







 这篇博客探讨了大数据面试中涉及的数据结构问题,包括如何在海量数据场景下找到最常见的IP地址、Top K IP、只出现一次的整数、文件交集等。解决方案涵盖哈希切分、位图、布隆过滤器等技术,并讨论了如何扩展BloomFilter以支持删除和计数操作。
这篇博客探讨了大数据面试中涉及的数据结构问题,包括如何在海量数据场景下找到最常见的IP地址、Top K IP、只出现一次的整数、文件交集等。解决方案涵盖哈希切分、位图、布隆过滤器等技术,并讨论了如何扩展BloomFilter以支持删除和计数操作。
1)给⼀个超过100G⼤⼩的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
2)与上题条件相同,如何找到top K的IP?如何直接⽤Linux系统命令实现?
3)给定100亿个整数,设计算法找到只出现⼀次的整数
4)给两个⽂件,分别有100亿个整数,我们只有1G内存,如何找到两个⽂件交集
5)1个⽂件有100亿个int,1G内存,设计算法找到出现次数不超过2次的所有整数
6)给两个⽂件,分别有100亿个query,我们只有1G内存,如何找到两个⽂件交集?分别给出精确算法和近似算法
7)如何扩展BloomFilter使得它⽀持删除元素的操作?
8)如何扩展BloomFilter使得它⽀持计数操作?
9)给上千个⽂件,每个⽂件⼤⼩为1K—100M。给n个词,设计算法对每个词找到所有包含它的⽂件,你只有100K内存
10有⼀个词典,包含N个英⽂单词,现在任意给⼀个字符串,设计算法找出包含这个字符串的所有英⽂单词
解决问题:
1)给⼀个超过100G⼤⼩的log file, log中存着IP地址, 设计算法找到出现次数最多的IP地址?
答:主要思想是:如果给一个大文件,首先考虑 位图和布隆,如果处理不了的话,考虑用哈希切分的方法。
在这我们用哈希切分:采用哈希切割将ip相同的文件用散列函数(ip地址看成是字符串转为int类型)都映射到同一个文件中,再一次统计每个文件ip的个数,求出最多的,如果一个ip出现的次数特别多,切割之后还是无法加载到内存中,我们可以再对这个文件进行切割(普通切割)分成若干个小文件,最后将小文件的结果汇总比较,求出出现次数最多的ip地址。
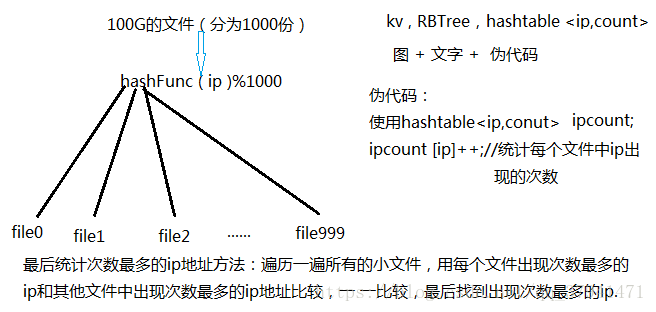
2)与上题条件相同,如何找到top K的IP?如何直接⽤Linux系统命令实现?
答:思路分析:与上题类似,我们用哈希切分来做
1)要找到topK的ip地址,我们如果直接进行排序的话,那么有两个问题,第一就是内存放不下,第二就是效率太慢
2)所以这我们可以建一个K大小的堆(优先级队列的实质就是用小堆实现的),那么建什么堆呢?这里建小堆比较好,因为来一个数和进行堆顶的元素进行比较,然后进行向下调整,大的就下去了,因此最终统计的就是topK
Linux指令的大概思路就是:先用指令把ip切分出来(哈希切分)——>再用指令去统计次数——>然后对每个文件出现最多的次数排序(降序)——>前K个就是我们要找的topk
3)给定100亿个整数,设计算法找到只出现⼀次的整数
答:100亿个整数即占用空间400亿个字节,而42亿个字节大约占用空间4G的空间,所以400亿个字节(100亿个整数)占用空间约为40G .一次加载到内存显然是不太现实的。并且所有整数所能表示的范围为2^32,即16G。故给出的数据有很多数据是重复的.
解法1:哈希切分
与第一题类似,用哈希切
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 1008
1008

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









