







图的遍历这一部分,离不开广度优先和深度优先,如果大家已经学过搜索算法的话,这部分将是易如反掌。
文章中不会提太多离散数学中图的专有名词,因为本篇博客只涉及最简单的图的遍历,故以练习题为主,可以理解为深度搜索和广度搜索的另一个方向。
首先如果我要从寝室到教学楼有多条路径,怎么才能找到最短的那个呢?这个问题就可以通过图来解决。
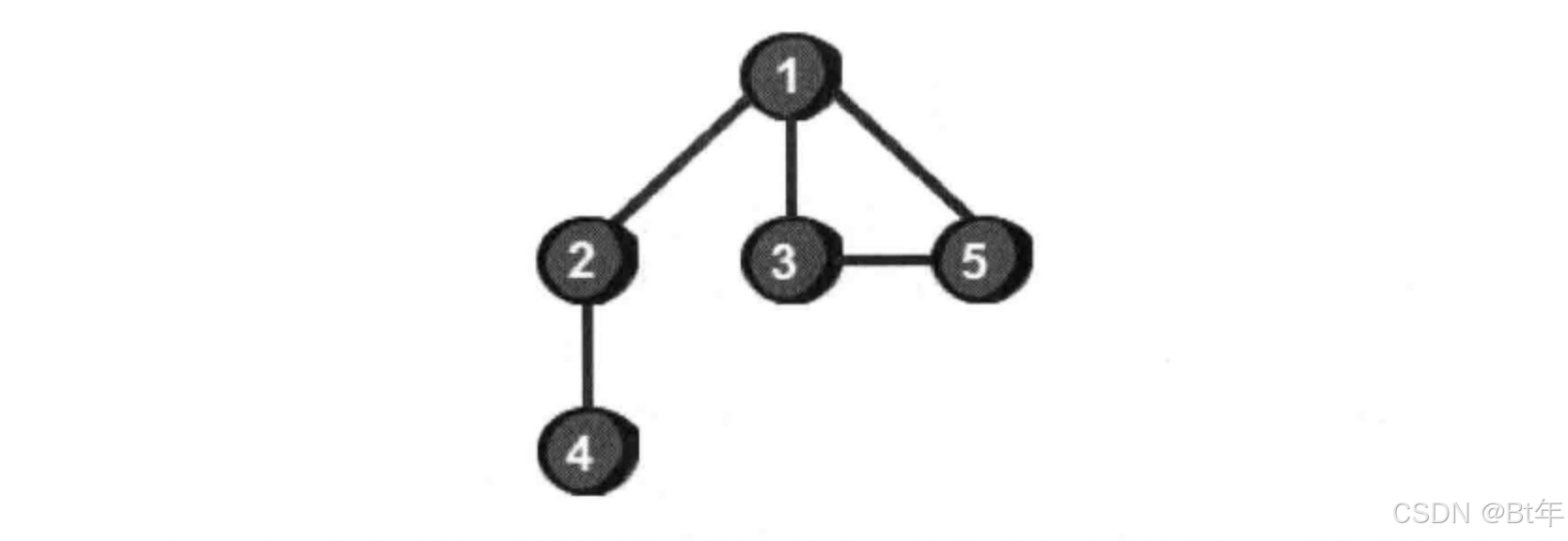
这是一个无向图,图由边和点来组成 ,如果我们要想从1开始遍历这个图的话,程序怎么写呢?
