







 针对SpringDataJPA saveAll()方法在批量保存数据时效率低下的问题,本文介绍了如何通过调整应用配置,启用批量处理来显著提高保存速度,并分享了在生产环境中遇到的进一步优化需求及解决方案。
针对SpringDataJPA saveAll()方法在批量保存数据时效率低下的问题,本文介绍了如何通过调整应用配置,启用批量处理来显著提高保存速度,并分享了在生产环境中遇到的进一步优化需求及解决方案。
spring data jpa saveAll() 保存过慢
问题发现
今天在生产环境执行保存数据时 影响队列中其他程序的运行 随后加日志排查 发现 执行 4500条 insert操作时 耗时 9分钟 我类个去…
解决方案1 此方案在第二天失效了 😦
废话不多说 直接上配置文件参数
application-prod.yml 部分参数如下
jpa:
show-sql: false
hibernate:
ddl-auto: none
properties:
hibernate:
jdbc:
#为spring data jpa saveAll方法提供批量插入操作 此处可以随时更改大小 建议500哦
batch_size: 500
batch_versioned_data: true
order_inserts: true
通过日志打印 执行结果如下
未开批处理 4507条 耗时: 227167ms
开启批处理 500/次 4507条 耗时: 29140ms
开启批处理 1000/次 4507条 耗时: 29631ms
以上方案有问题,下面附上彻底解决的截图和记录 😃
后来发现在生产运行了一天 还是会导致保存阻塞的问题 100条保存耗时 9分钟!!!
数据库此时数据有300w条
于是分析 saveAll()的源代码
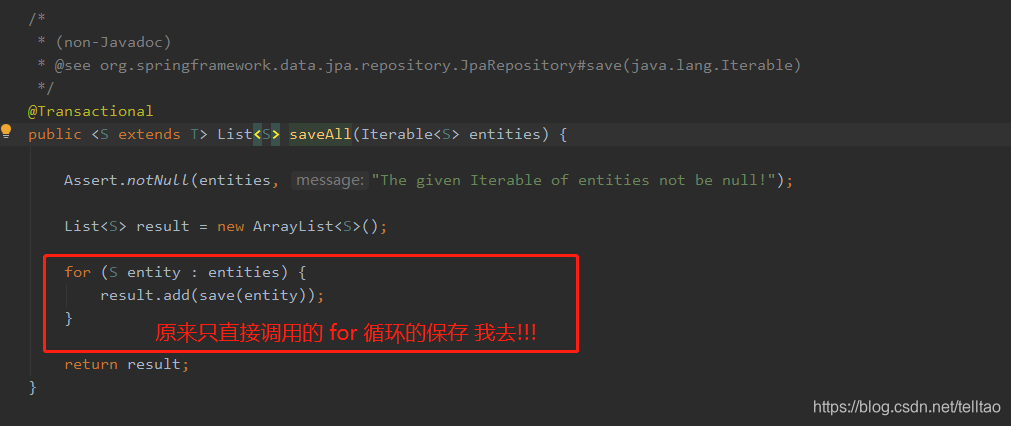
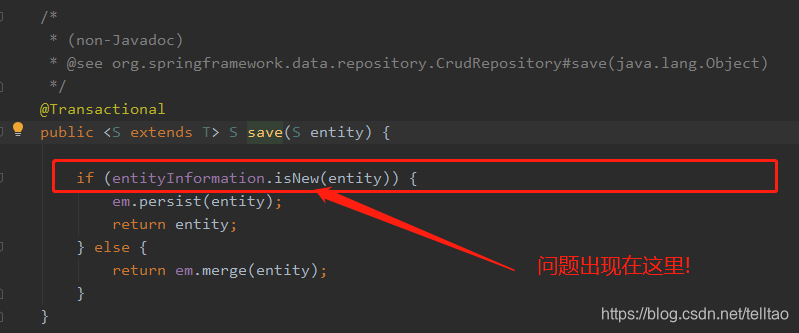
原来这个保存的时候 会去数据库查询这条数据是否存在 如果存在 则修改 不存在则直接添加 如下图
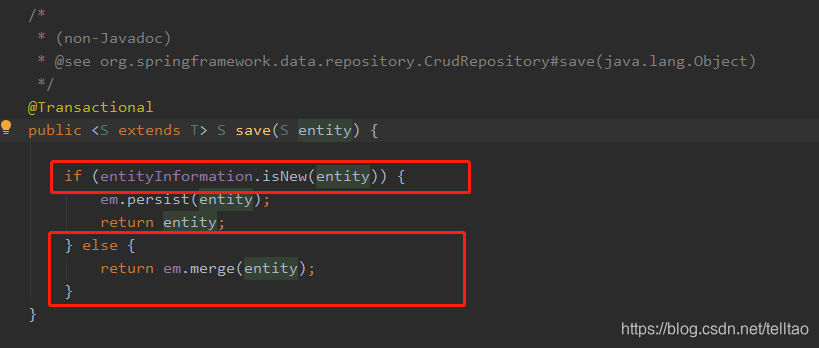
重写 saveAll() 的方法 就是仿照它 for循环里面直接调用 save()方法
@PersistenceContext()
protected EntityManager em;
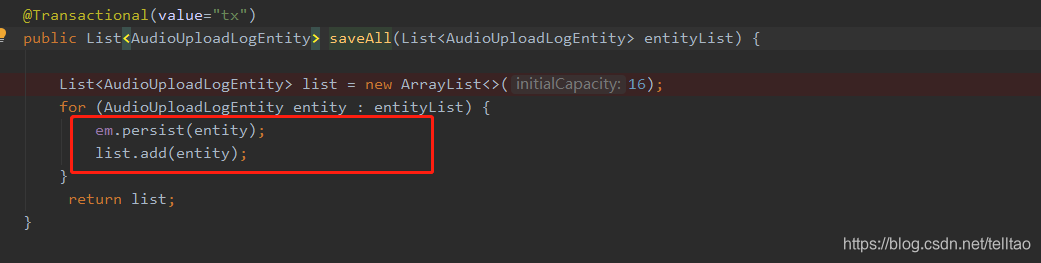
此处你们可以改成泛型的方式,提取公共类,封装一下即可。

















 4718
4718

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









