



今天给大家讲解一下SD图生图的批量处理功能应该如何让使用~(AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。)
一、图生图批量处理功能的基本用法
首先打开webUI,在图生图页面下我们先找到批量处理的菜单:
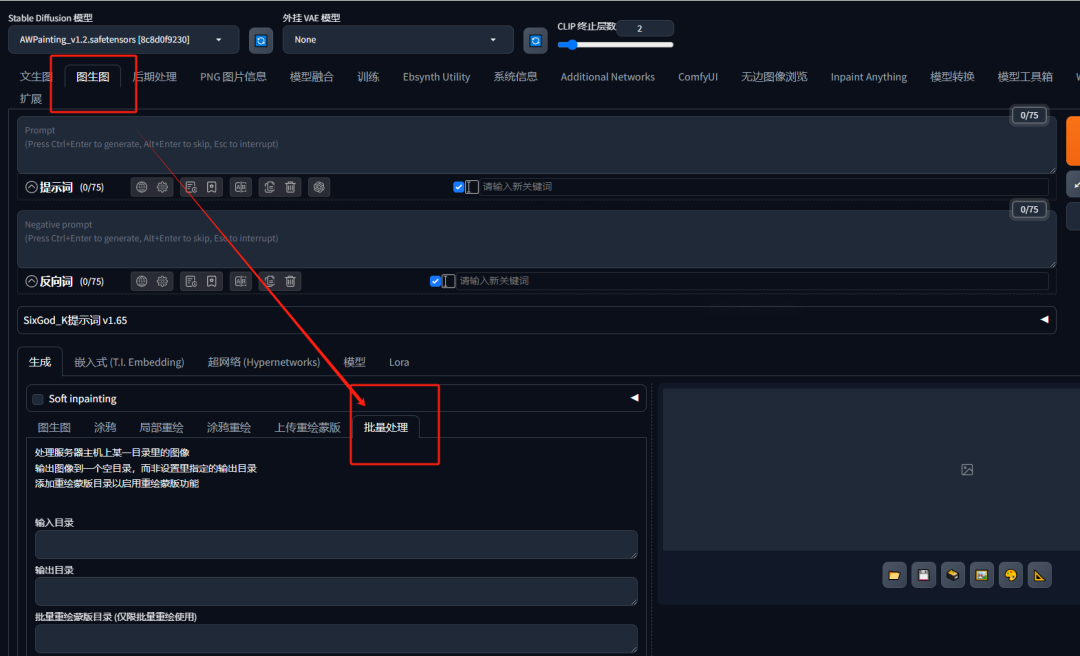
最简单的批量处理方法只需要用到【输入目录】和【输出目录】两个功能:
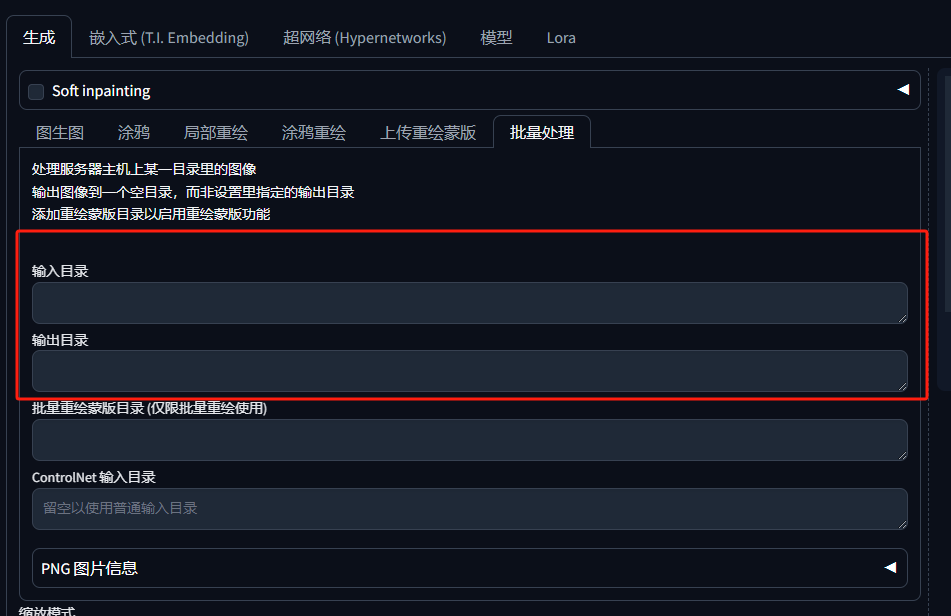
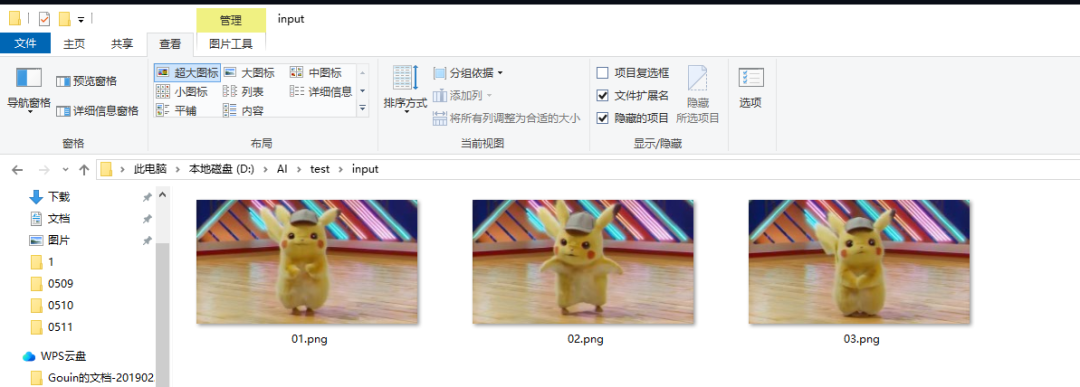
第一步,需要建立一个输入目录的文件夹,大家注意不要用中文路径。