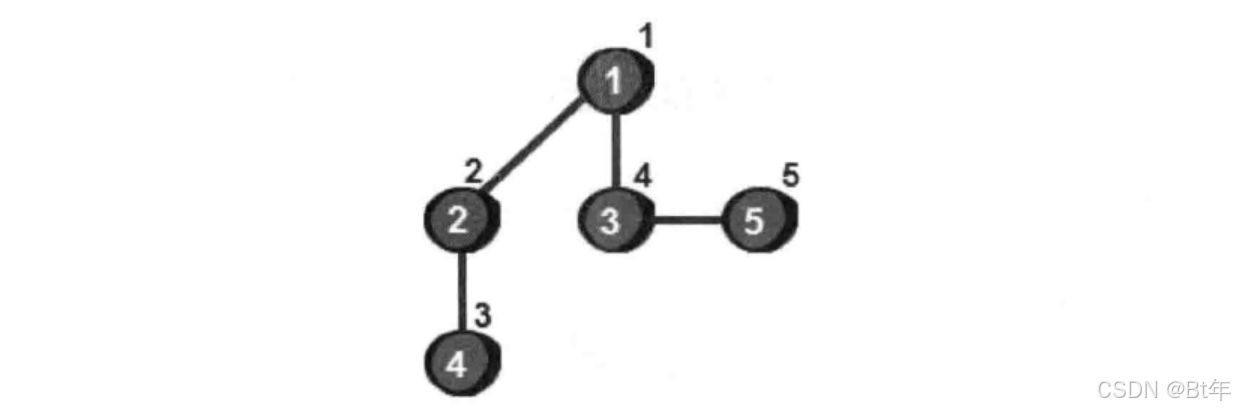
从图中我们可以看到有五个顶点和五条边,按照深度优先搜索的算法来写的话,可以规定一个方向从左到右搜索,那么顺序就是1-2-4-3-5,我们给上边的图加上时间戳,如下:
那么我们在程序中如何表达这个图呢?可以用二维数组来表示,比如1到2的边就是:map[1][2],2到1的边就是map[2][1],我们可以画出这道题的图形:
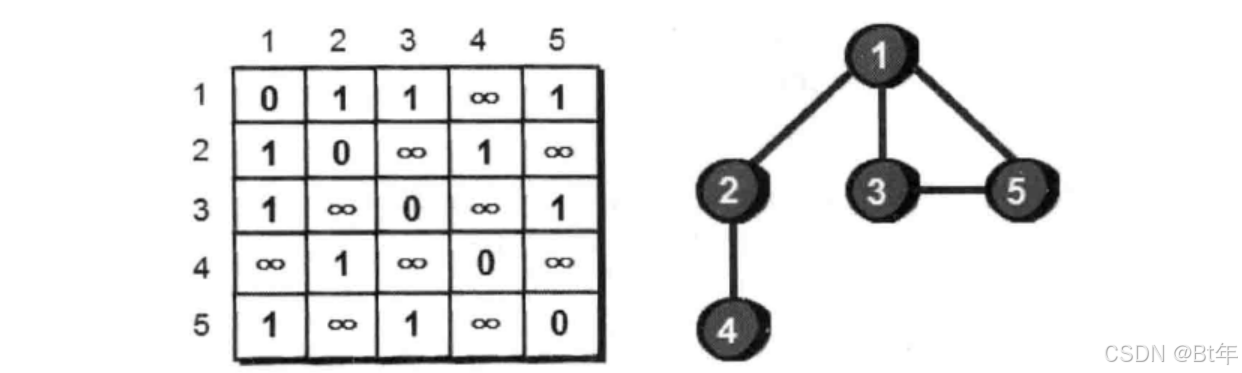
例一:图的遍历(dfs)
接下来我们写出这道题深度优先搜索的代码:
输入格式
我们输入n,m分别代表顶点个数和边的个数。
输出格式
按访问顺序输出顶点
输入样例
5 5
1 2
1 3
1 5
2 4
3 5
输出样例
1 2 4 3 5
针对这道题,需要设计一下二维数组的存储,因为每个边的权重是一样的,所以我们把map[i][j]等于一个定值,不存在的边为一个定值,还有指向本身的(i=j)为一个定值:
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i==j)
map[i][j]=0;
else
map[i][j]=99999;
}
for (int i = 0; i < m; i++)
{
scanf("%d%d",&a,&b);
map[a][b]=1;
map[b][a]=1;//有向图省略
}这样便创建了一个如上图所示的二维数组。dfs函数的结束条件可以为n个顶点全部遍历。完整代码如下:
#include<stdio.h>
int map[50][50]={0};
int book[50]={0};
int n,m,a,b;
int sum=0;
void dfs(int step)
{
printf("%d ",step);//n个顶点全部遍历
sum++;
if (sum==n)
{
return ;
}
for (int i = 1; i <= n; i++)
{
if (map[step][i]==1 && book[i]==0)
{
book[i]=1;
dfs(i);
}
}
return ;
}
int main()
{
scanf("%d%d",&n,&m);
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i==j)
map[i][j]=0;
else
map[i][j]=99999;
}
for (int i = 0; i < m; i++)
{
