






大家好,这里是阿道夫!!
今天跟大家分享如何使用Stable Diffusion制作超萌卡通证件照



安装Roop插件
Roop插件是一种可以让你在图片或视频中替换人脸的人工智能模型,它只需要一张目标人脸的图片,不需要数据集或训练。
项目地址:https://github.com/s0md3v/sd-webui-roop
1.插件 安装****
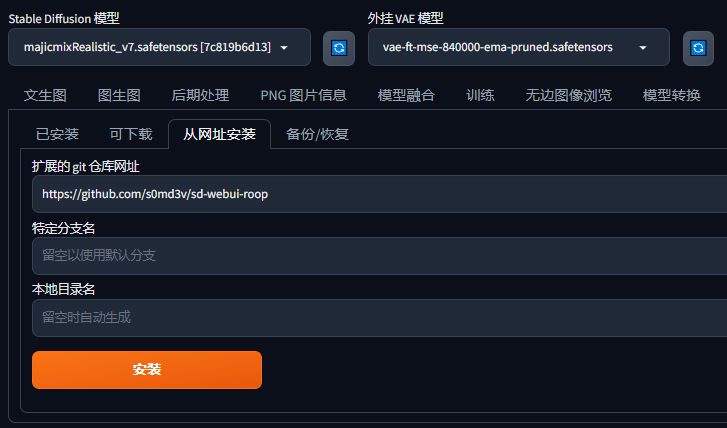
2.下载模型
模型下载完成后,按照压缩包里面的readme.txt进行配置。
下载地址:如有需要请私信我。
3.配置模型
因为我自己是搞开发的,Python/C++等开发环境早已经安装好,所以只需要进行下面配置(记得将下面的"用户名"替换成你自己的Windows帐户名):
-
inswapper_128.onnx -> 复制到: SD根目录\models\roop
-
detector.onnx -> 复制到:C:\Users\用户名\.ifnude
-
classes -> 复制到:C:\Users\用户名\.ifnude
-
buffalo_l.zip -> 解压复制到:C:\Users\用户名\.insightface\models\buffalo_l
配置完成后,重启Stable Diffusion启动器,就能在首页的插件列表看到Roop。

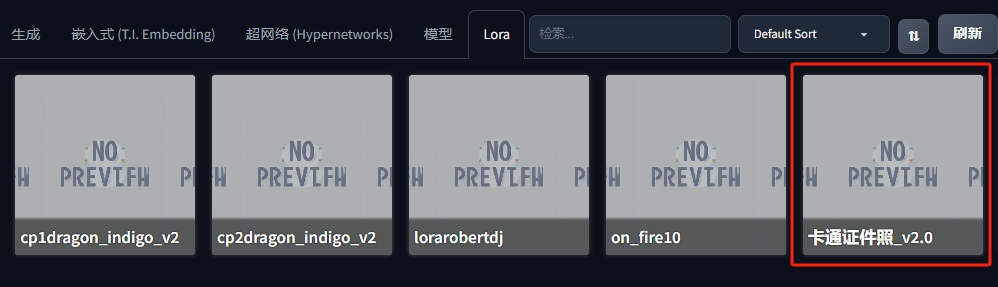
卡通证件照Lora模型
将真人证件照处理成卡通风格需要用到:卡通证件照_v2.0.safetensors
下载完成后拷贝到:SD根目录\models\Lora,刷新后就可以看到卡通证件照_v2.0了。
下载地址:如有需要请私信我。

制作证件照底图
首先来制作证件照底图,参数配置如下:
-
Stable Diffusion模型: majicmixRealistic_v7.safetensors
-
外挂VAE模型: vae-ft-mse-84000-ema-pruned.safetensors
-
正向提示词: identification photo,1 girl,long hair,bangs,looking at viewer,(white shirt,blue tie,red background:1.2),smile,
-
反向提示词: bad-hands-5,EasyNegativeV2,ng_deepnegative_v1_75t,bad-image-v2-39000,
-
迭代步数 (Steps): 24
-
采样方法 (Sampler): DPM++ 2M SDE Karras
抽卡得到以下底图:

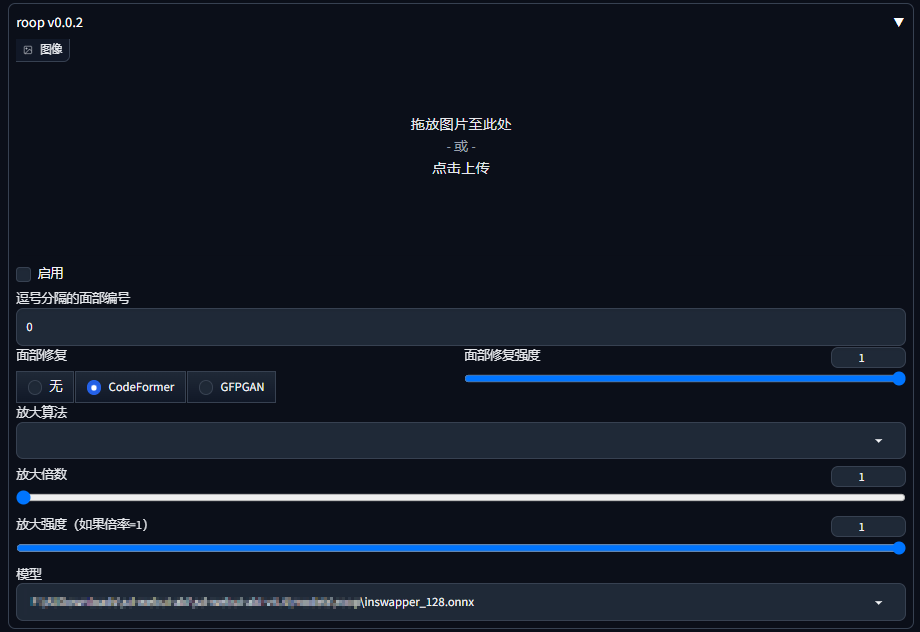
使用Roop插件进行人脸替换
将上个步骤抽卡得到的证件照底图发送到图生图局部重绘选项卡,只重绘人脸部分,然后进行以下参数配置:
1.基础参数配置
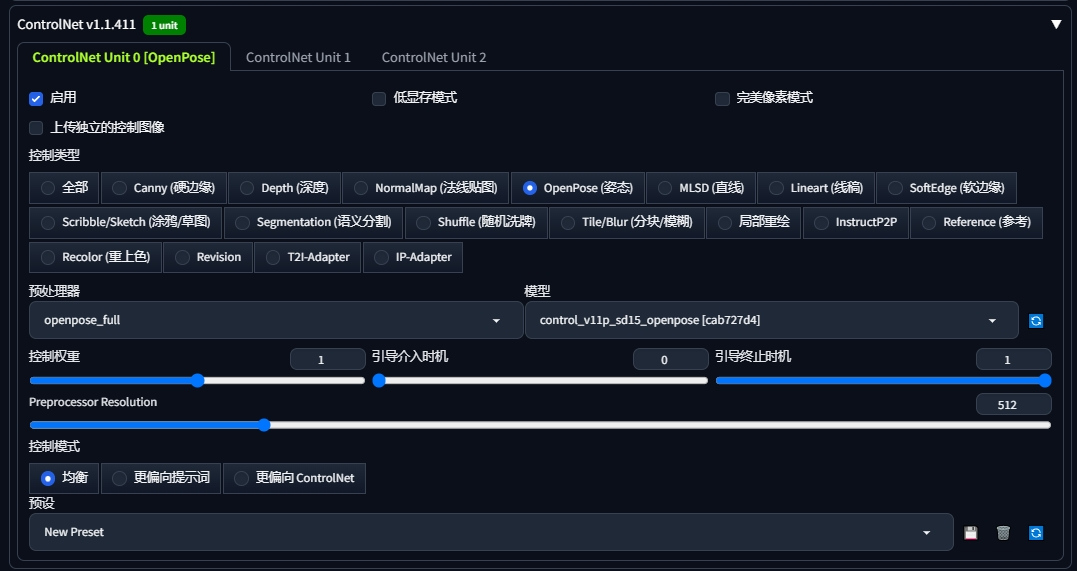
2.ControlNet参数配置
如果想保持跟证件底图一样的表情,就必须开启ControlNet进行姿态控制,不然最后生成出来的表情有可能跟底图不一致。
-
ControlNet: 启用
-
控制类型: OpenPose(姿态)
-
预处理器: openpose_full
-
模型: control_v11p_sd15_openpose
-
控制权重: 1
-
控制模式: 均衡
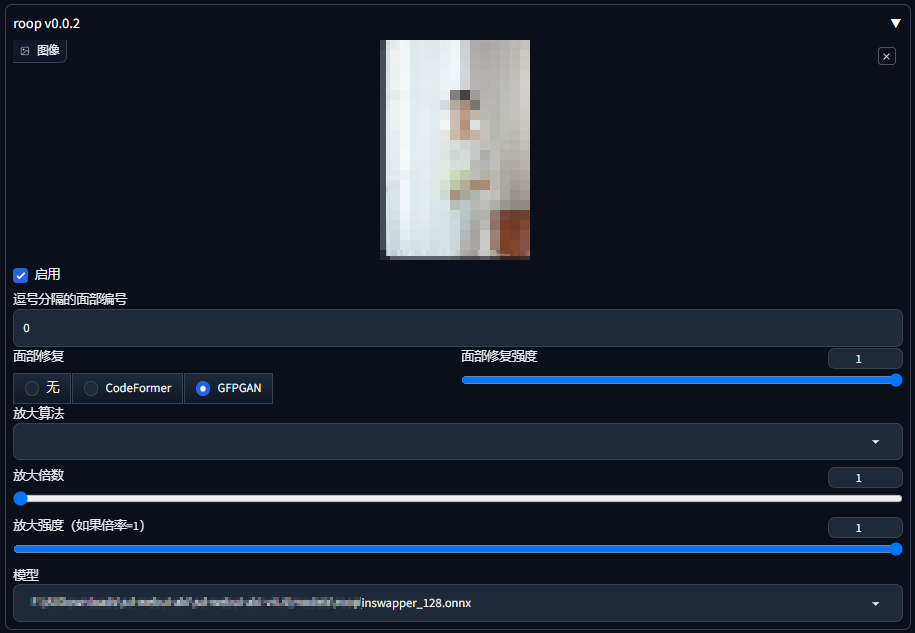
3.Roop插件参数配置
点击上传需要换脸的照片。这里我使用的是经过AI处理的领导照片。
-
Roop: 启用
-
面部修复: GFPGAN
-
其他参数: 保持默认
配置完成后,生成得到以下效果:


生成卡通证件照
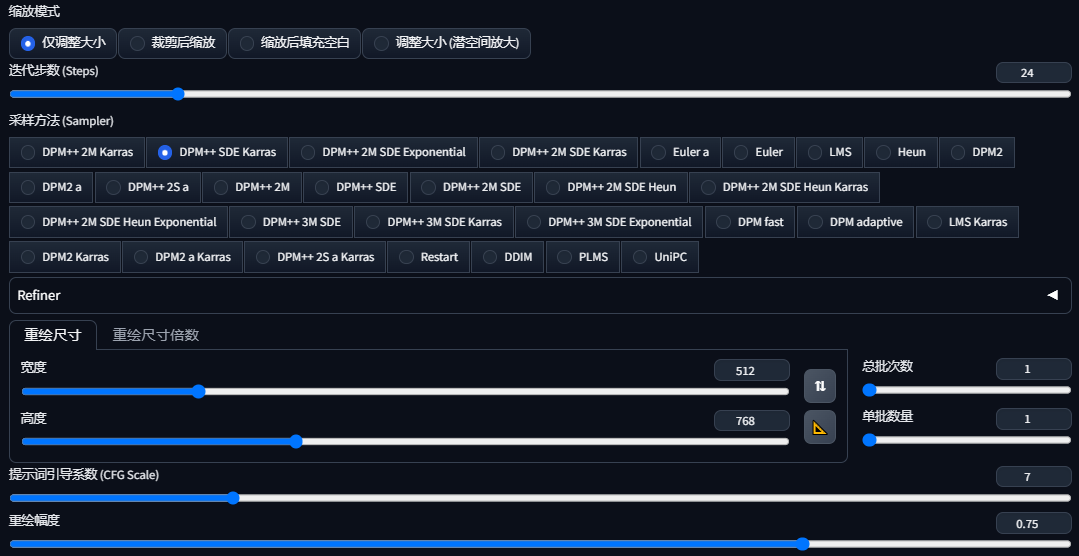
将上个步骤得到的证件底图发送到图生图选项卡,然后进行以下参数配置:
-
正向提示词: identification photo,1 girl,long hair,bangs,looking at viewer,(white shirt,blue tie,red background:1.2),smile,lora:卡通证件照\_v2.0:0.9,
-
迭代步数 (Steps): 24
-
采样方法: DPM++ SDE Karras
-
迭代步数 (Steps): 24
-
提示词引导系数 (CFG Scale): 7
-
重绘幅度: 0.75
-
ControlNet: 与上个步骤保持一致
-
Roop: 与上个步骤保持一致
点击生成后,出来的效果:


