






一、C++中的异常
1.1C语言中关于错误的处理(回顾)
1.1.1处理一:文件中的错误码,错误信息
C语言中,文件打开成功则返回地址,不成功返回0
FILE* fout=fopen("Test.txt","r");
cout<<fout<<endl;//打印文件内容
cout<<errno<<endl;//打印错误码编号
perror("fopen fail:");//先打印参数中的字符串,再打印错误信息
1.1.2处理二:中止程序
当遇到内存错误,assert断言时会直接终止程序
1.2C++中异常的概念
异常是一种处理错误的方式,一个函数发现错误时可以抛出异常,再由函数本身或者调用该函数的函数进行异常处理
1.3结合例子说明抛出--匹配的规则

函数的调用栈为

此时如果输入“4 0”
首先会在add中抛异常,异常对象的类型为“const char*”
进入Func()中,会发现并没有catch类型匹配,会直接跳过Func()剩下代码到main()中,
再找到匹配的catch后进行运行,打印结果

1.4函数调用链中,异常栈展开匹配规则
①首先检查throw在不在try块内部
1>在,查catch有无类型匹配
2>不在或无类型匹配,退出当前函数,沿着函数栈去调用它的函数中查找有无try,再走一遍①的逻辑,如果到达main()结束时仍无匹配,则终止程序
如
int add(int a, int b)
{
if (b == 0)
throw 5;
else
return a + b;
}
void Func()
{
int len1, len2;
cin >> len1 >> len2;
cout << add(len1, len2) << endl;//此处add函数的调用不在try块内部
try
{
}
catch (size_t x)
{
cout << x << endl;
}
cout << "finished Func()" << endl;
}
int main()
{
try {
Func();
}
catch (const char* str)
{
cout << str << endl;
}
catch (...)
{
cout << "unknown exception" << endl;
}
return 0;
}此处add函数的调用不在try块内部,不会走到size_t类型的catch上,而是会直接退回到main中,走到...
此时打印结果

