







 本文介绍了使用k近邻(knn)算法进行酒店入住位置预测的过程,涉及数据预处理、欧式距离计算及sklearn库的应用。通过对kaggle上的数据集进行筛选、转换和特征提取,构建并训练knn模型,但注意到该算法在大规模数据上效率较低。
本文介绍了使用k近邻(knn)算法进行酒店入住位置预测的过程,涉及数据预处理、欧式距离计算及sklearn库的应用。通过对kaggle上的数据集进行筛选、转换和特征提取,构建并训练knn模型,但注意到该算法在大规模数据上效率较低。
思想:
计算,预测样本,和其他样本之间的欧式距离,然后欧式距离最短的这些样本的目标值,认为是预测样本的目标值。
欧式距离:对应特征值相减,求平方和再开方
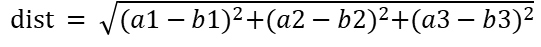
在应用算法 之前 要做标准化。不然值分布在0-1w 范围的特征 对欧式距离的影响太大, 值分布在0-10的特征对距离的影响忽略不计了
api:
from sklearn.neighbors import KNeighborsClassifier
案例:


数据:https://www.kaggle.com/c/facebook-v-predicting-check-ins
特征值
row_id , x , y , accuracy, time,
样本序号,x坐标,y坐标,定位准确度,格林威治时间
目标值:
place_id
入住酒店的id
大概流程:
读取csv,
条件筛选: xy 大于0 小于5
定位准确率低于70的 pass
Time转时间戳
时间戳 分离出 年 月日 时分秒
删除时间戳 ,
删除样本序号。
签到次数低于 50次的酒店pass
训练模型
涉及到几个api
格林威治时间是从1970年1月1日开始累计的秒数的总和.
t = 1551966534
pd.to_datetime(t, unit='s')
输出:
Timestamp('2019-03-07 13:48:54') # 转为时间戳
时间戳字典的使用,可以把时间戳列表 提取出 年,月,日的部分
import pandas as pd
def a():
t = ['2019/3/3','2018/4/3','2017/5/3']
a = []
for i in t:
c = pd.to_datetime(i)
a.append(c)
print(a)
time = pd.DatetimeIndex(a)
print(time.year)
print(time.month)
print(time.day)
a 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 684
684

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