图片放大处理
这里介绍的图片放大处理主要是利用SD的后期处理功能来实现。
将图片拖进后期处理的图片来源里面,缩放比例选择2倍(缩放到1024x1536),放大算法则选择:R-ESRGAN 4x+
Anime6B,这个算法效果看起来更立体更动漫一些,如果是要比较真实的效果可以选择:ESRGAN_4x。
放大处理完成后,就是文章开头的最终效果。
本期封面:

nvert/509ec301d821608d6411c3b5e4f55b2c.png)
放大处理完成后,就是文章开头的最终效果。
本期封面:
文章使用的AI工具SD整合包、各种模型插件、提示词、AI人工智能学习资料都已经打包好放在网盘中了,无需自行查找,有需要的小伙伴文末扫码自行获取。

这是一位SD资深大神整理的,100款Stable Diffusion超实用插件,涵盖目前几乎所有的,主流插件需求。
全文超过4000字。
我把它们整理成更适合大家下载安装的【压缩包】,无需梯子,并根据具体的内容,拆解成一二级目录,以方便大家查阅使用。
单单排版就差不多花费1个小时。
希望能让大家在使用Stable Diffusion工具时,可以更好、更快的获得自己想要的答案,以上。
如果感觉有用,帮忙点个支持,谢谢了。
100款Stable Diffusion插件:
面部&手部修复插件:After Detailer
在我们出图的时候,最头疼的就是出的图哪有满意,就是手部经常崩坏。只要放到 ControlNet 里面再修复。
现在我们只需要在出图的时候启动 Adetailer 就可以很大程度上修复脸部和手部的崩坏问题
AI换脸插件:sd-webui-roop
换脸插件,只需要提供一张照片,就可以将一张脸替换到另一个人物上,这在娱乐和创作中非常受欢迎。
模型预设管理器:Model Preset Manager
这个插件可以轻松的创建、组织和共享模型预设。有了这个功能,就不再需要记住每个模型的最佳 cfg_scale、实现卡通或现实风格的特定触发词,或者为特定图像类型产生令人印象深刻的结果的设置!
现代主题:Lobe Theme
已经被赞爆的现代化 Web UI 主题。相比传统的 Web UI 体验性大大加强。
提示词自动补齐插件:Tag Complete
使用这个插件可以直接输入中文,调取对应的英文提示词。并且能够根据未写完的英文提示词提供补全选项,在键盘上按↓箭头选择,按 enter 键选中
提示词翻译插件:sd-webui-bilingual-localization
这个插件提供双语翻译功能,使得界面可以支持两种语言,对于双语用户来说是一个很有用的功能。
提示词库:sd-webui-oldsix-prompt
提供提示词功能,可能帮助用户更好地指导图像生成的方向。
上千个提示词,无需英文基础快速输入提示词,该词库还在不断更新。
以后再也不担心英文写出不卡住思路了!
由于篇幅原因,有需要完整版Stable Diffusion插件库的小伙伴,点击下方插件即可免费领取


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