scanf("%d%d",&a,&b);
map[a][b]=1;
map[b][a]=1;//有向图省略
}
book[1]=1;
// printf("in dfs\n");
dfs(1);
return 0;
}广度优先搜索做法
五个顶点被访问顺序: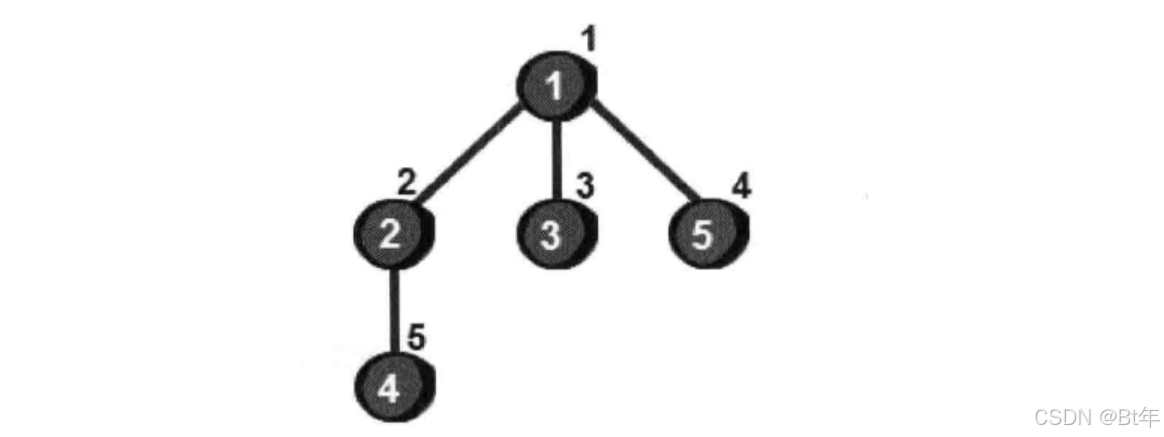
输入样例
5 5
1 2
1 3
1 5
2 4
3 5
输出样例
1 2 3 5 4
没什么难度,这里也是直接上代码:
#include<stdio.h>
int map[50][50]={0};
int book[50]={0};
int n,m,a,b;
int sum=0;
struct queue
{
int data[100]; //队列的主体,用来排队
int head; //队首
int tail; //队尾
};
int main()
{
struct queue q;
q.head = 1;
q.tail = 1;
scanf("%d%d",&n,&m);
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i==j)
map[i][j]=0;
else
map[i][j]=99999;
}
for (int i = 0; i < m; i++)
{
scanf("%d%d",&a,&b);
map[a][b]=1;
map[b][a]=1;//有向图省略
}
q.data[q.tail++]=1;
book[1]=1;
while (q.head<q.tail)
{
for (int j = 1; j <= n; j++)
{
if (map[q.head][j]==1&&book[j]==0)
{
q.data[q.tail++]=j;
book[j]=1;
}
}
printf("%d ",q.data[q.head]);
q.head++;
}
return 0;
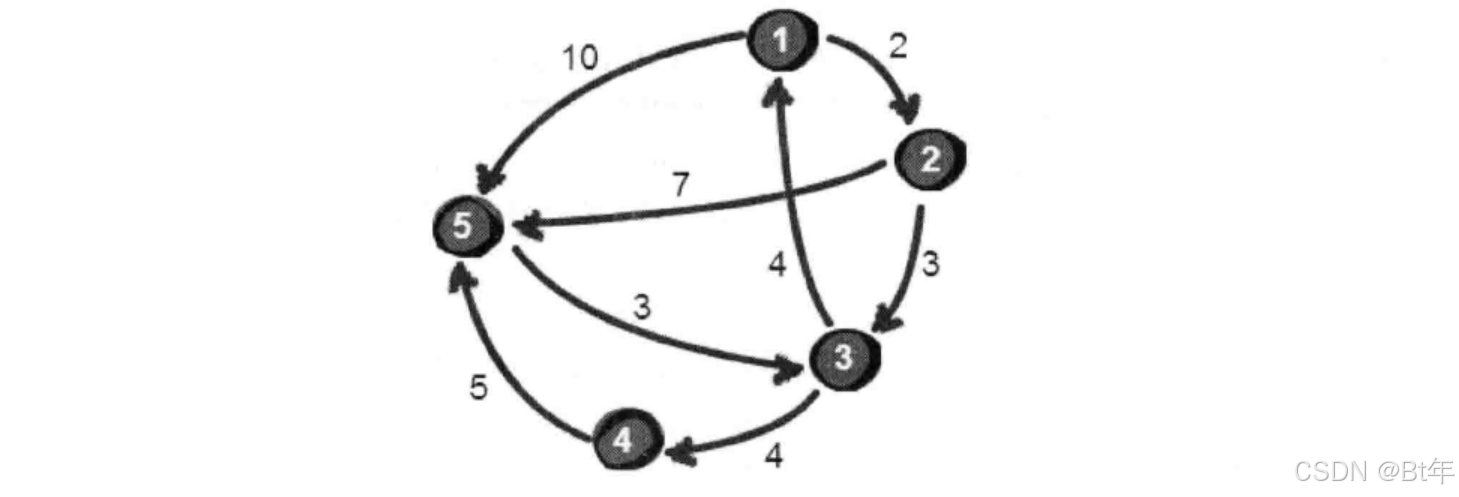
}例二:城市地图(深度优先搜索)
从城市1到城市5的最短路径。
输入格式
共输入m+1行,第一行输入n,m分别代表城市个数和边的个数。
接下来的m行每行包含a,b,num代表从a城市到b城市的路径长度为num。
输出格式
输出最短路径
输入样例
5 8
1 2 2
1 5 10
2 3 3
2 5 7
3 1 4
3 4 4
4 5 5
5 3 3
输出样例
min=9