然后将要重绘的图片编号序号放到这个文件夹内:
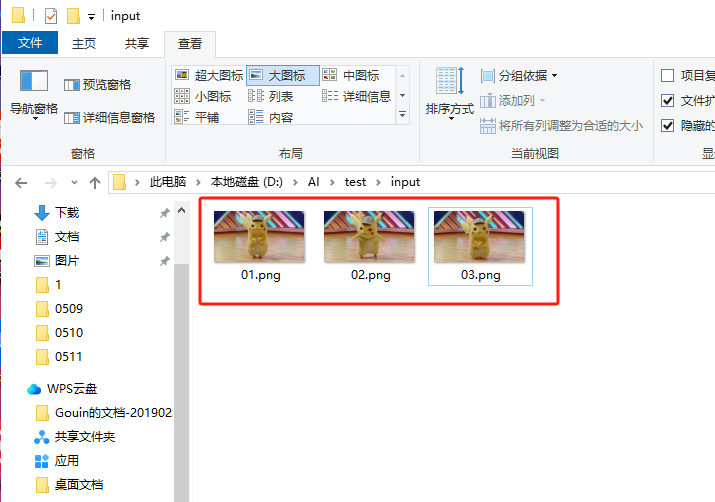
接着我们将这个目录的路径粘贴到输入目录:
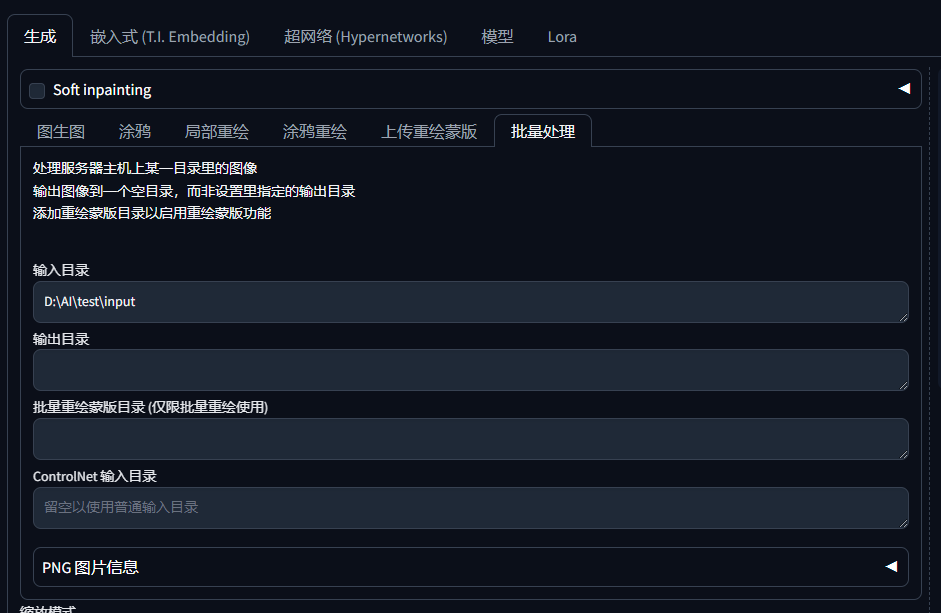
再建立一个文件夹用作输出图片用,注意路径也不要有中文:
将这个文件夹的路径粘贴到输出目录:
以上设置好之后我们就可以正常选择绘画模型,填写想要绘制的提示词和设置参数了。
例如我们想要重绘的是皮卡丘跳舞,那就在正向提示词中写入:一只皮卡丘在跳舞。
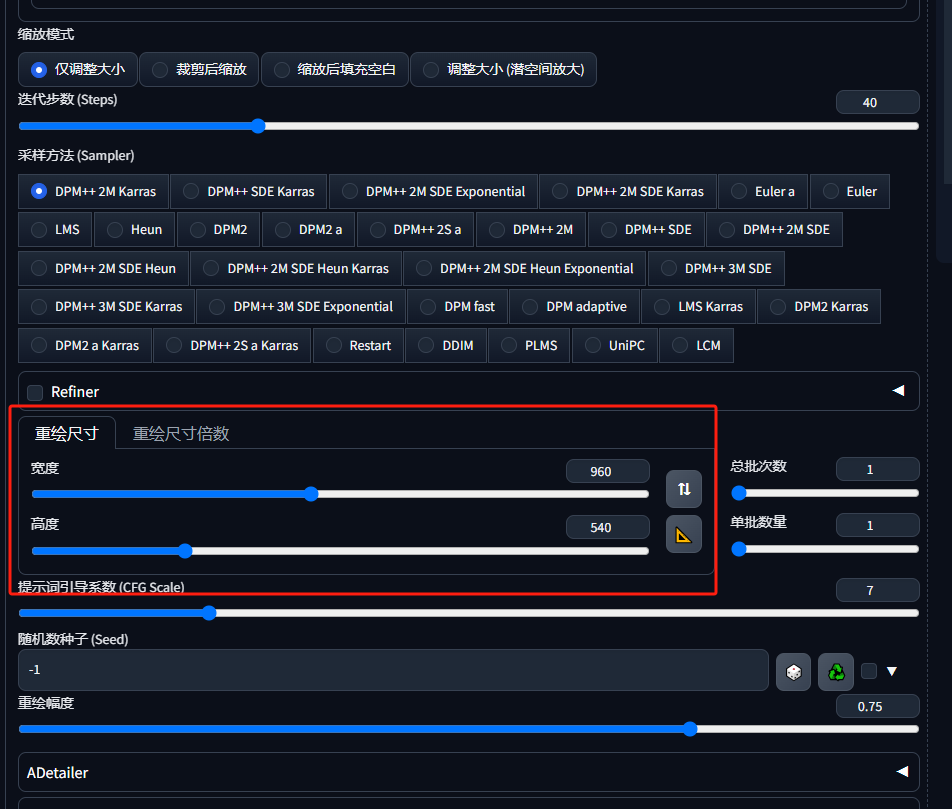
