







一文搞懂单模态、多模态和跨模态学习——大模型基础
大家好,我是天海。
多模态和跨模态是人工智能领域中两个重要的概念,深深影响了大模型技术的发展历程,它们在定义、数据处理方式以及应用领域上存在显著区别,本文将进行详细的对比分析。
一、单模态学习
从字面意思上可以看出,单模态学习指的就是对同一类别的数据进行处理、训练和推理的过程。
例如:利用文本数据训练垃圾邮件分类器、基于文本数据的情感分类模型训练与应用等,或是利用图像数据训练图像模型的任务,这类任务可以用CNN等简单方法实现。
二、多模态学习
多模态学习是指同时使用或分析多种模态的数据(如文本、图像、音频等)共同处理、训练和推理,以提供更加丰富和全面的信息。
例如:针对一个朋友发表的朋友圈进行情感分析,可以同时利用发表的文字和上传的图片共同进行情感分析,这比传统的情感分析准确率更高。
避免只用文字分析出现错误(⊙o⊙)…
又或者针对一个视频进行分类,可以同时结合视频本身、视频的字幕、视频中的音频(声音)等关键信息。
三、跨模态学习
跨模态学习可以认为是多模态学习的一个分支,只不过两者关注的重点不同。多模态学习关注的是两种不同模态语义对齐,而跨模态关注的是将不同模态之间的数据进行相互转换和映射
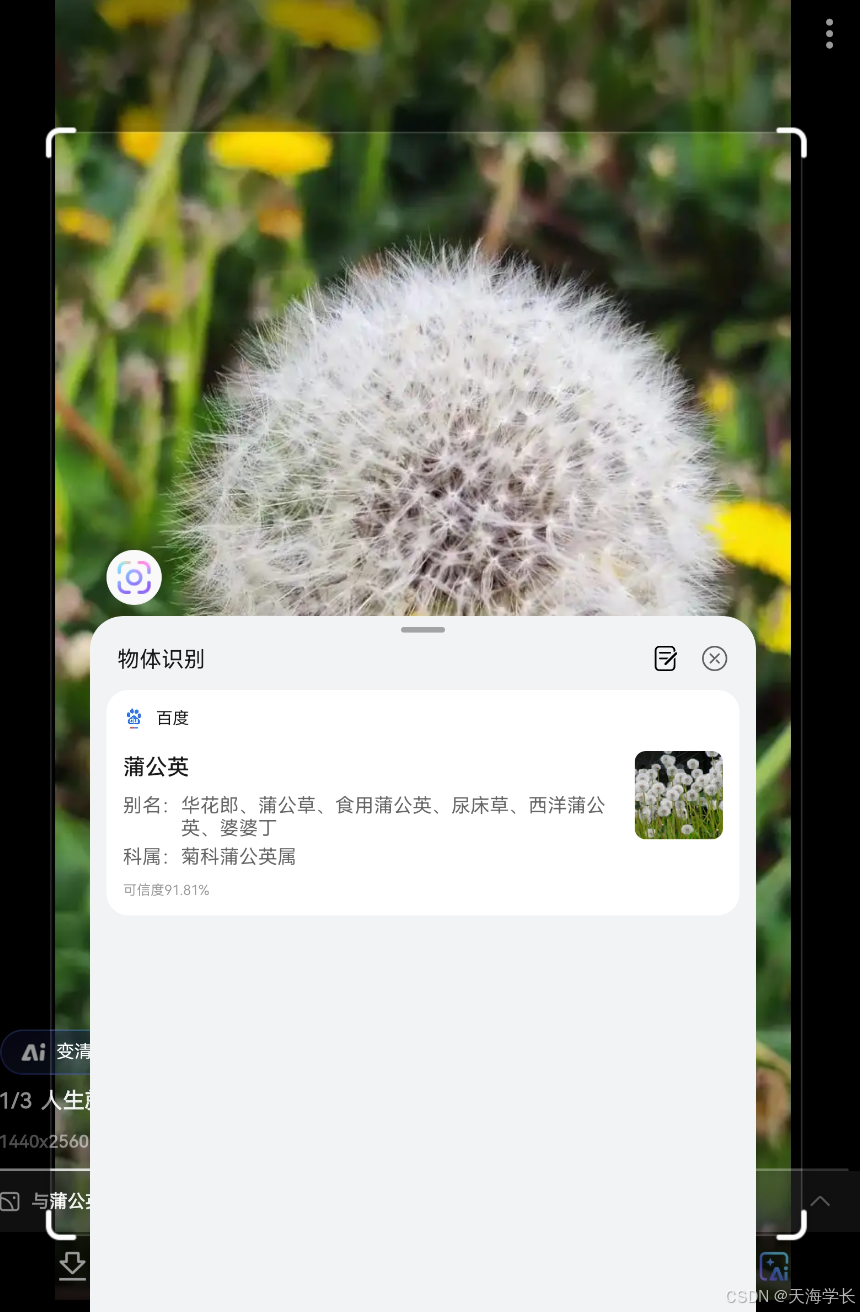
例如:在华为平板上问“小艺小艺,屏幕中的是什么花?“

这个过程,首先将语音模态的数据映射到文本模态,进行语音转文字的识别,随后又将图像模态的数据映射到文本模态上,实现图像问答。
四、总结
1、单模态学习优缺点
单模态学习简单易懂,适用于单一类别数据,减少人工标注成本,但数据特征提取能力有限。
与多模态学习相比,单模态学习的数据丰富度和多样性较低,对数据的理解及抽象能力较弱,且无法在模态数据缺失时互相补充,导致下游任务表现不佳。自然界中真实数据多为多模态形式。
2、多模态学习优缺点
多模态学习能够全方位多维度地对同一物体进行描述,且能够更好的挖掘目标特征,即使缺失某一模态数据,也能用其他模态数据进行补充,大大提高了模型的泛化能力。
但这也意味着这需要更多的数据和更大的算力支持,相应的成本也就越高。
参考书目:多模态大模型:技术原理与实战.彭勇等著—北京.电子工业出版社,2023.11


















 927
927

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











