



一。单核实现并发的效果
必备知识点:
并发:看起来像同时运行的成为并发
并行:真正意义上的同时运行
ps:并行肯定算并发
单核的计算机肯定不能实现并行,丹斯可以实现并发。
二。多道技术图解
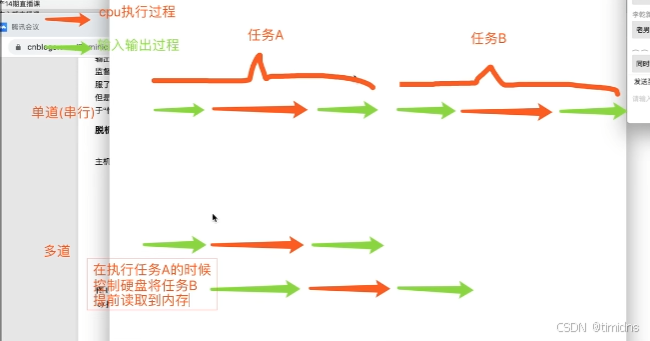
多道技术重点
空间上的复用和时间上的复用
空间上的复用:
多个程序公用一套计算机硬件
时间上的复用:
例子:洗衣服30s,做饭50s,烧水30s
单道需要110s,多道只需要任务最长的那一个
切换加保存状态
切换cpu分为两种状态
1.但一个程序遇到IO操作时,操作系统回剥夺该程序的cpu执行权限
作用:提高了cpu的利用率,并且也不影响程序的执行效率。
2.当一个程序长时间占用cpu的时候,操作系统也惠伯多该程序的cpu执行权限
作用:降低了程序的执行效率(原本时间+切换时间)
进程理论
必备知识点
程序和进程的区别
程序就是一堆躺在硬盘上的代码,是死的
进程则表示程序正在执行的过程,是活的
进程调度
先来先服务算法
对长作业有利,对短作业无益
短作业优先算法
对短作业有利,对长作业无益
时间片轮转算法+多级反馈队列
进程三状态图
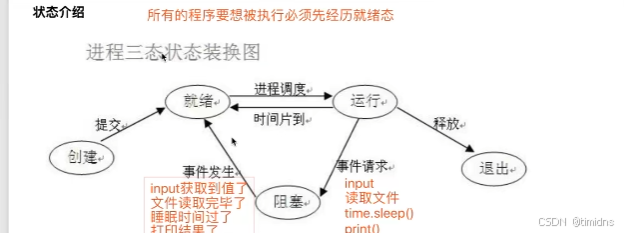
阻塞状态后进入就绪态而非运行态
实例

两对重要概念
同步和异步
描述的是任务的提交方式
同步:任务提交之后,原地等待任务的返回结果,等待的过程中不做任何事(干等),程序层面上表现出来的感觉就是卡住了
异步:任务提交之后,不愿地等待任务的返回结果,直接去做其他事情
提交的结果如何获取:任务的返回结果会有一个异步回调机制自动处理
阻塞非阻塞
描述的是程序的运行状态
阻塞:阻塞态
非阻塞:就绪态,运行态
上述概念的组合:最高效的一种组合就是异步非阻塞
开启进程的两种方式
from multiprocessing import Process
import time
def task(name):
print('%s is running...' % name)
time.sleep(2)
print('%s is done.' % name)
if __name__ == '__main__':
#创建一个子进程对象
p = Process(target=task, args=('abc',))
#开启进程 告诉操作系统帮你创建一个进程
p.start()
print("hahaha")
# hahaha
# abc is running...
# abc is done.
#第二种方法 类的继承
from multiprocessing import Process
import time
class MyProcess(Process):
def run(self):
print("hello aaa")
time.sleep(2)
print("hello bbb")
if __name__ == '__main__':
p = MyProcess()
p.start()
print("hahaha")
# hahaha
# hello aaa
# hello bbb
创建进程就是在内存中申请一块内存空间将需要运行的代码丢进去
一个进程对应在内存中就是一块独立的内存空间
多个进程对应在内存中就是对快独立的内存空间
进程与进程之间默认情况下数据是无法直接交互的
join方法
join是让主进程等待子进程代码运行结束之后,在继续运行,不影响其他子进程的执行
join 方法会阻塞调用它的进程,直到被调用的进程终止。这可以确保主进程在子进程完成之前不会继续执行
from multiprocessing import Process
import time
def task(name):
print('%s is running...' % name)
time.sleep(2)
print('%s is done.' % name)
if __name__ == '__main__':
#创建一个子进程对象
p = Process(target=task, args=('abc',))
#开启进程 告诉操作系统帮你创建一个进程
p.start()
p.join() #主进程在等待子进程p运行结束之后在继续往后执行
print("hahaha")
