




Quantized Side Tuning: Fast and Memory-Efficient Tuning of Quantized Large Language Models
LoRA 和Adapter
LoRA
假设我们有一个预训练好的大规模语言模型(如BERT),它在大规模语料库上进行了训练,具有强大的语言理解能力。现在我们希望将这个模型应用于一个特定的下游任务,比如情感分析。然而,直接使用预训练模型可能会导致过拟合,同时也不够高效,因为模型的参数量非常大。这时,我们可以使用LoRA技术来进行高效微调。
具体来说,我们在BERT模型的每一层权重矩阵中引入低秩矩阵。例如,在自注意力机制的权重矩阵中,我们将原始权重矩阵W分解为W = W + ΔW,其中ΔW是一个低秩矩阵,可以表示为ΔW = A * B,A和B是两个较小的矩阵。在微调过程中,我们只更新A和B这两个低秩矩阵的参数,而保持原始权重矩阵W不变。这样,我们只需要训练少量的参数,就能使模型适应情感分析任务。通过这种方式,LoRA实现了在保持预训练模型强大能力的同时,对模型进行高效的下采样和微调.
Adapter
假设我们有一个预训练好的图像分类模型,它在大规模图像数据集上进行了训练,能够识别多种物体类别。现在我们希望将这个模型应用于一个特定的图像分类任务,比如识别某种特定类型的花朵。然而,直接使用预训练模型可能无法很好地适应这个特定任务,因为模型的特征提取层可能没有针对这种特定类型的花朵进行优化。这时,我们可以使用Adapter技术来进行模型微调。
具体来说,在预训练模型的每一层中插入一个小型的Adapter模块。例如,在卷积层之后,我们添加一个Adapter模块,它由一个降维层(down-project)、一个非线性激活层和一个升维层(up-project)组成。在训练时,我们固定住预训练模型的参数不变,只对Adapter模块的参数进行微调。通过这种方式,Adapter模块可以学习到针对特定任务的特征表示,而不需要重新训练整个模型。Adapter实现了在保持预训练模型结构的基础上,对模型进行轻量级的下采样和微调.
PEFT (Parameter-Efficient Fine-Tuning) 和 量化 (Quantization)
量化 (Quantization)
量化是一种将模型权重和激活从高精度(如32位浮点数)转换为低精度(如8位整数)的技术。这减少了模型的内存使用和加速了推理过程,尤其是在大型模型上更为有效。常见的量化方法包括 AWQ、GPTQ 和 bitsandbytes 库。
PEFT (Parameter-Efficient Fine-Tuning)
PEFT 是一种在微调大型模型时只更新少量参数的方法,以减少计算资源的需求。LoRA(Low-Rank Adaptation)是一种 PEFT 方法,通过添加低秩矩阵来减少模型参数的数量,从而降低训练成本。
结合使用
将量化和 PEFT 结合使用可以进一步优化模型训练。例如,QLoRA 方法将模型量化到 4 位并使用 LoRA 进行微调,使得即使在单个 GPU 上也能微调超过 65 亿参数的模型。
side network
Side Network(侧网络)是一种在深度学习模型中增加额外子网络的技术,通常用于增强模型的性能或增加特定功能。这种附加子网络与主网络并行工作,帮助模型捕捉更多的信息或优化特定的任务。
主要特点和用途
增强特定功能:侧网络可以用来增强模型在特定任务上的性能。例如,可以在图像分类模型中添加一个侧网络来进行目标检测。
多任务学习:通过添加侧网络,模型可以同时处理多个任务。主网络处理主要任务,而侧网络处理次要或辅助任务。
特征提取:侧网络可以帮助提取更丰富的特征信息,增强模型的表现。例如,在自然语言处理模型中,侧网络可以专门提取情感特征。
侧网络的特点
轻量级结构:侧网络通常比原始的 LLM 更小,具有更少的参数和更简单的结构。它的设计目标是利用 LLM 的隐藏状态来进行任务特定的预测,而不是完全替代 LLM。
独立训练:侧网络在训练过程中是独立于 LLM 的。这意味着在微调阶段,侧网络的参数会被更新,而 LLM 的参数(特别是量化后的 4 位权重)保持不变。这种设计可以减少训练的复杂性和内存需求.
侧网络的训练过程
输入设计:侧网络的输入是经过下采样的 LLM 隐藏状态。在每一层,侧网络的输入由两部分组成:一部分是 LLM 的下采样隐藏状态,另一部分是侧网络的前一层输出。这种设计允许侧网络在每一层逐步构建任务相关的特征表示.
