







 本文详细介绍了线性回归的理论基础,包括中心极限定理和最大似然估计。通过推导展示了最小二乘法的由来,解释了为什么在实际操作中不常用最小二乘法,并提供了线性回归参数θ的解析式。
本文详细介绍了线性回归的理论基础,包括中心极限定理和最大似然估计。通过推导展示了最小二乘法的由来,解释了为什么在实际操作中不常用最小二乘法,并提供了线性回归参数θ的解析式。
机器学习-线性回归理论推导-最小二乘法理论推导
0.概述
在统计学中,线性回归(Linear regression)是利用称为线性回归方程的最小二乘函数对一个或多个自变量和因变量之间关系进行建模的一种回归分析。这种函数是一个或多个称为回归系数的模型参数的线性组合。只有一个自变量的情况称为简单回归,大于一个自变量情况的叫做多元回归。 ——维基百科
从最简单的只有一个自变量的简答回归来看:
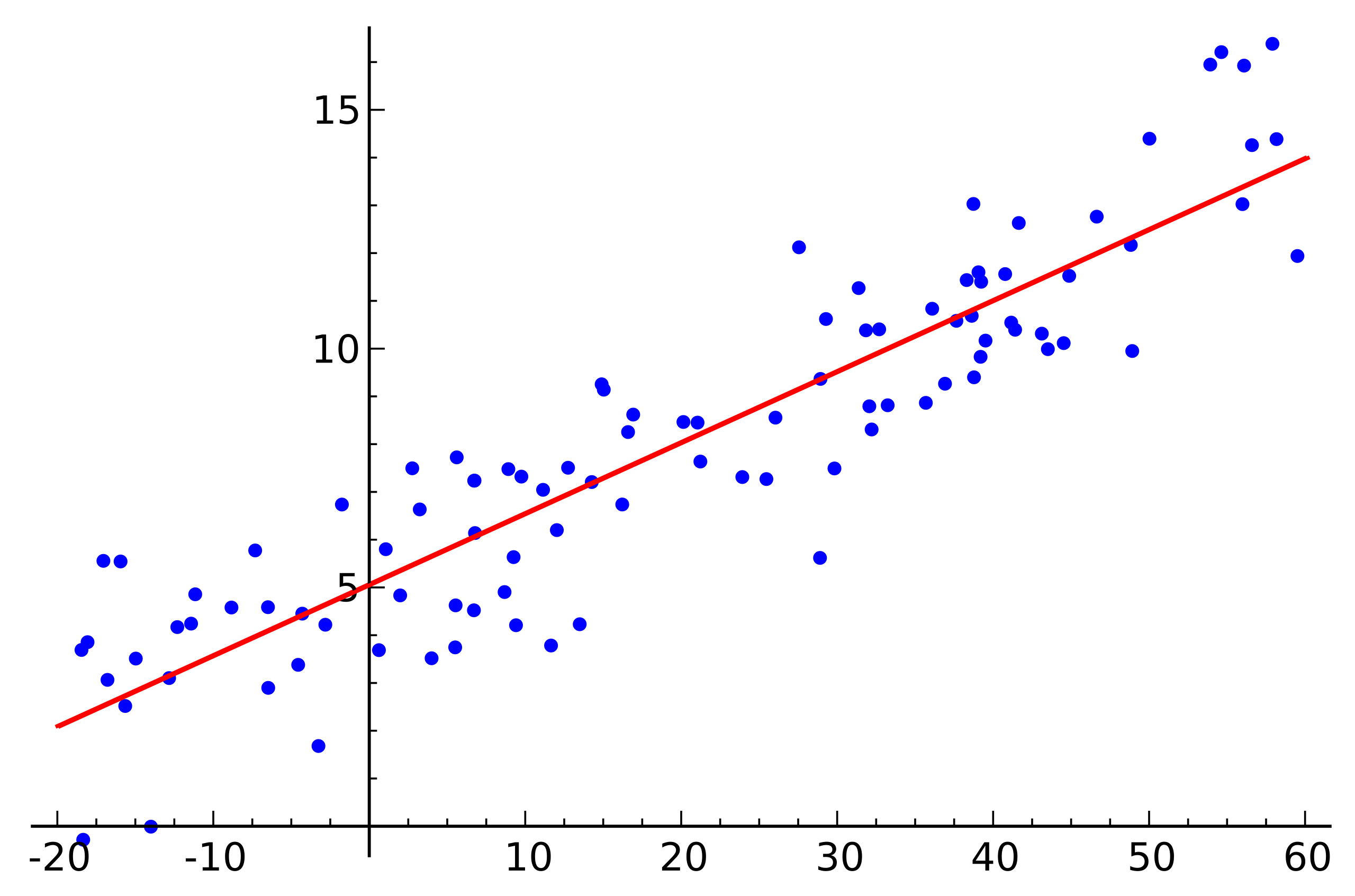
蓝点为实际样本,红线为线性预测函数,对于任意给定新的样本自变量即可按照线性预测函数进行因变量 y y y的预测。直观理想情况下,样本"应该是"均匀分布在预测函数两侧,红色预测函数从蓝色样本"居中"位置穿过去。
下面进行从理论实现对上述"直观感觉"的推导
1.线性回归理论推导
- 预备定理
- 中心极限定理
设随机变量 X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X1,X2,…,Xn互相独立,服从同一分布,并且具有相同的期望 μ \mu μ和方差 σ 2 \sigma^2 σ2,则随机变量
Y n = ∑ i = 1 n X i − n μ n σ Y_n=\frac{\sum_{i=1}^nX_i - n\mu}{\sqrt{n}\sigma} Yn=nσ∑i=1nXi−nμ
的分布收敛到标准正态分布,即高斯分布。
转化一下,即可得到 ∑ i = 1 n X i \sum_{i=1}^nX_i ∑i=1nXi收敛到正态分布 N ( n μ , n σ 2 ) N(n\mu, n\sigma^2) N(nμ,nσ2)
简言之,当样本量足够大时,样本均值的分布慢慢变成正态分布 - 极大似然估计
设总体分布为 f ( x , θ ) f(x,\theta) f(x,θ), X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X1,X2,…,Xn为该总体采样得到的样本。因为 X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X1,X2,…,Xn独立同分布,因此,对于联合密度函数
L ( X 1 , X 2 , … , X n ; θ 1 , θ 2 , … , θ k ) = ∏ i = 1 n f ( X i ; θ 1 , θ 2 , … , θ k ) L(X_1, X_2, \dots, X_n; \theta_1, \theta_2, \dots, \theta_k)=\prod_{i=1}^{n}f(X_i; \theta_1, \theta_2, \dots, \theta_k) L(X1,X2,…,Xn;θ1,θ2,…,θk)=i=1∏nf(Xi;θ1,θ2,…,θk)
上式中, θ \theta θ被看作固定但待求解的参数;反过来,因为样本已经存在,可以看成 X 1 , X 2 , … , X n X_1,X_2,\dots,X_n X1,X2,…,Xn是固定的, L ( x , θ ) L(x, \theta) L(x,θ)是关于 θ \theta θ的函数,即似然函数。
求 θ \theta θ的值,使得似然函数取极大值,这种方法就是极大似然估计
- 中心极限定理
- 线性回归数学定义