# abc is running...
# abc is done.
# hahaha
from multiprocessing import Process
import time
def task(name):
print('%s is running...' % name)
time.sleep(2)
print('%s is done.' % name)
if __name__ == '__main__':
# #创建一个子进程对象
# p1 = Process(target=task, args=('aaa',))
# p2 = Process(target=task, args=('bbb',))
# p3 = Process(target=task, args=('ccc',))
#
#
# #开启进程 告诉操作系统帮你创建一个进程
# p1.start()
# p2.start()
# p3.start()
# p1.join()
# p2.join()
# p3.join()#主进程在等待子进程p运行结束之后在继续往后执行
start = time.time()
p_lsit = []
for i in range(1,4):
p = Process(target=task, args=('子进程%s'%i,))
p.start()
p_lsit.append(p)
for p in p_lsit:
p.join()
print("hahaha", time.time() - start)
# abc is running...
# abc is done.
# hahaha
进程之间数据相互隔离
from multiprocessing import Process
a = 100
def task():
global a
a = 666
print("子进程",a)
if __name__ == '__main__':
p = Process(target=task)
p.start()
p.join()
print(a)
#
# 子进程 666
# 100
进程对象及其方法
一台计算机上面运行着很多进程,那么计算机是如何区分管理这些进程服务端呢
计算机会给每一个运行的进程分配一个pid
查看:
windows tsklist 列出所有进程
tasklist /FI "PID eq 9464" 列出特定 PID 的进程
tasklist /FI "IMAGENAME eq notepad.exe" 列出特定进程名的进程
from multiprocessing import Process, current_process
current_process().pid #查看当前进程
import os
os.getpid() #查看当前进程
os.getppid() #查看当前进程的父进程的pid号
p.terminate() #杀死当前进程
僵尸进程和孤儿进程
僵尸进程:
死了但没死透,当你开设了进程之后,该进程死后不会立刻释放占用的进程号
回收子进程占用的pid号
父进程等待子进程运行结束
父进程调用join方法
守护进程
import time
from multiprocessing import Process
def task(name):
print("%s 正在活着" % name)
time.sleep(2)
print("%s 正在死亡" % name)
if __name__ == '__main__':
p = Process(target=task,args=('zhangsan',))
p.daemon = True
#将进程p设置为守护进程,这一句一定要放在start方法上面才有效否则报错
#AssertionError: process has already started
p.start()
print("主进程运行完了")
孤儿进程
子进程存活,父进程意外死亡
操作系统会开设一个儿童福利院()专门管理孤儿进程回收相关资源
互斥锁
多个进程同时操作一份数据时,回出现数据错乱的情况
针对上述问题,解决方式是枷锁处理,经并发编程串行,牺牲效率,但是保证数据的安全
当没有互斥锁时:
import json
import random
import time
from multiprocessing import Process, Lock
def search(i):
#文件操作读取票数
with open("data",'r',encoding='utf-8') as f:
data = json.load(f)
print('用户{}查询余票: {}'.format(i, data.get('ticket_num')))
def buy(i):
with open("data",'r',encoding='utf-8') as f:
data = json.load(f)
#模拟网络延迟
time.sleep(random.randint(1,3))
#查询是否有票
if data.get('ticket_num') == 0:
print('用户%s购票失败,票已售罄' % i)
return
data['ticket_num'] = data['ticket_num'] - 1
#写回数据库
with open("data",'w',encoding='utf-8') as f:
json.dump(data,f)
print('用户%s购票成功' % i)
def run(i):
search(i)
buy(i)
if __name__ == '__main__':
for i in range(1,3):
p = Process(target=run, args=(i,))
p.start()
# 用户1查询余票: 1
# 用户2查询余票: 1
# 用户1购票成功
# 用户2购票成功
#data :{"ticket_num": 0}
没有互斥锁时只有一张票,但是用户一和用户二都购票成功,是因为两个进程同时访问数据,导致进程在修改前被多进程访问
加互斥锁:
import json
import random
import time
from multiprocessing import Process, Lock
def search(i):
#文件操作读取票数
