




 本文详细介绍ZooKeeper分布式服务框架的功能及应用场景,包括安装配置、节点类型、数据一致性的实现方式等,并探讨了单机模式、集群模式和伪集群模式的区别。
本文详细介绍ZooKeeper分布式服务框架的功能及应用场景,包括安装配置、节点类型、数据一致性的实现方式等,并探讨了单机模式、集群模式和伪集群模式的区别。
zookeeper介绍
zookeeper 分布式服务框架是 Apache Hadoop 的一个子项目,它主要是用来解决分布式应用中经常遇到的一些数据管理问题,如:统一命名服务、状态同步服务、集群管理、分布式应用配置项的管理等。本文将从使用者角度详细介绍 Zookeeper 的安装和配置文件中各个配置项的意义,以及分析 Zookeeper 的典型的应用场景(配置文件的管理、集群管理、同步锁、Leader 选举、队列管理等)。
ZooKeeper记录数据的结构与Linux文件系统相似,整体可以看作一棵树,每个节点称ZNode。每个Znode默认能够存储1MB的数据,每个ZNode都可以通过其路径唯一标识。
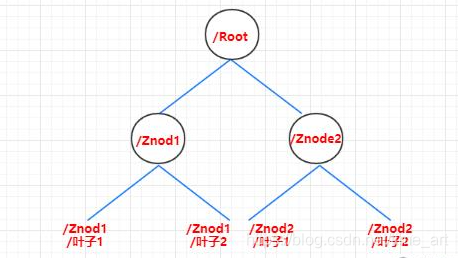
节点类型
短暂(ephemeral):客户端和服务器端断开连接后,创建的节点自动删除。
持久(persistent):客户端和服务器端断开连接后,创建的节点持久化保存。
四种形式的目录节点
-
PERSISTENT-持久化目录节点
客户端与zookeeper断开连接后,该节点依旧存在
-
PERSISTENT_SEQUENTIAL-持久化顺序编号目录节点
客户端与zookeeper断开连接后,该节点依旧存在,只是Zookeeper给该节点名称进行顺序编号
-
EPHEMERAL-临时目录节点
客户端与zookeeper断开连接后,该节点被删除
-
EPHEMERAL_SEQUENTIAL-临时顺序编号目录节点
客户端与zookeeper断开连接后,该节点被删除,只是Zookeeper给该节点名称进行顺序编号
数据一致性
每个server保存一份相同的数据拷贝,客户端无论请求到被集群中哪个server处理,得到的数据都是一致的
zookeeper的安装分为三种模式:单机模式、集群模式和伪集群模式
伪集群:在一台机器同时运行多个ZooKeeper实例
zookeeper的默认三种端口号:
2181:给客户端提供服务的端口
2888: leader和follower之间数据同步使用的端口号
3888:用来选举leader
角色:
zookeeper的三种角色也就是ZK服务器的三种节点类型:领导者(leader),追随者(follower),观察者(observer)
zookeeper选举的规则:leader选举,要求 可用节点数量 > 总节点数量/2
在容错能力相同的情况下,奇数台更节省资源
假如zookeeper集群1 ,有3个节点,3/2=1.5 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要2个节点是正常的。换句话说,3个节点的zookeeper集群,允许有一个节点宕机。
假如zookeeper集群2,有4个节点,4/2=2 , 即zookeeper想要正常对外提供服务(即leader选举成功),至少需要3个节点是正常的。换句话说,4个节点的zookeeper集群,也允许有一个节点宕机。
ZooKeeper的节点有5种操作权限:CREATE(增)、READ(查)、WRITE(改)、DELETE(删)、ADMIN(管理)等
认证方式
- world 默认方式,开放的权限,意解为全世界都能随意访问。
- auth 已经授权且认证通过的用户才可以访问。
- digest 用户名:密码方式认证,实际业务开发中最常用的方式。
- IP白名单 授权指定的Ip地址,和指定的权限点,控制访问。

















 2万+
2万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