在下方设置重绘参数,注意重绘尺寸的宽高比例需要与重绘的图片一致:
最后我们点击生图,在输出的文件夹就会出现重绘后的图片了,注意如果输出文件夹没有出现重绘图,大家可以重新打开webUI尝试。
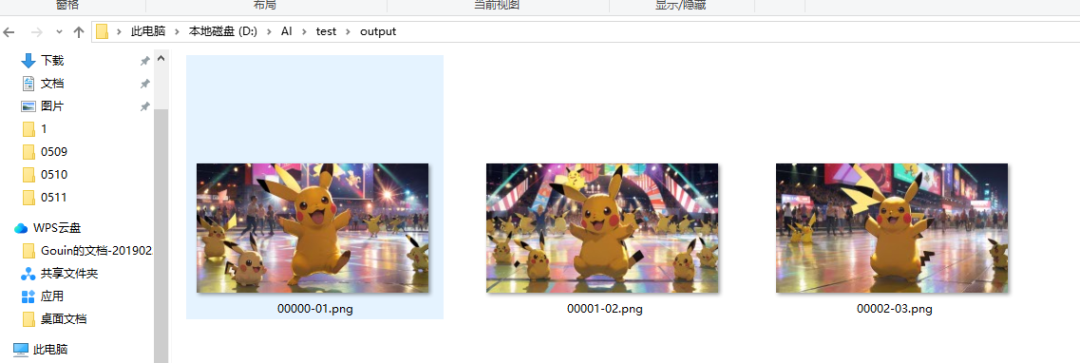
此时我们发现重绘的皮卡丘跟原图有点差异,为了提高重绘的精度,我们还需要学习下面这些进阶功能。
二、在批量处理中使用重绘蒙版
首先我们要了解什么是重绘蒙版?
重绘蒙版可以帮助我们更精细地控制重绘画面中元素的范围,例如我只想重绘皮卡丘而让图像的背景保持不变。