with open("data",'r',encoding='utf-8') as f:
data = json.load(f)
print('用户{}查询余票: {}'.format(i, data.get('ticket_num')))
def buy(i):
with open("data",'r',encoding='utf-8') as f:
data = json.load(f)
#模拟网络延迟
time.sleep(random.randint(1,3))
#查询是否有票
if data.get('ticket_num') == 0:
print('用户%s购票失败,票已售罄' % i)
return
data['ticket_num'] = data['ticket_num'] - 1
#写回数据库
with open("data",'w',encoding='utf-8') as f:
json.dump(data,f)
print('用户%s购票成功' % i)
def run(i,mutex):
search(i)
#给买票环节加锁处理
#抢锁
mutex.acquire()
buy(i)
#释放锁
mutex.release()
if __name__ == '__main__':
#在主进程生成一把锁,让所有的子进程抢,谁先抢到谁先买票
mutex = Lock()
for i in range(1,3):
p = Process(target=run, args=(i,mutex))
p.start()
# 用户1查询余票: 1
# 用户2查询余票: 1
# 用户1购票成功
# 用户2购票失败,票已售罄
#data :{"ticket_num": 0}
队列
from multiprocessing import Queue
q = Queue() #括号内可以放数字来限制队列的大小
q.put() #放数据 当队列满了再放时阻塞
q.get() #取数据 当队列空了再取时阻塞
q.full() #判断队列是否满了
q.empty() #判断队列是否空了
q.get_nowait() #取数据时如果没有数据不再阻塞直接报错
q.get(timeout=10) #取数据时如果没有数据阻塞10秒,如果还没有数据就报错
进程间通信:
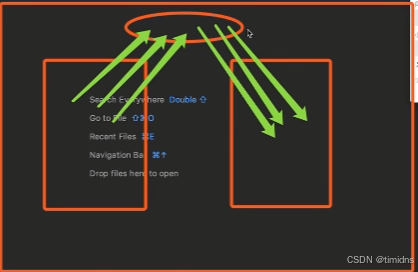
一方向消息队列传入数据,一方从消息队列读数据
父进程与子进程进行通信
from multiprocessing import Process, Queue
def producer(q):
q.put("我是你爸爸")
print("hello")
if __name__ == '__main__':
q = Queue()
p = Process(target=producer, args=(q,))
p.start()
print(q.get())
# hello
# 我是你爸爸
子进程 往消息队列传入数据"我是你爸爸",父进程从消息队列读取数据
子进程与子进程进行通信
from multiprocessing import Process, Queue
def producer(q):
q.put("我是你爸爸")
print("hello")
def consumer(q):
print(q.get())
if __name__ == '__main__':
q = Queue()
p = Process(target=producer, args=(q,))
p1 = Process(target=consumer, args=(q,))
p.start()
p1.start()
# hello
# 我是你爸爸
子进程p向消息队列传入"我是你爸爸",子进程p1从消息队列中读出数据“我是你爸爸”
线程理论
什么是线程
进程:资源单位
线程: 执行单位
将操作系统比做成一个工厂,那么进程就相当于工厂里面的车间,而新城就是车间里面的流水线
每一个进程自带一个线程
总结:创建一个进程仅仅只是再内存空间中开辟一块独立的空间,线程是执行单位,真正被cpu执行的其实是进程里面的线程买现成指的是代码的执行过程,执行代码中所需使用的资源都到所在进程中索要。
为何要线程
开设进程
1.申请内存空间 消耗资源
2.“拷贝代码” 消耗资源
开线程
一个进程内可以开设多个线程,在用一个进程内开设多个线程无需再次申请内存空间操作。
总结:开设线程的开销要演员的小于进程的开销
开启进程的两种方式
import time
from multiprocessing import Process, Queue
from threading import Thread
def task(name):
print("%s is running\n" %name)
time.sleep(2)
print("%s is done" %name)
t = Thread(target=task,args=("二狗",))
t.start()
print("主")
# 二狗 is running
# 主
#
# 二狗 is done
class MyThread(Thread):
def __init__(self, name):
super().__init__()
self.name = name
def run(self):
print("%s is running\n" % self.name)
time.sleep(2)
print("%s is done" %self.name)
if __name__ == '__main__':
t = MyThread("二狗")
t.start()
print("主")
# 二狗 is running
# 主
# 二狗 is done
tcp通信中的并发服务
server
import socket
from multiprocessing import Process
from threading import Thread
import time
server = socket.socket()
server.bind(('127.0.0.1', 9999))
server.listen(5)
def server(conn):
while True:
try:
data = conn.recv(1024)
