




 本文详细阐述了MapReduce的运行流程,包括文件分割、MapTask处理、数据溢出及ReduceTask工作原理。同时,介绍了YARN的工作流程,以及Spark应用如何从Action算子触发,经过DAGScheduler和TaskScheduler调度执行。还对比了YARN-Cluster和YARN-Client模式下Spark作业的执行过程。
本文详细阐述了MapReduce的运行流程,包括文件分割、MapTask处理、数据溢出及ReduceTask工作原理。同时,介绍了YARN的工作流程,以及Spark应用如何从Action算子触发,经过DAGScheduler和TaskScheduler调度执行。还对比了YARN-Cluster和YARN-Client模式下Spark作业的执行过程。
一 请阐述mapreduce的运行机制
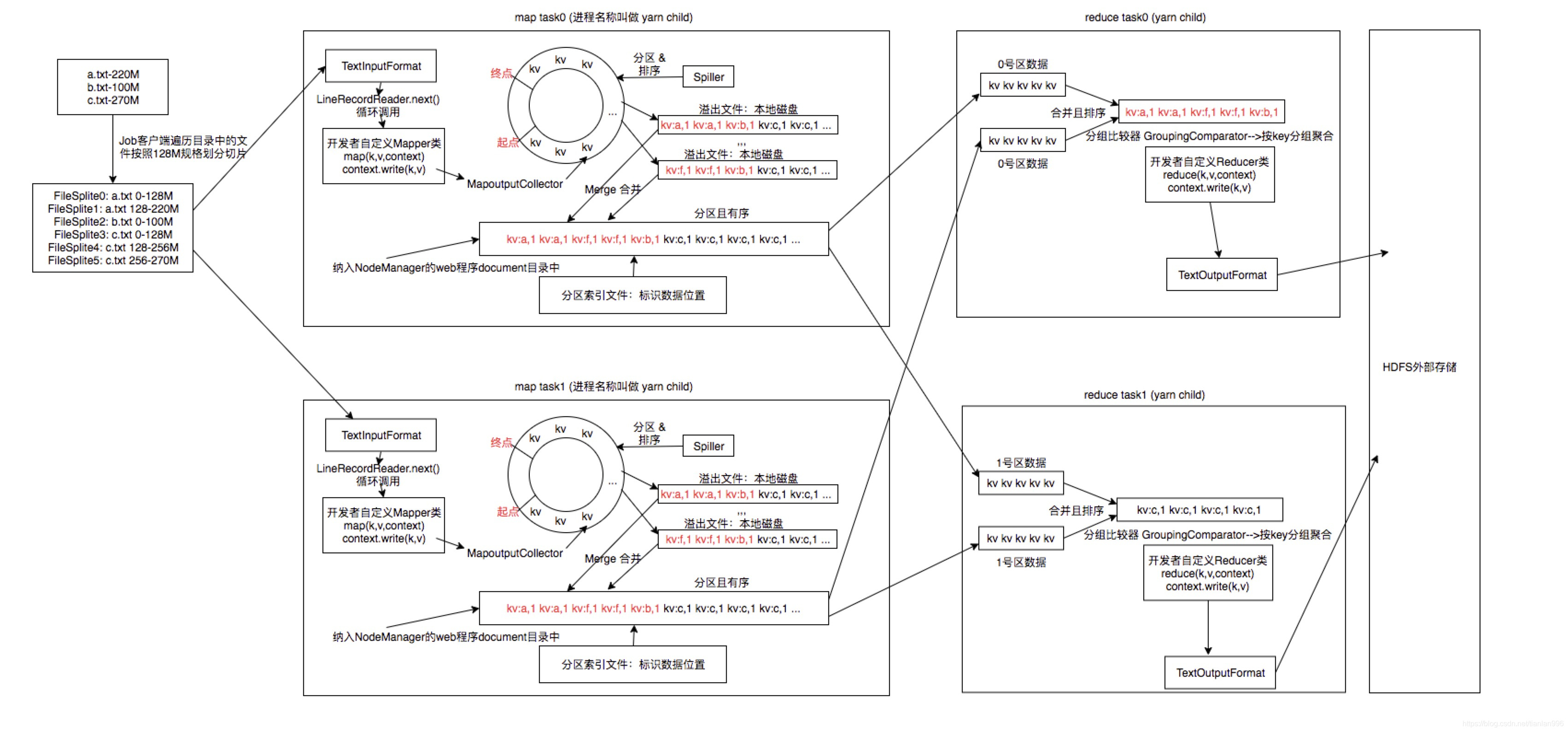
1. 文件被按128M大小进行分割。
分割是对每个文件单独进行对,不会把所有对文件看成一个整体。
2. 分割后的每个文件块就启动一个map task去处理其数据。
3. 在map task中,数据被处理成kv对的形式,首先放入一个环形缓冲区中。
MapoutputCollector负责收集数据到环形缓冲区中。
4. 当环形缓冲区的容量使用率达到80%时,一个spiller线程就开始对这些数据进行分区并排序。同时,数据会被继续写往缓冲区中,下一次写对起点是上一次写的终点。
5. 环形缓冲区中分区排序后的数据会溢出到本地磁盘中,以文件的形式进行存储。
每当环形缓冲区的容量使用率达到80%,就会形成一个本地文件,如此循环往复,直到处理完毕。
溢出文件中的数据是分区且有序的。图中红色字体是一个分区,黑色字体是一个分区,画出了两个分区。
每个key的数据只会写到一个分区中(但是一个分区可能包含多个key的数据),这样在后续reduce处理一个分区的时候,就可以将这个key对应的所有数据在一个reduce task中处理完成。
6. 同一个map中的溢出文件,最终会合并成一个分区且有序的文件。
map task结束的时候,其对应的文件只有一个,该文件会被纳入NodeManager的web程序document目录中。
7. 集群根据数据分区数启动对应数量的reduce task,每个reduce task就处理一个分区的数据。
reduce task通过http协议从各个节点上下载自己要处理的分区的数据,并形成临时文件;拉取数据完成后,reduce task会将这 些临时文件合并成一个文件,然后按key分组处理。
