




Spark可以加载好多种外部数据源的格式,例如:csv,text,json,parquet等。我们在这里讲解下csv和json格式。
一、装载CSV数据源
文件链接
提取码: t4n2
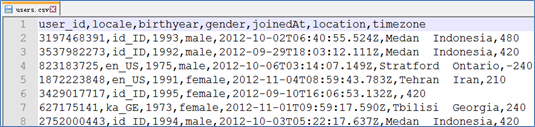
文件预览
使用SparkContext
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("scvdemo")
val sc = new SparkContext(conf)
val lines = sc.textFile("in/users.csv",3)
val fields2 = lines.filter(v=>v.startsWith("user_id")==false).map(_.split(","))
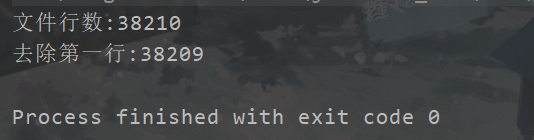
println(fields2.count)
}
- 使用SparkSession
option参数说明:
1. delimiter 分隔符,默认为逗号,
2. nullValue 空值设置,如果不想用任何符号作为空值,可以赋值null即可
3. quote 引号字符,默认为双引号"
4. header 第一行是否不作为数据内容,作为标题(true/false)
5. inferSchema 是否自动推测字段类型(true/false)
6. ignoreLeadingWhiteSpace 是否裁剪前面的空格(true/false)
7. ignoreTrailingWhiteSpace 是否裁剪后面的空格(true/false)
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("scvdemo")
val spark = SparkSession.builder().config(conf).getOrCreate()
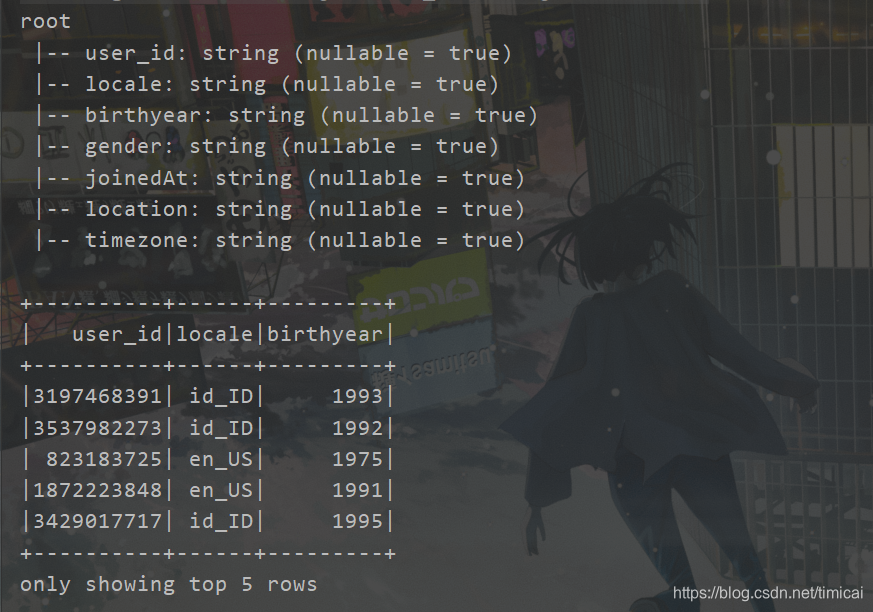
val df = spark.read.format("csv")
.option("header", "true").load("in/users.csv")
//显示表头
df.printSchema()
//显示表数据,show中不加参数默认显示20行
df.select("user_id","locale","birthyear").show(5)
}
- 如果数据没有表头
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("csvdemo2")
val spark = SparkSession.builder().config(conf).getOrCreate()
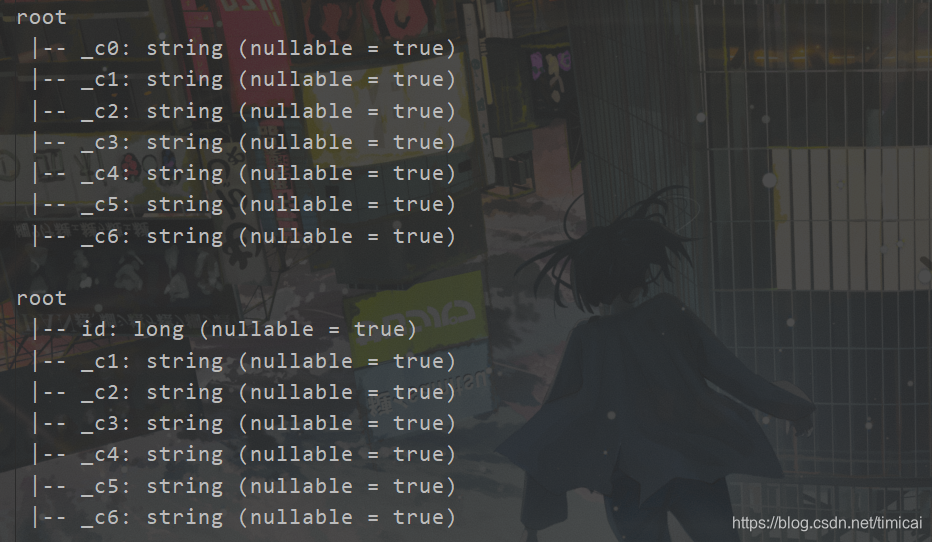
//sparkSession读取csv文件,没有表头信息,header的参数false
val df = spark.read.format("csv").option("header","false").load("in/users2.csv")
df.printSchema()
//修改列名
val df2 = df.withColumnRenamed("_c0","id")
//修改列表数据类型
val df3 = df2.withColumn("id",df2.col("id").cast("long"))
df3.printSchema()
}
改名这里有个坑,下面是一些总结
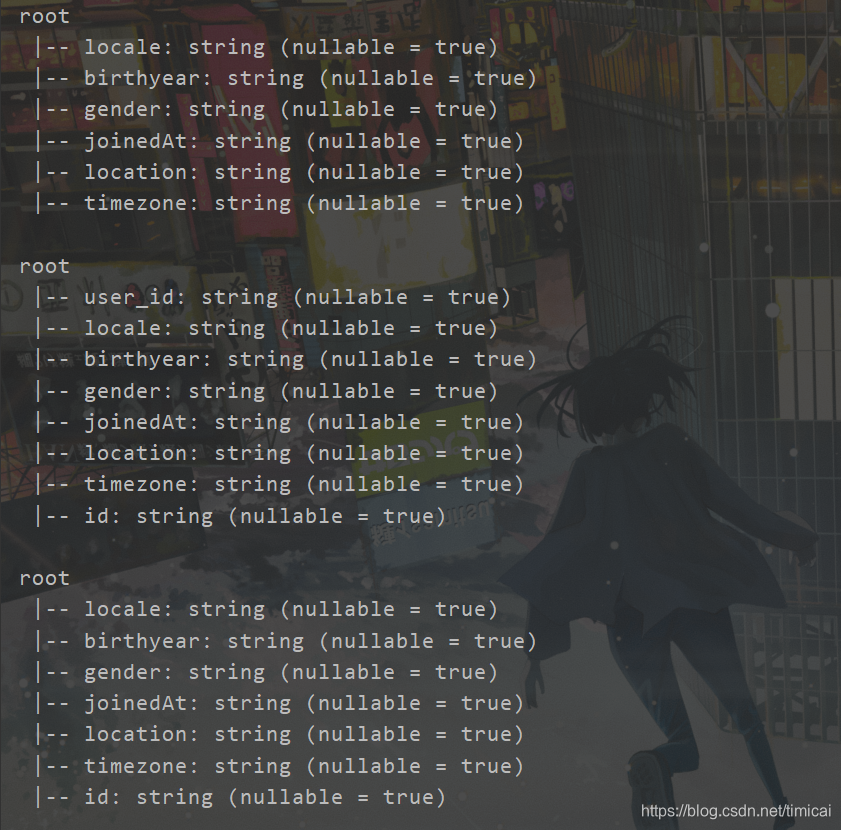
- 列名不区分大小写
对比