与例一相比,首先它是有向图,我们只要坚信通过搜索算法可以的到所有路径,就只需要判断最短路径就行了,和第一题的代码大差不差,就是需要加上最短路径判断而已。
我们通过同样的方法得到二维数组,注意这里是有向图:
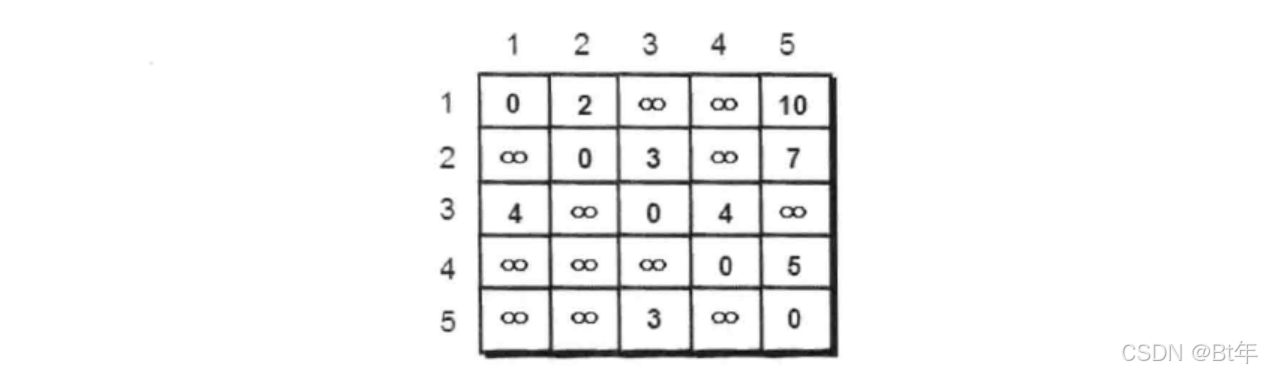
完整代码如下:
#include<stdio.h>
int map[50][50]={0};
int book[50]={0};
int n,m,a,b,num;
int min=99999;
void dfs(int step,int sum)
{
// printf("%d\n",step);
if (sum>min) return ;
if (step==n)
{
if (sum<min)
{
min=sum;
}
return ;
}
for (int i = 1; i <= n; i++)
{
if (map[step][i]!=99999 && book[i]==0)
{
book[i]=1;
sum+=map[step][i];
dfs(i,sum);
book[i]=0;
}
}
return ;
}
int main()
{
scanf("%d%d",&n,&m);
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i==j)
map[i][j]=0;
else
map[i][j]=99999;
}
for (int i = 0; i < m; i++)
{
scanf("%d%d%d",&a,&b,&num);
map[a][b]=num;
}
book[1]=1;
// printf("in dfs\n");
dfs(1,0);
printf("min=%d",min);
return 0;
}例三:最少转机(广度优先搜索)
从1号城市到5号城市,没有直飞的航线,现在需要你找出最少的转机次数,与上一题相比,就是从最短边到最少顶点的变化而已,其它的都没有区别:
输入格式
共输入m+1行,第一行输入n,m,start,end分别代表城市个数、边的个数、起始城市、结束城市。
接下来的m行每行包含a,b,num代表从a城市到b城市的路径长度为num。
输出格式
输出最少转机次数
输入样例
5 7 1 5
1 2
1 3
2 3
2 4
3 4
3 5
4 5
输出样例
sum=2
那么我们这道题用广度搜索最方便,每一层为一次,第一次到达5号城市便是最短的转机次数(广度优先搜索是扩散)。我们在队列中再加一个变量转机次数:
struct queue
{
int data[100]; //队列的主体,用来排队