8. reduce task对数据聚合处理后,将最终结果写入外部存储,例如hdfs。
二 yarn流程
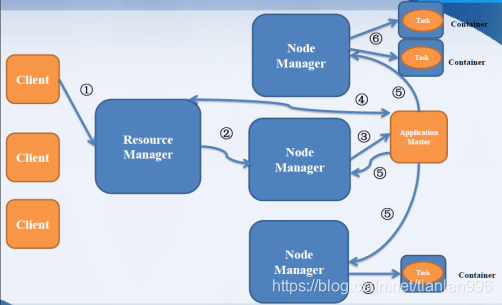
1) 用户向YARN 中提交应用程序, 其中包括ApplicationMaster 程序、启动ApplicationMaster 的命令、用户程序等。
2) ResourceManager 为该应用程序分配第一个Container, 并与对应的NodeManager 通信,要求它在这个Container 中启动应用程序的ApplicationMaster。
3) ApplicationMaster 首先向ResourceManager 注册, 这样用户可以直接通过ResourceManage 查看应用程序的运行状态,然后它将为各个任务申请资源,并监控它的运行状态,直到运行结束,即重复步骤4~7。
4) ApplicationMaster 采用轮询的方式通过RPC 协议向ResourceManager 申请和领取资源。
5) 一旦ApplicationMaster 申请到资源后,便与对应的NodeManager 通信,要求它启动任务。
6) NodeManager 为任务设置好运行环境(包括环境变量、JAR 包、二进制程序等)后,将任务启动命令写到一个脚本中,并通过运行该脚本启动任务。
7) 各个任务通过某个RPC 协议向ApplicationMaster 汇报自己的状态和进度,以让ApplicationMaster 随时掌握各个任务的运行状态,从而可以在任务失败时重新启动任务。在应用程序运行过程中,用户可随时通过RPC 向ApplicationMaster 查询应用程序的当前运行状态。
8) 应用程序运行完成后,ApplicationMaster 向ResourceManager 注销并关闭自己。
三 Spark应用转换流程
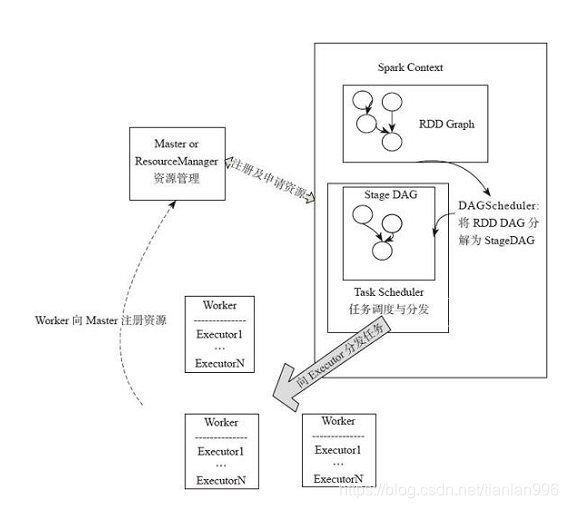
- spark应用提交后,经历了一系列的转换,最后成为task在每个节点上执行
- RDD的Action算子触发Job的提交,生成RDD DAG
- 由DAGScheduler将RDD DAG转化为Stage DAG,每个Stage中产生相应的Task集合
- TaskScheduler将任务分发到Executor执行
- 每个任务对应相应的一个数据块,只用用户定义的函数处理数据块