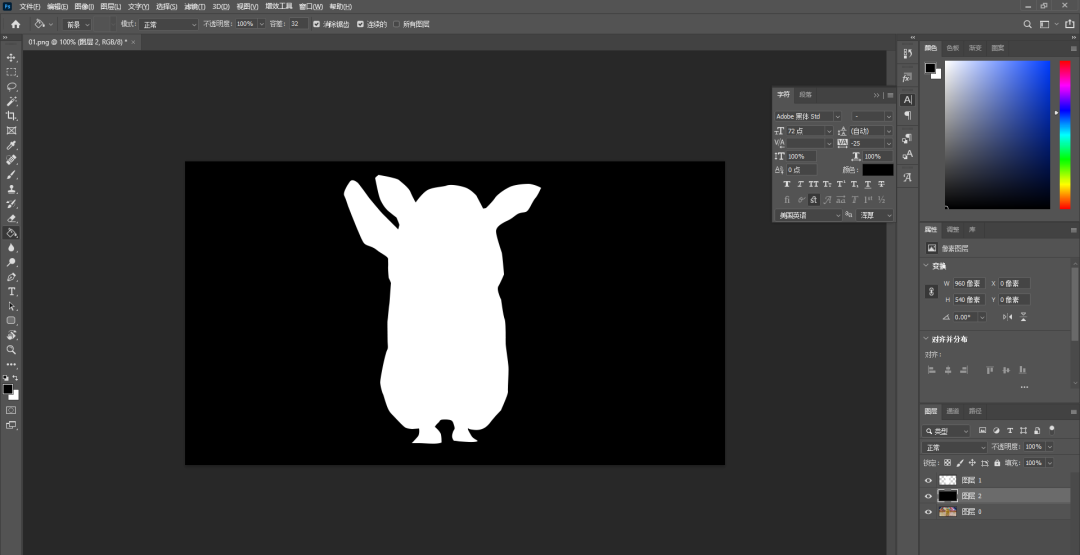
首先我们要用PS等软件给每张要重绘的图片绘制重绘蒙版(注意:白色区域是替换,黑色区域是保留不变的。)
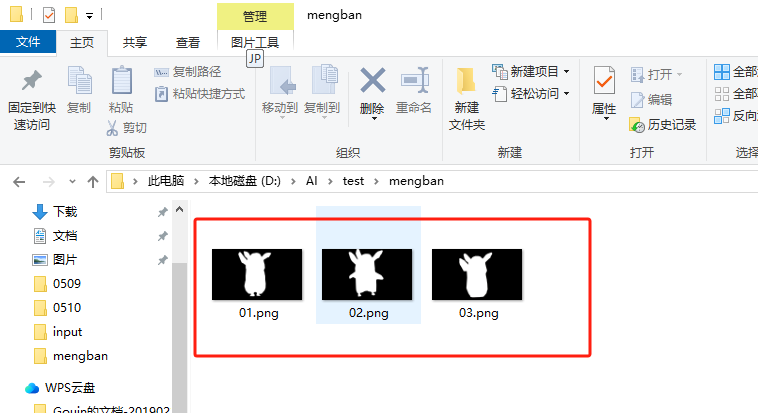
将蒙版文件的目录贴入批量重绘蒙版目录 :
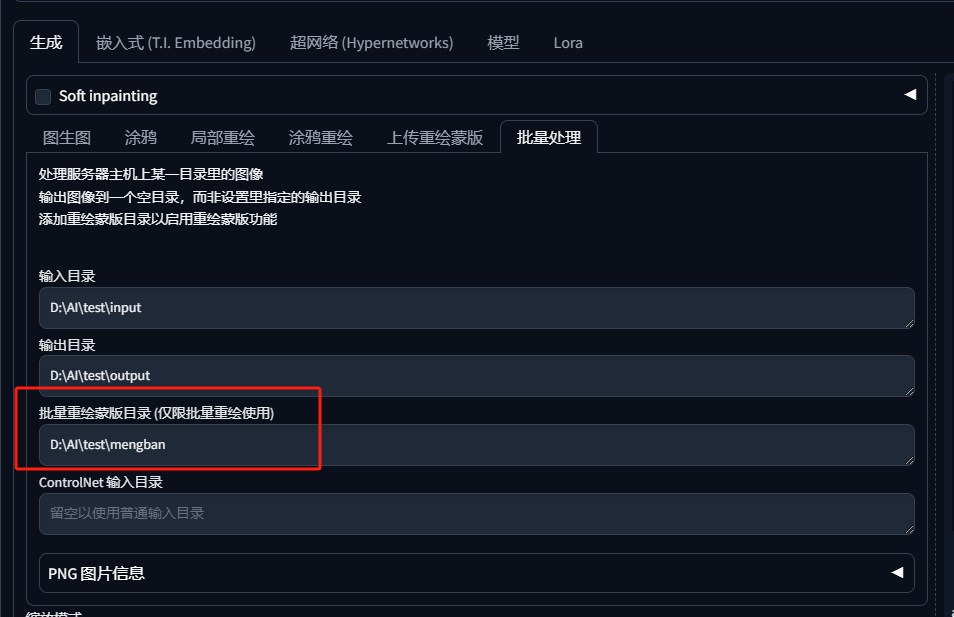
大家可以勾选这个Soft inpainting会让生成的图片过渡更加自然。
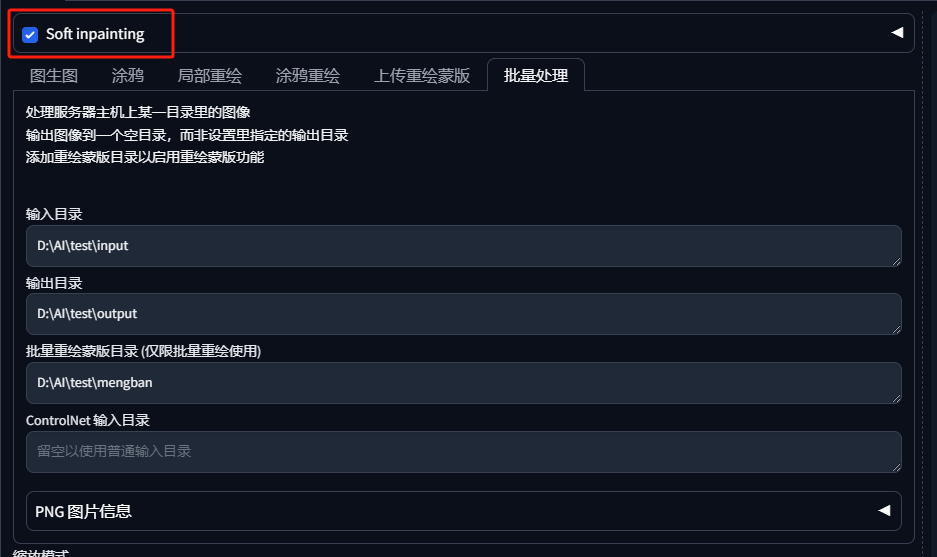