if len(data) == 0:
break
print(data)
conn.send(data)
except ConnectionResetError as e:
print(e)
break
conn.close()
while True:
conn, addr = server.accept()
t = Thread(target=server, args=(conn,))
t.start()
print(addr)
client
import socket
client = socket.socket()
client.connect(('127.0.0.1', 9999))
while True:
client.send(bytes('Hello, client!', 'utf-8'))
data = client.recv(1024)
print(data)
线程中的join方法
主线程等子线程运行完之后再结束
import time
from multiprocessing import Process
from threading import Thread
def task(name):
print('%s is running\n' % name)
time.sleep(2)
print('%s is done' % name)
if __name__ == '__main__':
t = Thread(target=task,args=("abc",))
t.start()
t.join()
print("主")
# abc is running
#
# abc is done
# 主
同一个进程下的多个线程的数据是共享的
线程类常用方法
current_thread().name #当前线程的名字
active_count() #活着的线程数
主线程运行结束之后不会立即结束,会等到非守护线程全部结束后在结束
主线程的结束意味着全部线程结束
进程池与线程池
在 Python 中,concurrent.futures 模块提供了 ThreadPoolExecutor 和 ProcessPoolExecutor 两个类,分别用于创建线程池和进程池。这两个类都允许你并发地执行任务,并且支持回调函数。
线程池 (ThreadPoolExecutor)
ThreadPoolExecutor 使用线程来执行任务。线程池适用于 I/O 密集型任务,因为线程在等待 I/O 操作时会释放 GIL(全局解释器锁),从而允许其他线程执行。
基本用法
from concurrent.futures import ThreadPoolExecutor
def task(n):
return n * n
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
results = [future.result() for future in futures]
print(results)
回调函数
回调函数可以在任务完成后自动调用。你可以使用 add_done_callback 方法来添加回调函数。
from concurrent.futures import ThreadPoolExecutor
def task(n):
return n * n
def callback(future):
print(f"Task result: {future.result()}")
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
for future in futures:
future.add_done_callback(callback)
进程池 (ProcessPoolExecutor)
ProcessPoolExecutor 使用进程来执行任务。进程池适用于 CPU 密集型任务,因为每个进程都有自己的 Python 解释器,不会受到 GIL 的限制。
基本用法
from concurrent.futures import ProcessPoolExecutor
def task(n):
return n * n
with ProcessPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
results = [future.result() for future in futures]
print(results)
回调函数
与线程池类似,进程池也支持回调函数。你可以使用 add_done_callback 方法来添加回调函数。
from concurrent.futures import ProcessPoolExecutor
def task(n):
return n * n
def callback(future):
print(f"Task result: {future.result()}")
with ProcessPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
for future in futures:
future.add_done_callback(callback)
回调函数的详细解释
回调函数是一个在任务完成后自动调用的函数。回调函数通常接受一个 Future 对象作为参数,你可以通过这个对象获取任务的结果。
Future 对象
Future 对象表示一个异步计算的结果。它有以下几个重要的方法:
-
result(): 获取任务的返回值。如果任务尚未完成,result()会阻塞直到任务完成。 -
done(): 检查任务是否已完成。 -
add_done_callback(fn): 添加一个回调函数,当任务完成后自动调用该函数。回调函数接受一个Future对象作为参数。
回调函数的优点
-
异步处理: 回调函数允许你在任务完成后立即处理结果,而不需要等待所有任务完成。
-
解耦: 回调函数可以将任务的执行与结果的处理分离,使代码更加模块化和易于维护。
总结
-
线程池 (
ThreadPoolExecutor) 适用于 I/O 密集型任务,使用线程来执行任务。 -
进程池 (
ProcessPoolExecutor) 适用于 CPU 密集型任务,使用进程来执行任务。 -