四 yarn-cluster模式:Driver运行在Worker上
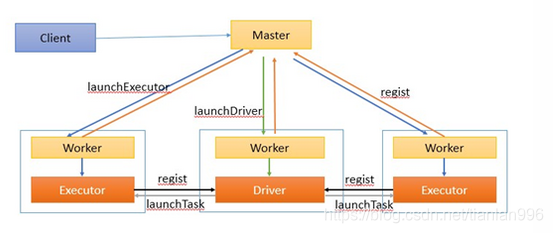
作业执行流程描述:
1、客户端提交作业给Master
2、Master让一个Worker启动Driver,即SchedulerBackend。Worker创建一个DriverRunner线程,DriverRunner启动SchedulerBackend进程。
3、另外Master还会让其余Worker启动Exeuctor,即ExecutorBackend。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend(CoarseGrainedExecutorBackend)进程。
4、ExecutorBackend启动后会向Driver的SchedulerBackend注册。SchedulerBackend进程中包含DAGScheduler,它会根据用户程序,生成执行计划,并调度执行。对于每个stage的task,都会被存放到TaskScheduler中,ExecutorBackend向SchedulerBackend汇报的时候把TaskScheduler中的task调度到ExecutorBackend执行。
5、所有stage都完成后作业结束。
五 yarn-client模式:Driver运行在客户端
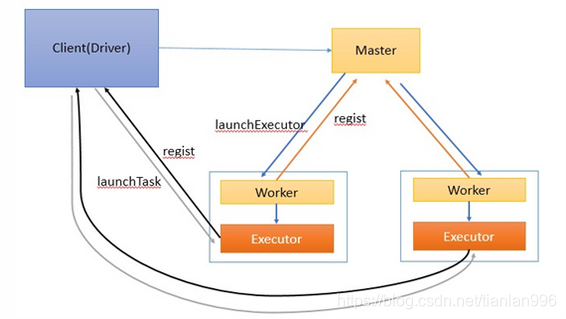
作业执行流程描述:
1、客户端启动后直接运行用户程序,启动Driver相关的工作:DAGScheduler和BlockManagerMaster等。
2、客户端的Driver向Master注册。
3、Master还会让Worker启动Exeuctor。Worker创建一个ExecutorRunner线程,ExecutorRunner会启动ExecutorBackend(CoarseGrainedExecutorBackend)进程。
4、ExecutorBackend启动后会向Driver的SchedulerBackend注册。Driver的DAGScheduler解析作业并生成相应的Stage,每个Stage包含的Task通过TaskScheduler分配给Executor执行。
5、所有stage都完成后作业结束。

















 796
796

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