这张没有勾选能看到边缘过渡很硬~

这个勾选后的边缘就和缓多了。
最终我们在输出文件夹内就获得了我们用重绘蒙版获得的图片,可以看到背景跟原图基本保持了一致,只有皮卡丘被重绘了。


三、在批量处理中使用controlnet
为了让重绘的图片中皮卡丘的动作更加贴近原图,在这里我们还可以使用controlnet来批量重绘。
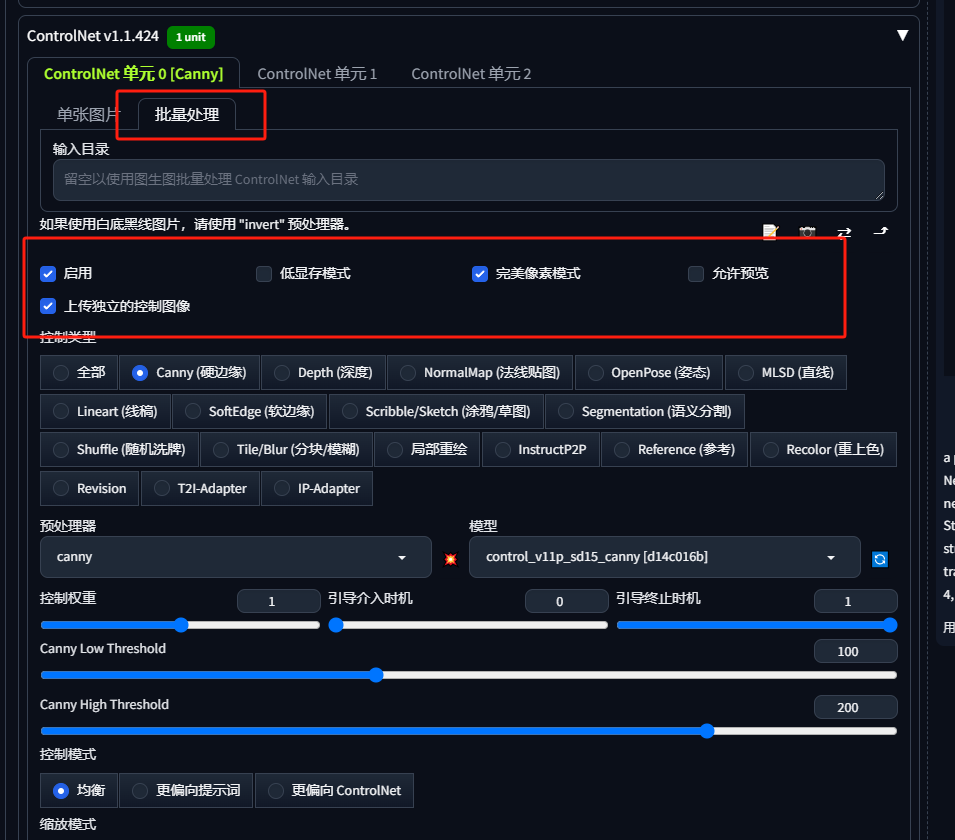
首先,打开controlnet点击启动、完美像素模式和上传独立控制的图像后选择批量处理,控制类型选择硬边缘,注意这里的目录可以先空着。