回调函数 允许你在任务完成后自动处理结果,适用于异步编程和解耦任务执行与结果处理。
通过合理使用线程池和进程池,并结合回调函数,你可以编写出高效且易于维护的并发程序。
with ThreadPoolExecutor(max_workers=5) as executor: futures = [executor.submit(task, i) for i in range(10)] 解释这两句
这两行代码使用了 concurrent.futures 模块中的 ThreadPoolExecutor 来创建一个线程池,并提交多个任务到线程池中执行。下面是对这两行代码的详细解释:
代码解释
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
1. with ThreadPoolExecutor(max_workers=5) as executor:
-
ThreadPoolExecutor: 这是一个用于创建线程池的类。线程池允许你并发地执行多个任务,而不需要手动创建和管理线程。 -
max_workers=5: 这是线程池中最大线程数的参数。在这个例子中,线程池最多可以同时运行 5 个线程。 -
with语句:with语句用于上下文管理。当with块结束时,ThreadPoolExecutor会自动关闭线程池,并等待所有任务完成。这样可以确保线程池在不再需要时被正确清理。
2. futures = [executor.submit(task, i) for i in range(10)]
-
executor.submit(task, i):-
executor.submit方法用于提交一个任务到线程池中执行。 -
task是你要执行的任务函数。 -
i是传递给task函数的参数。 -
executor.submit返回一个Future对象,表示这个任务的执行结果。
-
-
for i in range(10):-
这是一个列表推导式的一部分,用于生成一个包含 10 个
Future对象的列表。 -
range(10)生成一个从 0 到 9 的整数序列。 -
对于每个整数
i,都会提交一个任务task(i)到线程池中执行。
-
-
futures = [...]:-
最终,
futures变量将包含一个包含 10 个Future对象的列表,每个Future对象对应一个提交到线程池中的任务。
-
总结
这两行代码的作用是:
-
创建一个最大线程数为 5 的线程池。
-
提交 10 个任务到线程池中执行,每个任务的参数从 0 到 9。
-
返回一个包含 10 个
Future对象的列表,每个Future对象表示一个任务的执行结果。
示例代码
下面是一个完整的示例代码,展示了如何使用 ThreadPoolExecutor 来并发执行任务,并获取任务的结果:
from concurrent.futures import ThreadPoolExecutor
def task(n):
return n * n
with ThreadPoolExecutor(max_workers=5) as executor:
futures = [executor.submit(task, i) for i in range(10)]
results = [future.result() for future in futures]
print(results)
在这个例子中:
-
task函数计算参数的平方。 -
ThreadPoolExecutor创建一个最大线程数为 5 的线程池。 -
提交 10 个任务到线程池中执行,每个任务的参数从 0 到 9。
-
使用
future.result()获取每个任务的结果,并将结果存储在results列表中。 -
最后,打印
results列表,显示所有任务的结果。
输出结果将是:
[0, 1, 4, 9, 16, 25, 36, 49, 64, 81]
协程与gevent模块
协程是一种用户态的轻量级线程,它允许你在单个线程中实现并发。协程的切换是由程序员控制的,而不是由操作系统调度。协程非常适合处理 I/O 密集型任务,因为它可以在等待 I/O 操作时让出 CPU,从而提高程序的效率。
gevent 是一个基于协程的网络库,它通过 greenlet 来实现协程。gevent 提供了一些工具来简化协程的使用,例如 monkey patching(猴子补丁),它可以自动将标准库中的阻塞 I/O 操作替换为非阻塞的协程版本。
import gevent
from gevent import monkey
# 打补丁,将标准库中的阻塞 I/O 操作替换为非阻塞的协程版本
monkey.patch_all()
import requests
def fetch_url(url):
response = requests.get(url)
print(f"URL: {url}, Content Length: {len(response.text)}")
urls = [
"https://www.example.com",
"https://www.python.org",
"https://www.github.com",
"https://www.stackoverflow.com",
"https://www.wikipedia.org"
]
# 创建多个协程
jobs = [gevent.spawn(fetch_url, url) for url in urls]
# 等待所有协程完成
gevent.joinall(jobs)
解释
-
monkey.patch_all():-
这个函数会自动将标准库中的阻塞 I/O 操作(如
socket、threading、time等)替换为非阻塞的协程版本。这样你就可以在gevent中使用标准库的函数,而不需要修改代码。
-
-
gevent.spawn(fetch_url, url):-
这个函数用于创建一个新的协程,并立即开始执行
fetch_url函数。gevent.spawn返回一个Greenlet对象,表示这个协程。
-
-
gevent.joinall(jobs):-
这个函数用于等待所有协程完成。
jobs是一个包含所有Greenlet对象的列表
-



















 到【灌水乐园】发言
到【灌水乐园】发言