对于 n n n维空间(或者可以通俗的描述为 n n n维特征)的 m m m个样本,每个样本对应一个因变量 y y y,即有 m m m个样本数据如下
( x 1 1 , x 2 1 , … , x n 1 , y 1 ) , ( x 1 2 , x 2 2 , … , x n 2 , y 2 ) , … , ( x 1 m , x 2 m , … , x n m , y m ) (x_{1}^{1},x_{2}^{1},\dots,x_{n}^{1},y^{1}),(x_{1}^{2},x_{2}^{2},\dots,x_{n}^{2},y^{2}),\dots,(x_{1}^{m},x_{2}^{m},\dots,x_{n}^{m},y^{m}) (x11,x21,…,xn1,y1),(x12,x22,…,xn2,y2),…,(x1m,x2m,…,xnm,ym)
在上面样本的基础之上,任意给定一个新样本 ( x 1 x , x 2 x , … , x n x ) (x_{1}^{x},x_{2}^{x},\dots,x_{n}^{x}) (x1x,x2x,…,xnx),如何求得该样本对应的 y x y^x yx呢?如果 y y y是连续的,这就是一个回归问题,如果 y y y是离散的,就是一个分类问题,本文暂讨论回归情况。
(对于本文初自变量只有一维的情况,线性回归目的是求得一条直线( y = a x + b y=ax+b y=ax+b)的方程,需要确定的量有斜率( a a a)和截距( b b b)两个。同理对于n维度自变量的情况,线性回归需要求得的是直线的推广——超平面的方程。此时待确定的依然是斜率和截距两个变量,但此时斜率维数变为 n n n维)
对于上述 m m m个样本,给出线性回归的模型如下
h θ ( x 1 , x 2 , … , x n ) = θ 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n h_\theta(x_{1},x_{2},\dots,x_{n})=\theta_0+\theta_{1}x_{1}+\theta_{2}x_{2}+\dots+\theta_{n}x_{n} hθ(x1,x2,…,xn)=θ0+θ1x1+θ2x2+⋯+θnxn
其中, θ 0 \theta_0 θ0为截距, θ i ( i = 1 , 2 , … , n ) \theta_i(i=1,2,\dots,n) θi(i=1,2,…,n)唯一确定"斜率"(注:超平面使用更多的是法向量,与"斜率"是垂直关系)。为了更加表述更加简洁,我们在截距项上增加一个 x 0 x_0 x0,并且令 x 0 = 1 x_0=1 x0=1,上述线性回归模型可以全等写成
h θ ( x 1 , x 2 , … , x n ) = θ 0 x 0 + θ 1 x 1 + θ 2 x 2 + ⋯ + θ n x n h_\theta(x_{1},x_{2},\dots,x_{n})=\theta_{0}x_{0}+\theta_{1}x_{1}+\theta_{2}x_{2}+\dots+\theta_{n}x_{n} hθ(x1,x2,…,xn)=θ0x0+θ1x1+θ2x2+⋯+θnxn
即
h θ ( x 1 , x 2 , … , x n ) = ∑ i = 1 n θ i x i h_\theta(x_{1},x_{2},\dots,x_{n})=\sum_{i=1}^{n}\theta_{i}x_{i} hθ(x1,x2,…,xn)=
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章



















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