为了更好的控制图像,我们可以再增加一个controlnet,控制类型选择深度,输入目录同样不填。
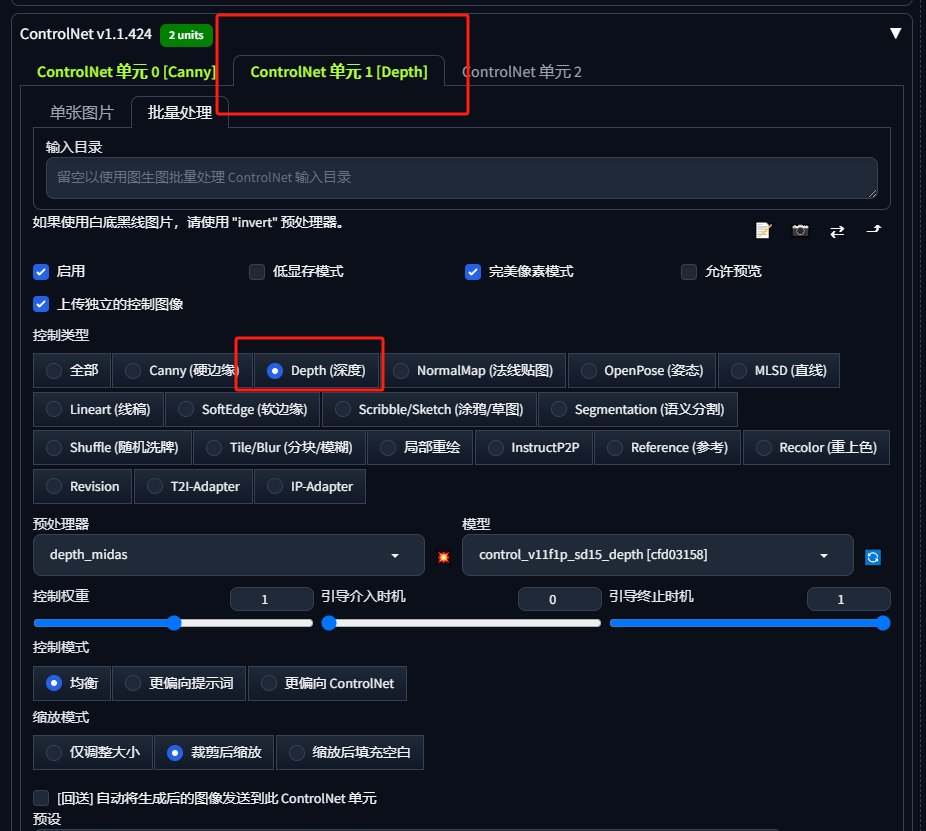
然后我们回到上面的批量重绘那里,将原图的地址输入到这个controlnet输入目录这里:
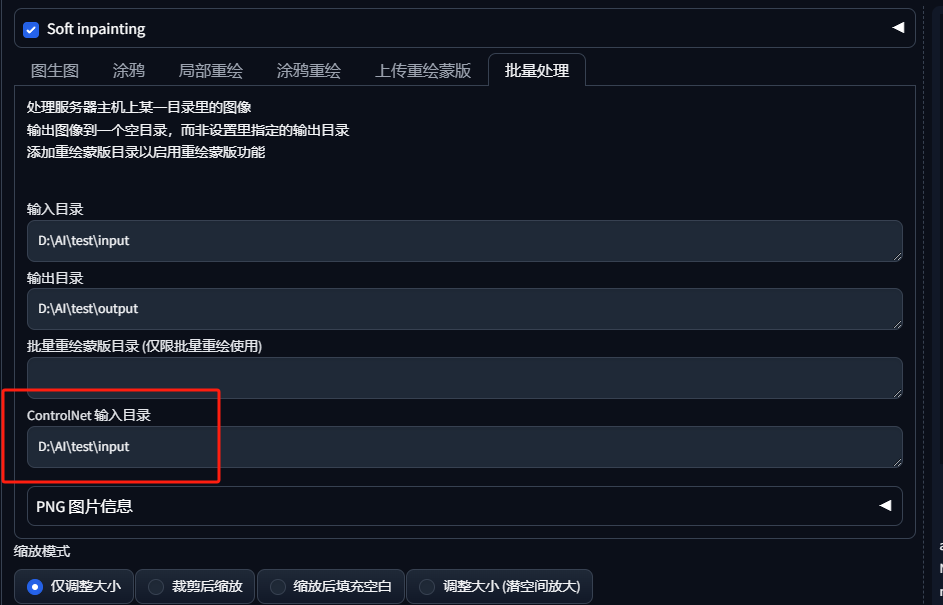
最后我们就生成跟原图比较接近的重绘图像啦,经过测试,利用controlnet来批量重绘比重绘蒙版更方便效果也更好一些!