②找到匹配的catch语句处理后,会继续沿当前catch子句后面执行
③除了允许抛出派生类对象,用基类捕获之外,catch的类型严格匹配
④允许catch中异常重新抛出,捕获到什么抛出什么
1.4补:实践中的做法
实践中大多会用派生类进行抛出,用基类捕获,
会在派生类中实现一个基类虚函数的多态用来打印错误信息,基类中有一个成员变量_id来对异常进行唯一标识
如:服务器开发中的异常继承体系
1.5异常中的安全问题
①构造函数要完成对象的构造和初始化,最好不要在其中抛异常,否则可能会导致对象不完整
②析构函数要完成资源的清理,最好不要在其中抛异常,否则可能会导致资源泄露
③因为异常的捕捉机制,可能会存在申请资源的代码执行了,但是释放资源的代码没有执行,如
1.3中的函数
void Func()
{
int len1, len2;
cin >> len1 >> len2;
try
{
cout << add(len1, len2) << endl;
}
catch (size_t x)
{
cout << x << endl;
}
cout << "finished Func()" << endl;
}如果它代码中的add调用之前申请资源,打印 "finished Func()"之后释放资源,我们的实际调用过程还和例子中的一致
void Func()
{
int len1, len2;
cin >> len1 >> len2;
try
{
int* arr=new int(10);
cout << add(len1, len2) << endl;
}
catch (size_t x)
{
cout << x << endl;
}
cout << "finished Func()" << endl;
delete arr;
arr=nullptr;
}这样一来,属于arr的那一部分资源就会出现资源泄露的问题
理想的处理方式是把arr交给RAII智能指针去处理,自动进行资源释放
1.6异常的规范相关问题
①在C++11之前,通过在函数后加throw()来明确是否可能抛异常,如
void* void Func(size_t s,void* ptr) throw();()中为空是不会抛异常;()中有内容是可能抛哪些类型的异常
②throw()的标识体系使用起来并不方便于是在C++11中新增了关键字noexcept,用来表示函数不会抛异常;而不写该关键字默认会抛异常
③加了noexcept后还去抛异常会直接报错,就算能捕获也不会捕获
④库中提供了一个exception作为异常继承的基类,其中还有虚函数what供重写来满足需求
1.7异常的优缺点总结
优点:
①相比于错误码,可以更清晰地展示出错误的信息,甚至可以包含堆栈调用地信息,帮助程序员更好的定位bug
②传统错误码返回方式中,当深层调用函数返回错误的时候只能返回到最外层函数,而异常可以在函数调用栈进行捕获
③有些函数难以通过返回值表示错误,如
T& operator[](int i)出错时似乎返回什么都不太合理 ,使用异常的话更好处理
缺点:
①异常的跳转捕获机制会使调试的成本增大
②C++中无“垃圾自动回收机制”(java和phthon等为了避免资源泄露,都加上了资源自动销毁的“垃圾自动回收机制”),资源可能会出现内存泄露的问题,但可以通过RAII智能指针来规避
③异常的使用必须要规范,该加noexcept要加,这对程序员来说要求会高一些
二、C++中的智能指针
2.1什么是智能指针
智能指针又称RAII,是Resource Acquisition Is Initialization的缩写
即“资源获得立即初始化”
是利用对象生命周期控制程序资源,在主动构造时获取资源,自动调用析构时释放资源
2.2简单的智能指针示例
template<class T>
class Smart_ptr
{
public:
Smart_ptr(T* ptr)
:_ptr(ptr)
{}
~Smart_ptr()
{
delete _ptr;
}
private:
T* _ptr;
};
//设置一个简单的自定义类型
struct A
{
int _a;
};
void func()
{
A* a1=new A;
A* a2=new A;
SmartPtr<A> pt1(a1);
SmartPtr<A> pt2(a2);
}在这段示例中,自定义类型A是由new进行申请,但函数结束也没有主动去释放,而是由SmartPtr自动进行析构的调用
2.3智能指针的拷贝中出现的问题
2.3.1在2.2的例子中会出现的问题
假如此时添加这样一段代码
SmartPtr<A> pt3(pt2);会发生什么呢?
在SmatrPtr中,拷贝构造是默认生成的,会进行浅拷贝,这样以后,
pt3与pt2会指向同一块申请出来的空间,因此会有析构两次的风险
2.3.2库中的智能指针auto_ptr拷贝的原理
最早出现的智能指针就是auto_ptr,在C++98就已经支持了
template <class X> class auto_ptr;
它显式实现了拷贝构造,但是如果我们这样去用
auto_ptr<A> pt4(new A);
auto_ptr<A> pt5(pt4);会直接让pt4变空, auto_ptr<A> pt5(pt4);这行代码的本质是管理权转移
但实际使用过程中很少用到
2.3.3boost库及其中的智能指针
boost是在2003-2011年之间产生的,常被称为“准C++标准库”,可以包<boost>头文件来使用
其中有三个常用的智能指针:
scoped_ptr:禁止拷贝
shared_ptr:通过引用计数的方式进行拷贝
weak_ptr:不同于上两个,它不支持直接管理资源(故不符合RAII),它的存在是为了解决shared_ptr的一个缺陷:循环引用导致资源泄露
2.3.4自boost库衍生:C++11中的常用智能指针
C++11中将boost库中几个智能指针移过来了,包括
unique_ptr:把scoped_ptr换了个名字
shared_ptr:直接移植
weak_ptr:直接移植
2.4定制删除器
2.4.1定制删除器的意义
默认的析构中调用的都是delete
但如果遇到如自定义类型,如
unique_ptr<A> up1(new A[5]);//需要delete[] _ptr这类的需要其他删除资源方式的自定义类型,库中的析构明显就不够了
2.4.2unique_ptr中的定制删除器
需要在模板中传入定制删除器,如
template<class T>
struct ArrayDelete
{
void operator(T* ptr)
{
delete[] ptr;
}
};unique_ptr创建过程改为
unique_ptr<A,ArrayDelete<A>> up1(new A[5]);补:实际上因为数组类型常用,库中也提供过类模板
unique_ptr:
template <class T, class D> class unique_ptr<T[],D>;
使用时:
unique_ptr<A[]> up1(new A[5]);2.4.3shared_ptr中的定制删除器