目标优化:侧网络的训练目标是优化特定任务的性能指标,如分类任务的准确率或生成任务的流畅度和一致性。通过这种方式,侧网络可以专注于学习与任务最相关的特征和模式.
反向传播:在反向传播过程中,侧网络的梯度是独立计算的,不需要通过 LLM 进行反向传播。这大大减少了内存占用,因为不需要存储 LLM 的中间激活状态.
introduce
提出了一种名为量化侧调优(Quantized SideTuning,QST)的快速且内存高效的大型语言模型(LLM)微调框架。QST采用了一个双阶段过程:
量化: 将LLM权重减少到4位,以减少内存占用。
侧网络: 利用一个独立的网络来避免对量化的LLM进行反向传播,从而节省中间激活的内存。
主要特点包括:
在每一层组合下采样的LLM输出和侧网络输出。
使用低秩适配器方法(如MaxPooling和AvgPooling)来减少可训练参数和内存占用。
使用可学习参数聚合隐藏状态并重用LLM头进行预测。
侧网络和LLM并行运行,避免增加推理延迟。
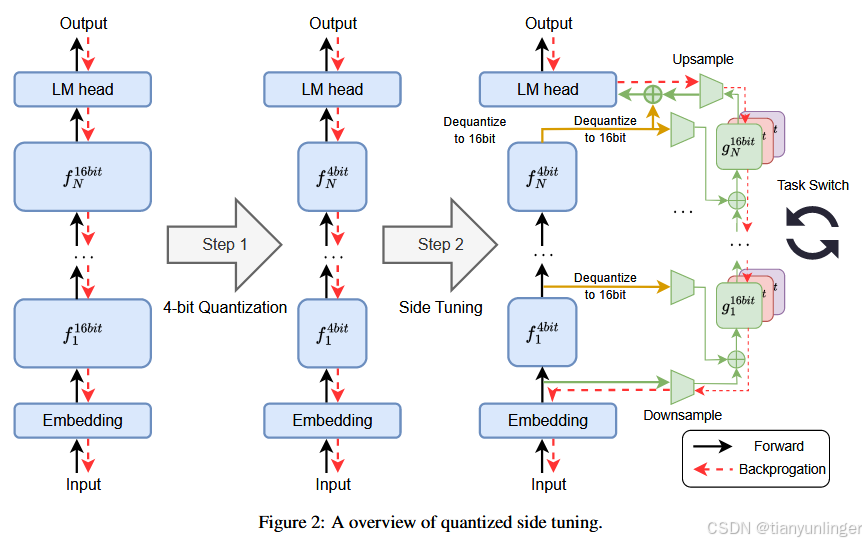
图2:量化侧调优概述
步骤1:4位量化
- 图片左侧展示了一个标准神经网络流程图,包含嵌入层、一系列标为 f 1 16 b i t f^{16bit}_1 f116bit 到 f N 16 b i t f^{16bit}_N fN16bit 的层,以及一个语言模型(LM)头,从输入到输出的处理。
- 中间部分显示这个网络被量化到4位精度,将层转换为 f 1 4 b i t f^{4bit}_1 f14bit 到 f N 4 b i t f^{4bit}_N fN4bit。
步骤2:侧调优
- 图片右侧展示了侧调优过程。量化的层 f 1 4 b i t f^{4bit}_1 f14bit 到 f N 4 b i t f^{4bit}_N fN4bit被反量化回16位精度。
- 额外引入了侧调优层 g 1 16 b i t g^{16bit}_1 g116bit 到 g N 16 b i t g^{16bit}_N gN16bit,这些层通过上采样和下采样操作与主层连接。
- 图片中还显示了一个任务切换机制,允许在训练过程中切换任务。
图中使用箭头表示数据的流动(前向传播和反向传播),并强调了转换和调优步骤。这个过程旨在通过减少计算精度然后微调网络来提高神经网络的效率和性能。
公式

quantization bins
异常值的影响
- 量化桶的概念:在量化过程中,原始数据的值域被划分为若干个量化桶,每个桶对应一个量化值。例如,在 4 位量化中,可能有 16 个量化桶,每个桶代表一个量化值.
- 异常值的定义:异常值是指在数据集中显著偏离其他数据点的值。例如,在一个主要集中在 0 到 1 之间的数据集中,突然出现一个值为 100 的数据点,这个值就是异常值.
- 导致的问题:当数据集中存在异常值时,这些异常值可能会占据量化桶的大部分范围。例如,如果一个量化桶被设计为包含 0 到 1 之间的值,但异常值的存在使得这个桶的范围被扩展到 0 到 100,那么原本应该集中在 0 到 1 之间的数据点就会被稀释到更大的范围内.