//列名修改成全大写
val df2 = df.withColumn("USER_ID",df.col("user_id")).drop("user_id")
df2.printSchema()
//修改成新列名,结果新增一列
val df3 = df.withColumn("id",df.col("user_id"))
df3.printSchema()
//下面将原列删除
val df4 = df.withColumn("id",df.col("user_id")).drop("user_id")
df4.printSchema()
二、装载JSON数据源
- 使用SparkContext
JSON数据解析:
(1)读取JSON格式文件
直接使用sc.textFile(“file://”)来读取.json文件即可
(2)JSON
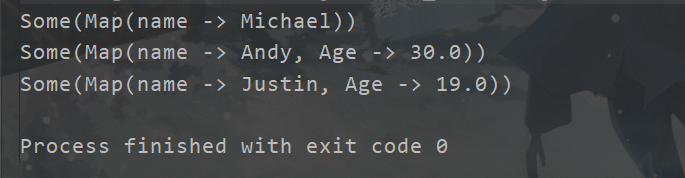
Scala中有一个自带的JSON库 scala.util.parsing.json.JSON 可以 实现对JSON数据解析。
通过调用 JSON.parseFull(jsonString:String) 函数对输入的JSON字符串进行解析,如果解析成功则返回一个 Some( map:Map[String,Any] ) ,失败则返回None
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("jsondemo")
val sc = new SparkContext(conf)
val lines = sc.textFile("in/users.json")
import scala.util.parsing.json._
val rdd = lines.map(x=>JSON.parseFull(x))
rdd.foreach(println)
}
- 使用SparkSession
加载Json格式后,df会自动识别Schema
注:如果Json格式不严谨,sparkSQL能将问题数据解析出来
def main(args: Array[String]): Unit = {
val conf = new SparkConf().setMaster("local").setAppName("jsondemo")
val spark = SparkSession.builder().config(conf).getOrCreate()
val df = spark.read.format("json")
.option("header", "true").load("in/users.json")
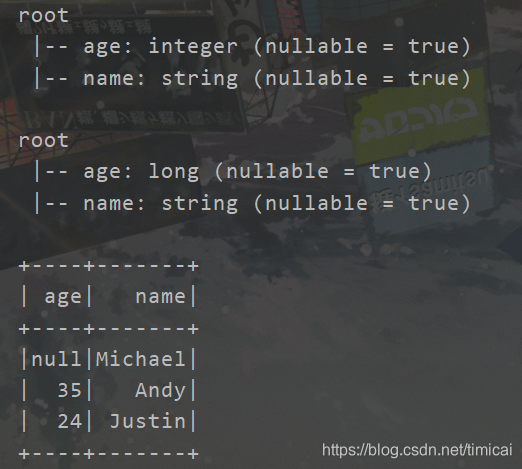
df.printSchema()
//修改列名,json同csv,列名不区分大小写
val df2 = df.withColumnRenamed("Age","age")
df2.printSchema()
df2.select("age","name").show()

//修改列数据类型
val df3 =
df.withColumn("age",df.col("Age").cast("Int"))
df3.printSchema()
//操作数据,将age加 5
val df4 = df.withColumn("age",df.col("Age")+5)
.withColumn("name",df.col("name"))
df4.printSchema()
df4.show
}

















 4975
4975

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