不同于unique_ptr中在类模板中传入,shared_ptr是直接在函数参数列表里传可调用对象
这也意味着匿名类,lambda表达式,function等都可以直接使用
声明:
template <class U, class D, class Alloc> shared_ptr (U* p, D del, Alloc alloc); template <class D, class Alloc> shared_ptr (nullptr_t p, D del, Alloc alloc);
使用举例:
struct Deletefile
{
void operator()(FILE* file)
{
fclose(file);
}
};shared_ptr<FILE> sp2(fopen("text.txt","r"),Deletefile());2.5快捷构建shared_ptr的make_shared函数模板
有时需要直接使用shared_ptr类型对象,如在使用weak_ptr的过程中
此时就需要用上支持可变模板参数列表的make_shared函数模板
template <class T, class... Args> shared_ptr<T> make_shared (Args&&... args);
如:
shared_ptr<Date> sp3 = make_shared<Date>(2025,3,26);三、智能指针的模拟实现
3.1auto_ptr
基础的功能与2.2中的SmartPtr基本一致
其拷贝构造类似于
auto_ptr(auto_ptr<T>& ap)
:_ptr(ap._ptr)
{ap._ptr=nullptr;}3.2unique_ptr
即直接将拷贝构造和赋值重载置为delete
3.3shared_ptr
3.3.1基础功能的实现
拷贝时的计数逻辑是核心,其解决思路是通过成员变量额外设置值来辅助判断是否需要析构
这个值需要脱离对象本身,因为影响这个值的核心是“指向一块内存的对象数目”
①首先考虑使用静态成员变量int _pcount,但这会出现一个问题:虽然可以统计指向一块内存的资源个数,可如果有两块内存就无法进行合理划分了
②为了解决①中的问题,可以考虑给int*类型的_pcount,如果多块内存,就让指针指向不一样的空间
拷贝构造时:每次复制以后++对应_pcount
赋值重载:可能会出现接受赋值对象原来就指向一块空间的情况,因此需要走
析构逻辑+拷贝构造
3.3.2定制删除器的实现
可以用包装器来包装可调用对象,需要有缺省值,因为析构函数中我们不能再只用delete了,而要去调用_del
function<void(T* ptr)> _del = [](T* ptr) {delete ptr; };为了正常使用包装器,我们还需要补充一个模板构造函数
template<class D>
shared_ptr(T* ptr,D del)
:_ptr(ptr)
, _pcount(new int(1))
,_del(del)
{}3.3.3示例代码:
template<class T>
class shared_ptr
{
public:
shared_ptr(T* ptr)
:_ptr(ptr)
, _pcount(new int(1))
{}
template<class D>
shared_ptr(T* ptr,D del)
:_ptr(ptr)
, _pcount(new int(1))
,_del(del)
{}
shared_ptr(const shared_ptr& sp)
:_ptr(sp._ptr)
, _pcount(sp._pcount)
{
++(*_pcount);
}
void delete_sp()
{
if (--(*_pcount) == 0)
{
_del(_ptr);
delete _pcount;
_ptr = nullptr;
_pcount = nullptr;
}
}
shared_ptr& operator=(const shared_ptr& sp)
{
if (_ptr != sp._ptr)
{
delete_sp();
_ptr = sp._ptr;
_pcount = sp._pcount;
++(*_pcount);
}
return *this;
}
int use_count()
{
return *_pcount;
}
T& operator*()
{
return *_ptr;
}
T* operator->()
{
return _ptr;
}
~shared_ptr()
{
delete_sp();
}
private:
T* _ptr;
int* _pcount;
//定制删除器,服务于T的特定析构方式
function<void(T* ptr)> _del = [](T* ptr) {delete ptr; };
};3.3.4循环引用:会导致内存泄漏
场景:
struct ListNode
{
int _data;
shared_ptr<ListNode> _next;//直接将资源交给shared_ptr管理
shared_ptr<ListNode> _prev;
};
int main()
{
shared_ptr<ListNode> n1(new ListNode);
shared_ptr<ListNode> n2(new ListNode);
n1->_next=n2;
n2->_prev=n1;
return 0;
}此时n1与n2的关系是:
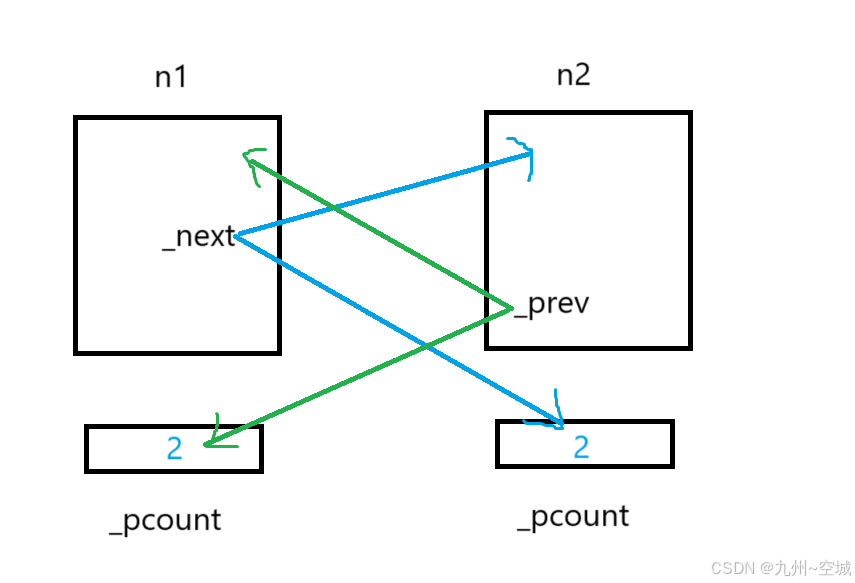
一旦析构:
首先,n1与n2析构后,计数减到1
然后问题就来了:
①右边节点什么时候释放?
_next析构,则右边节点释放
②_next什么时候析构?
_next为左边节点成员,左边节点析构,_next析构
③左边节点什么时候释放?
_prev析构,则左边节点释放
④_prev什么时候析构?
_prev为右边节点成员,右边节点析构,_prev析构
这里①-④形成了一个逻辑闭环,最后造成谁也没析构/释放,出现资源泄露
3.3.5循环引用的解决:weak_ptr
它的存在就是为了解决循环引用的问题,特点是使用shared_ptr传参时,构造/赋值时引用计数不增加
注意:weak_ptr不支持直接管理资源,即不支持RAII
它的声明中有传参
template <class U> weak_ptr (const shared_ptr<U>& x) noexcept;
可以利用make_shared传入
此外,weak_ptr是有计数的,只是计数不增加;他也有use_count()接口
四、内存泄漏
4.1什么是内存泄漏
指因疏忽或错误造成程序未能释放已不再使用的内存的情况
4.2内存泄露的危害
对于长期运行的程序,会导致响应越来越慢,最终卡死

















 3万+
3万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