- 稀疏桶:由于异常值的存在,许多量化桶可能只包含很少的数据点,甚至有些桶可能完全为空。这会导致量化后的数据失去原有的分布特征和信息密度.
- 信息损失:量化过程中的信息损失会增加,因为异常值的存在使得量化桶的划分不再合理,无法有效地表示原始数据的特征和分布.
解决方法
为了解决异常值导致的量化桶利用率不足的问题,常见的方法包括:
- 数据预处理:在量化之前对数据进行预处理,例如通过去除异常值或进行数据标准化,使得数据的分布更加集中和均匀.
- 分块量化:将输入数据划分为多个小块,每个块独立进行量化。这样可以减少异常值对整个数据集的影响,使得每个块的量化桶更加合理. - 动态量化:根据数据的分布动态调整量化桶的范围和数量,以更好地适应数据的实际分布特征.
评估数据集
我们评估了 QST 的性能以及自然语言理解 (NLU) 和自然语言生成任务的几个基线。对于 NLU 实验,我们使用 GLUE(Wang 等人,2018)(通用语言理解评估)和 MMLU(Hendrycks 等人,2020)(大规模多任务语言理解)基准。
代码
class AdapterLinear(nn.Module):
# 定义一个名为 AdapterLinear 的类,继承自 PyTorch 的 nn.Module
def __init__(self,
in_features: int, # 输入特征的维度
out_features: int, # 输出特征的维度
r: int, # 适配器的中间维度
alpha_r: int, # 用于缩放适配器输出的参数
activation=None, # 适配器中间层的激活函数
add_layer_norm_before_adapter=False, # 是否在适配器前添加层归一化
add_layer_norm_after_adapter=False, # 是否在适配器后添加层归一化
dropout=0.0, # dropout 概率
bias=False, # 是否包含偏置参数
):
# 调用父类 nn.Module 的构造函数
super(AdapterLinear, self).__init__()
# 初始化第一个线性层 adapter_A,将输入特征映射到中间维度 r
self.adapter_A = nn.Linear(in_features, r, bias=bias)
# 使用 kaiming_uniform_ 初始化 adapter_A 的权重
nn.init.kaiming_uniform_(self.adapter_A.weight, a=math.sqrt(5))
# 初始化第二个线性层 adapter_B,将中间特征映射回输出维度
self.adapter_B = nn.Linear(r, out_features, bias=bias)
# 使用 kaiming_uniform_ 初始化 adapter_B 的权重
nn.init.kaiming_uniform_(self.adapter_B.weight, a=math.sqrt(5))
# 注释掉的代码表示另一种初始化方式,将 adapter_B 的权重初始化为零
# nn.init.zeros_(self.adapter_B.weight)
# 如果指定了激活函数,则创建一个 Activations 实例
if activation is not None:
self.activation = Activations(activation.lower())
else:
self.activation = None
# 根据配置,决定是否添加层归一化
self.add_layer_norm_before_adapter = add_layer_norm_before_adapter
self.add_layer_norm_after_adapter = add_layer_norm_after_adapter
# 如果需要在适配器前添加层归一化,则创建一个 LayerNorm 实例
if self.add_layer_norm_before_adapter:
self.pre_layer_norm = nn.LayerNorm(in_features)
# 如果需要在适配器后添加层归一化,则创建一个 LayerNorm 实例
if self.add_layer_norm_after_adapter:
self.post_layer_norm = nn.LayerNorm(out_features)
# 根据 dropout 概率,选择使用 Identity 或 Dropout 层, Identity层是占位层,不改变输入输出
if dropout > 0.0:
self.dropout_layer = nn.Identity()
else:
self.dropout_layer = nn.Dropout(p=dropout)
# 计算缩放因子,用于调整适配器的输出
self.scaling = r / alpha_r
def set_bias(self, enabled=False):
# 设置适配器中线性层的偏置参数是否可训练
self.adapter_A.bias.requires_grad = enabled
self.adapter_B.bias.requires_grad = enabled
def forward(self, x):
# 前向传播函数
# 首先对输入 x 应用 dropout 层
x = self.dropout_layer(x)
# 如果配置了在适配器前添加层归一化,则对 x 应用 pre_layer_norm
if self.add_layer_norm_before_adapter:
x = self.pre_layer_norm(x)
# 将 x 通过第一个线性层 adapter_A
x = self.adapter_A(x)
# 如果指定了激活函数,则对 x 应用激活函数
if self.activation is not None:
x = self.activation(x)
# 将 x 通过第二个线性层 adapter_B,得到输出 y
y = self.adapter_B(x)
# 如果配置了在适配器后添加层归一化,则对 y 应用 post_layer_norm
if self.add_layer_norm_after_adapter:
y = self.post_layer_norm(y)
# 返回适配器的输出 y
return y
qst.py
这段代码是一个用于训练和评估自然语言处理模型的完整脚本,主要使用了Hugging Face的Transformers库和datasets库。它定义了多个参数类来配置模型、数据和训练参数,并提供了模型加载、数据预处理、训练、评估和预测的完整流程。代码支持多种数据集和模型架构,包括QST(可能是某种特定技术或组件)相关的模型,并能够处理不同的训练和评估任务。通过自定义的回调函数和数据收集器,可以实现特定的评估和数据处理逻辑,如MMLU评估和数据集格式化。
modeling_qst_output.py:数据类定义
定义了多个数据类,如 QSTBaseModelOutput、QSTBaseModelOutputWithPast、SideBaseModelOutputWithPastAndCrossAttentions 等,用于表示模型输出的不同结构和内容.