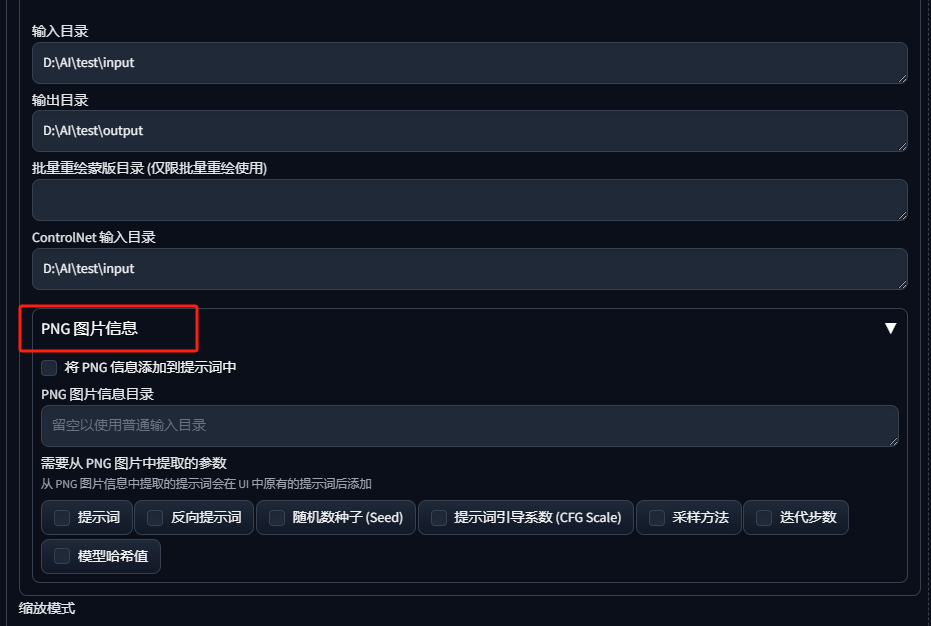
四、在批量处理中使用png图片信息
png图片信息适合当重绘不同的场景时使用。例如我们要重绘三张图,分别为一个皮卡丘、一棵树和一个初音未来:
然后针对这三个元素各自先用文生图生成一张图片:
**Prompt:**a pikachu,in the dance,best quality,masterpiece,best quality

**Prompt:**a tree,best quality,
masterpiece,HDR,UHD,8K,best quality,masterpiece

**Prompt:**hatsune miku,best quality,masterpiece,HDR,UHD,8K,best
quality,masterpiece

将这三张携带有png信息的图片放置到一个文件夹内:

将目录填入png图片信息目录,打钩提示词、反向提示词、采样方法、迭代步数,并清空图生图的提示词 :
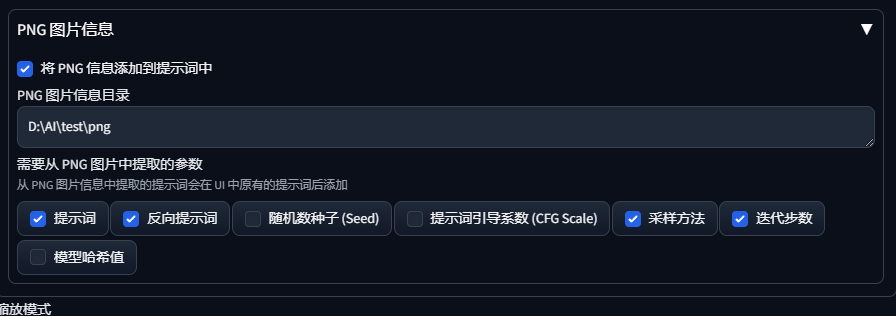
最后我们生图看一下效果:

原图
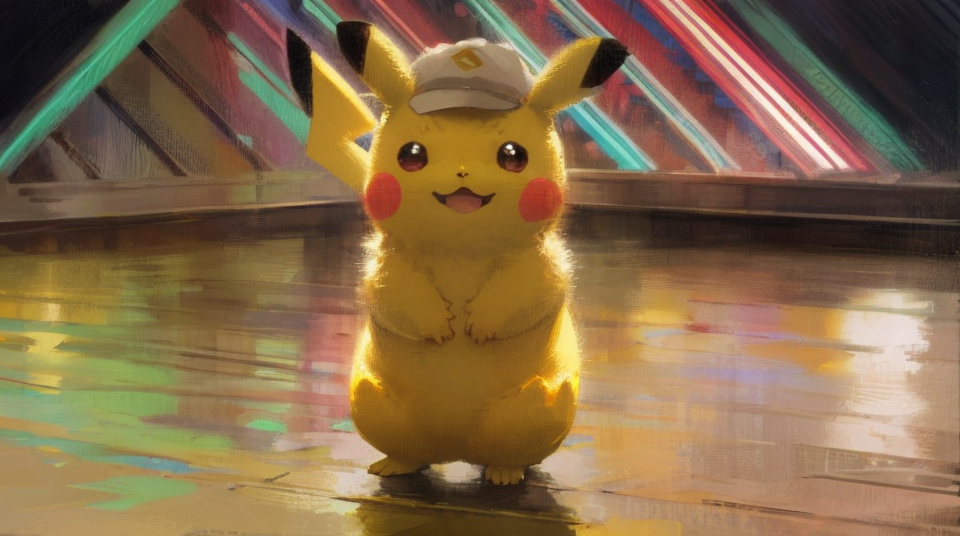
重绘后

原图

重绘后

原图

重绘后
文章使用的AI绘画SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。
这里直接将该软件分享出来给大家吧~
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

1.stable diffusion安装包
随着技术的迭代,目前 Stable Diffusion 已经能够生成非常艺术化的图片了,完全有赶超人类的架势,已经有不少工作被这类服务替代,比如制作一个 logo 图片,画一张虚拟老婆照片,画质堪比相机。
最新 Stable Diffusion 除了有win多个版本,就算说底端的显卡也能玩了哦!此外还带来了Mac版本,仅支持macOS 12.3或更高版本。

2.stable diffusion视频合集
我们在学习的时候,往往书籍源码难以理解,阅读困难,这时候视频教程教程是就很适合了,生动形象加上案例实战,一步步带你入坑stable diffusion,科学有趣才能更方便的学习下去。

3.stable diffusion模型下载
stable diffusion往往一开始使用时图片等无法达到理想的生成效果,这时则需要通过使用大量训练数据,调整模型的超参数(如学习率、训练轮数、模型大小等),可以使得模型更好地适应数据集,并生成更加真实、准确、高质量的图像。

4.stable diffusion提示词
提示词是构建由文本到图像模型解释和理解的单词的过程。可以把它理解为你告诉 AI 模型要画什么而需要说的语言,整个SD学习过程中都离不开这本提示词手册。

5.SD从0到落地实战演练

如果你能在15天内完成所有的任务,那你堪称天才。然而,如果你能完成 60-70% 的内容,你就已经开始具备成为一名SD大神的正确特征了。
这份完整版的SD整合包已经上传优快云,朋友们如果需要可以微信扫描下方优快云官方认证二维码免费领取【保证100%免费】

















 762
762

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









