




1.Pinecone简介
官方网站: The vector database to build knowledgeable AI | Pinecone
访问官方网站、注册、登录、获取apiKey且配置在环境变量中。默认有2GB的免费存储空间
2.Pinecone的使用
得分的含义
-
在向量检索场景中,当我们把查询文本转换为向量后,会在嵌入存储( EmbeddingStore )里查找与之最相似的向量(这些向量对应着文档片段等内容)。
-
为了衡量查询向量和存储向量之间的相似程度,会使用某种相似度计算方法(例如余弦相似度等)来得出一个数值,这个数值就是得分。得分越高,表明查询向量和存储向量越相似,对应的文档片段与查询文本的相关性也就越高。
登录官方网站,完成注册
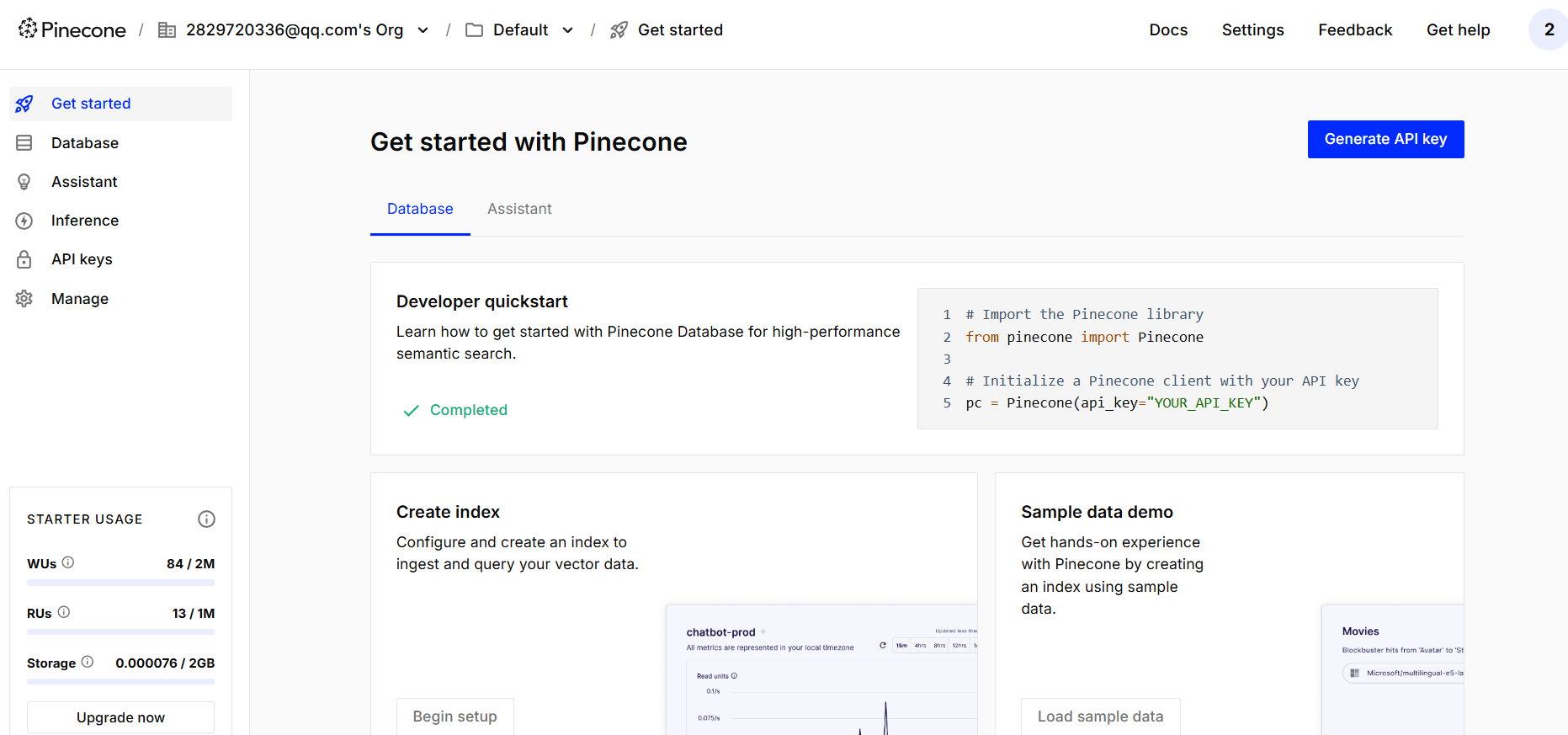
创建api-key,然后可以在环境变量中配置
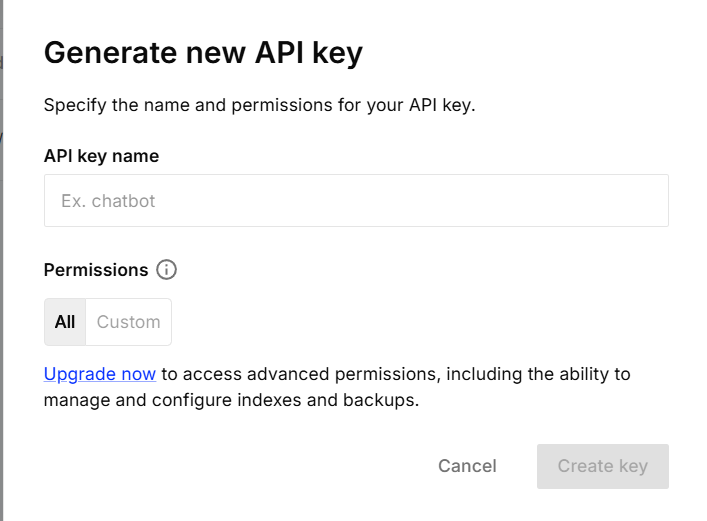
右键点击电脑属性,点击高级系统设置
点击环境变量
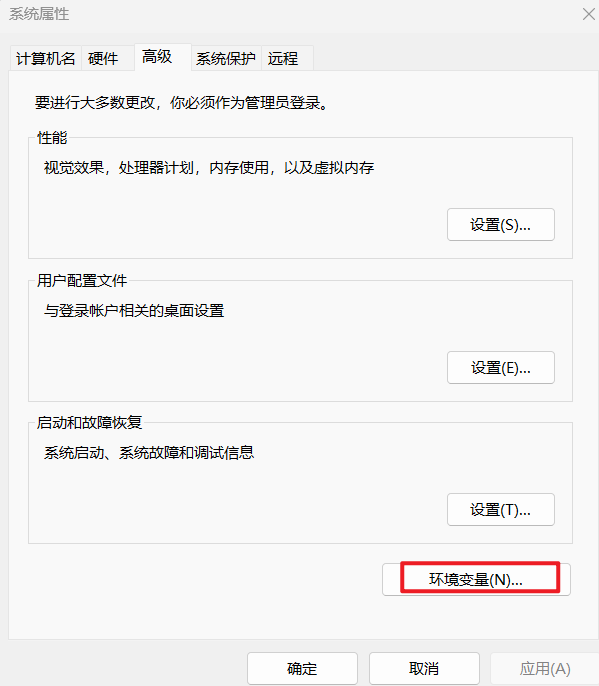
将api-key配置到环境变量中
3.集成springAI使用Pinecone
3.1创建向量索引库:
输入相关配置,后面其他的配置用默认配置即可
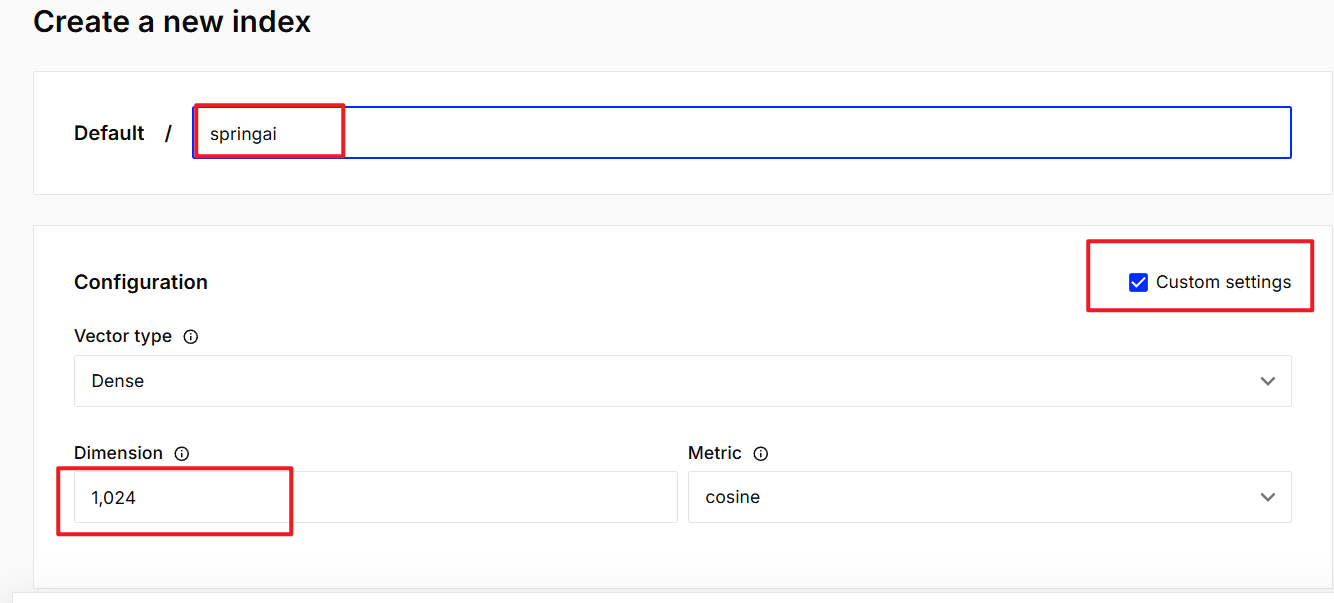
然后点击database,记住host,后面需要用到

3.2导入依赖:
<!--piecone的相关依赖-->
<dependency>
<groupId>org.springframework.ai</groupId>
<artifactId>spring-ai-starter-vector-store-pinecone</artifactId>
<version>1.0.0-M7</version>
</dependency>
3.3配置文件:
注意host里面的内容,将其拆分为index-name,project-id,environment
spring:
application:
name: ChatAiApplication
ai:
openai:
#base-url: https://api.deepseek.com
base-url: https://dashscope.aliyuncs.com/compatible-mode
api-key: ${DASHSCOPE_API_KEY}
chat:
options:
model: qwen-max-latest
temperature: 0.7
embedding:
options:
model: text-embedding-v3
dimensions: 1024 # 可以不用 设置,默认为 1024
vectorstore:
pinecone: # host: https://springai-uw1t8sh.svc.aped-4627-b74a.pinecone.io 项目地址
api-key: ${PINECONE_API_KEY}
index-name: springai
project-id: uw1t8sh
environment: aped-4627-b74a
其他配置可参考springAI官方文档
3.4测试:
// 自动注入向量库
@Autowired
private VectorStore vectorStore;
@Test
public void testVectorStore(){
Resource resource = new FileSystemResource("E:\\aa\\中二知识笔记.pdf");
// 1.创建PDF的读取器
PagePdfDocumentReader reader = new PagePdfDocumentReader(
resource, // 文件源
PdfDocumentReaderConfig.builder()
.withPageExtractedTextFormatter(ExtractedTextFormatter.defaults())
.withPagesPerDocument(1) // 每1页PDF作为一个Document
.build()
);
// 2.读取PDF文档,拆分为Document
List<Document> documents = reader.read();
// 3.写入向量库
vectorStore.add(documents);
}
@Test
public void testRedisVectorStore(){
//List<Document> docs = vectorStore.similaritySearch("论语中教育的目的是什么");
SearchRequest request = SearchRequest.builder()
.query("论语中教育的目的是什么") // 查询
.topK(5) // 返回的相似文档数量
.similarityThreshold(0.6) // 相似度阈值
//.filterExpression("file_name == '中二知识笔记.pdf'") // 过滤条件
.build();
List<Document> docs = vectorStore.similaritySearch(request);
if (docs == null) {
System.out.println("没有搜索到任何内容");
return;
}
for (Document doc : docs) {
System.out.println(doc.getId());
System.out.println(doc.getScore());
System.out.println(doc.getText());
}
}
然后再次登录官网,发现发现已经成功把文件上传到pinecone了
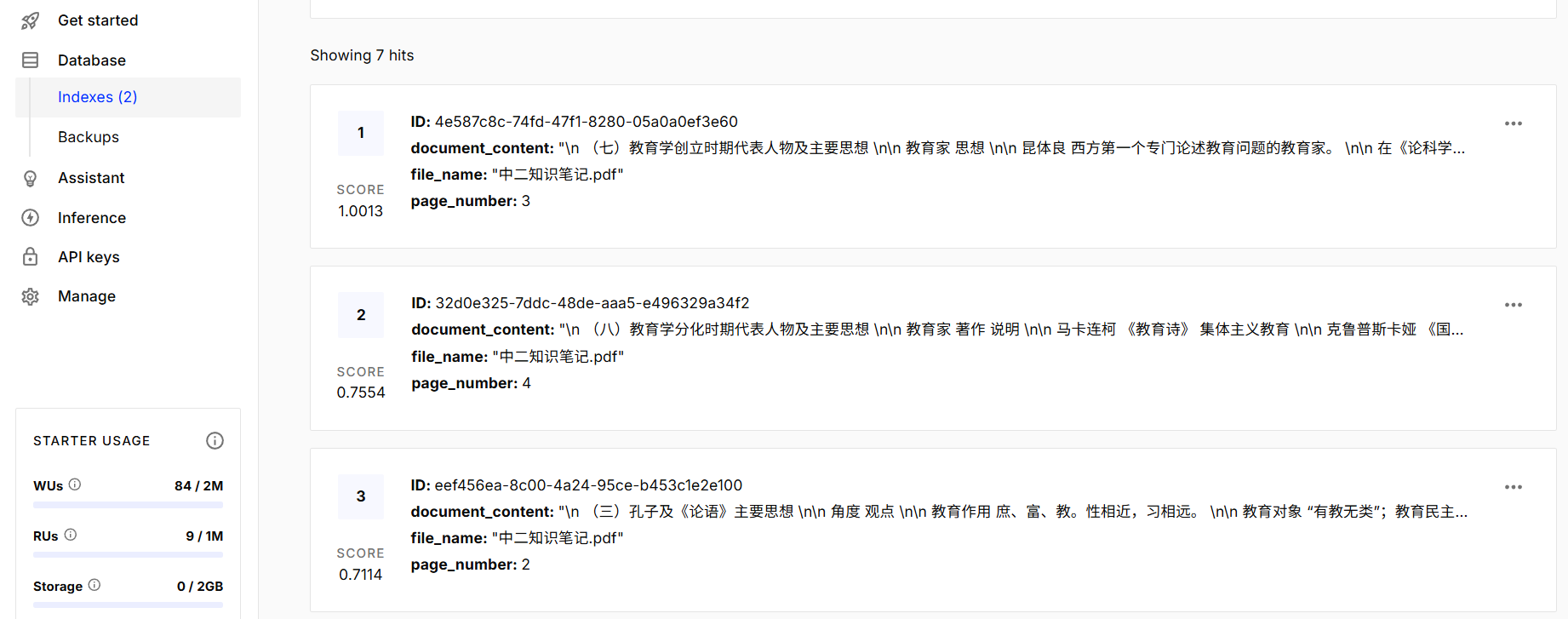
后续就可以在项目中集成使用了
4.集成配置ChatClient
这里演示一个可以读取pdf的chatClient
@Bean
public ChatClient pdfChatClient(OpenAiChatModel model, ChatMemory chatMemory, VectorStore vectorStore) {
return ChatClient.builder(model)
.defaultSystem("请根据提供的上下文回答问题,遇到上下文没有的问题,不要自己随意编造。")
.defaultAdvisors(
new MessageChatMemoryAdvisor(chatMemory), // 聊天记忆
new SimpleLoggerAdvisor(), //日志
new QuestionAnswerAdvisor(
vectorStore, // 向量库(这里注入的就是redisvectorStore)
SearchRequest.builder() // 向量检索的请求参数
.similarityThreshold(0.5d) // 相似度阈值
.topK(2) // 返回的文档片段数量
.build()
)
)
.build();
}
然后测试一下
@Autowired
private ChatClient pdfChatClient;
public String chatpdf(String prompt, String chatId) {
//3. 请求模型
return pdfChatClient.prompt()
.user(prompt)
.advisors(a -> a.param(CHAT_MEMORY_CONVERSATION_ID_KEY, chatId)) //聊天记忆
.call() //阻塞式调用
.content();
}
@Test
public void testPdfChat() {
String prompt="论语中教育的目的是什么";
String chatId = "15";
System.out.println(chatpdf(prompt, chatId));
}
结果发现和pdf中的内容一致


基于此,就实现了pinecone向量数据库来实现RAG了

















 148
148

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