这些数据类继承自 Hugging Face 的 Transformers 库中的基础输出类,并扩展了额外的属性,如 qst_hidden_states、qst_attentions、side_hidden_states 等,以支持特定的模型组件(如 QST 和侧边信息).
适用于需要处理额外模型状态和注意力信息的复杂自然语言处理模型,如序列到序列模型、因果语言模型和序列分类模型,提供了灵活的方式来组织和传递模型输出数据.
modeling_opt_qst.py:PyTorch OPT 模型
定义了基于 OPT(Open Pre-trained Transformer)模型的多个类和函数,用于构建和训练自然语言处理模型.
包括模型的嵌入层(如 OPTLearnedPositionalEmbedding)、注意力机制(如 OPTAttention)、解码器层(如 OPTDecoderLayer)以及完整的模型定义(如 OPTModel、OPTForCausalLM、OPTForSequenceClassification 等).
支持多种自然语言处理任务,如语言建模、序列分类和问答,并提供了模型的初始化、权重加载、前向传播等核心功能.
通过继承和扩展 Hugging Face 的 Transformers 库中的基础类,实现了 OPT 模型的构建和训练,具备良好的灵活性和可扩展性.
modeling_llama_qst.py:PyTorch LLaMA 模型
定义了基于 LLaMA(Large Language Model with Attention)模型的多个类和函数,用于构建和训练自然语言处理模型.
包括模型的嵌入层(如 LlamaRMSNorm、LlamaRotaryEmbedding)、注意力机制(如 LlamaAttention)、解码器层(如 LlamaDecoderLayer)以及完整的模型定义(如 LlamaModel、LlamaForCausalLM、LlamaForSequenceClassification 等).
支持多种自然语言处理任务,如语言建模、序列分类和问答,并提供了模型的初始化、权重加载、前向传播等核心功能.
通过继承和扩展 Hugging Face 的 Transformers 库中的基础类,实现了 LLaMA 模型的构建和训练,具备良好的灵活性和可扩展性.
glue_qst.py:训练和评估脚本
是一个用于训练和评估基于 LLaMA 模型的序列分类任务的脚本,主要使用了 Hugging Face 的 Transformers 库和 datasets 库.
包含了数据处理、模型初始化、训练参数配置、模型训练和评估等完整流程.
支持多种 GLUE 任务,如 CoLA、MNLI、MRPC、QNLI、QQP、RTE、SST2 和 STSB.
提供了灵活的参数配置方式,可以通过命令行参数和配置字典来调整模型、数据和训练的各种参数.
记录和保存了训练结果、日志和训练时间等信息,方便后续分析和使用.
QSTGenerationMixin.py:自定义生成混合类
定义了一个名为 QSTGenerationMixin 的自定义生成混合类,继承自 GenerationMixin.
用于在生成过程中处理特定于 QST(可能是某种特定技术或组件)的参数和状态,如 qst_past_key_values、qst_hidden_states 和 qst_attentions.
通过重写 generate 和 _update_model_kwargs_for_generation 方法,扩展了生成逻辑,使其能够支持 QST 相关的生成需求.
提供了灵活的生成逻辑扩展方式,方便根据具体需求进行定制和优化,适用于需要处理额外生成状态和参数的复杂生成任务.



















 180
180

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