int head; //队首
int tail; //队尾
int s[100]; //转机次数
};完整代码如下:
#include<stdio.h>
#include<stdbool.h>
struct queue
{
int data[100]; //队列的主体,用来排队
int head; //队首
int tail; //队尾
int s[100]; //转机次数
};
int main()
{
bool flag=false;
int map[50][50]={0};
int book[50]={0};
int n,m,a,b,start,end;
int sum=0;
struct queue q;
q.head = 1;
q.tail = 1;
scanf("%d%d%d%d",&n,&m,&start,&end);
for (int i = 0; i < n; i++)
for (int j = 0; j < n; j++)
{
if (i==j)
map[i][j]=0;
else
map[i][j]=99999;
}
for (int i = 0; i < m; i++)
{
scanf("%d%d",&a,&b);
map[a][b]=1;
map[b][a]=1;//有向图省略
}
q.data[q.tail++]=start;
q.s[start]=0;
book[start]=1;
while (q.head<q.tail)
{
// q.s[q.head]++;
for (int j = 1; j <= n; j++)
{
if (map[q.head][j]==1&&book[j]==0)
{
q.data[q.tail++]=j;
q.s[j]=q.s[q.head]+1;
book[j]=1;
if (q.data[q.tail-1]==end)
{
flag=true;
printf("sum=%d\n",q.s[q.tail-1]);
break;
}
}
}
if (flag==true)
{
break;
}
// printf("%d ",q.data[q.head]);
q.head++;
}
return 0;
}广度和深度的选择
本博客中例二、例三用不同的方法,那么这个是怎么选择的呢?看边的权重,广度优先搜索适合边权重相同的问题。

















 4912
4912

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









