API服务访问模型。
本文指导如何在本地使用LMDeploy部署InternLM-Chat-7B模型,涉及创建conda环境、安装所需包、解决ModuleNotFoundError,以及通过对话、网页和API服务访问模型。
基础作业:
- 使用 LMDeploy 以本地对话、网页Gradio、API服务中的一种方式部署 InternLM-Chat-7B 模型,生成 300 字的小故事(需截图)
这里 /share/conda_envs 目录下的环境是官方未大家准备好的基础环境,因为该目录是共享只读的,而我们后面需要在此基础上安装新的软件包,所以需要复制到我们自己的 conda 环境(该环境下我们是可写的)。
$ conda create -n CONDA_ENV_NAME --clone /share/conda_envs/internlm-base
- 如果clone操作过慢,可采用如下操作:
$ /root/share/install_conda_env_internlm_base.sh lmdeploy
我们取 CONDA_ENV_NAME 为 lmdeploy,复制完成后,可以在本地查看环境。
$ conda env list
结果如下所示。
# conda environments: # base * /root/.conda lmdeploy /root/.conda/envs/lmdeploy
然后激活环境。
$ conda activate lmdeploy
lmdeploy 没有安装,我们接下来手动安装一下,建议安装最新的稳定版。 如果是在 InternStudio 开发环境,需要先运行下面的命令,否则会报错。
# 解决 ModuleNotFoundError: No module named 'packaging' 问题
pip install packaging
# 使用 flash_attn 的预编译包解决安装过慢问题
pip install /root/share/wheels/flash_attn-2.4.2+cu118torch2.0cxx11abiTRUE-cp310-cp310-linux_x86_64.whl
pip install 'lmdeploy[all]==v0.1.0'
直接启动本地的 Huggingface 模型,如下所示。
lmdeploy chat turbomind /share/temp/model_repos/internlm-chat-7b/ --model-name internlm-chat-7b

api访问模型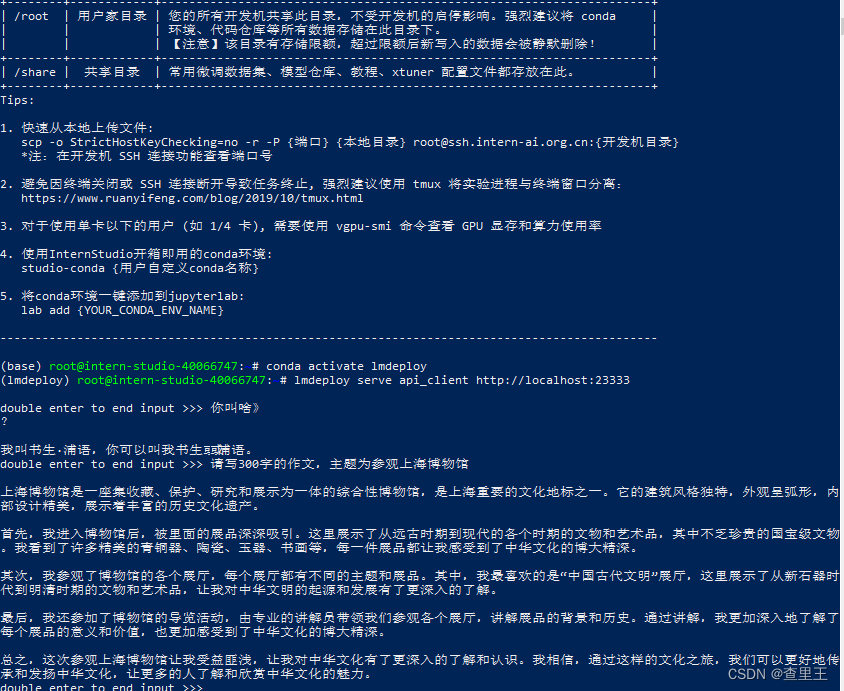
web网页访问



















 582
582

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











