




一、初步认识
1、NoSQL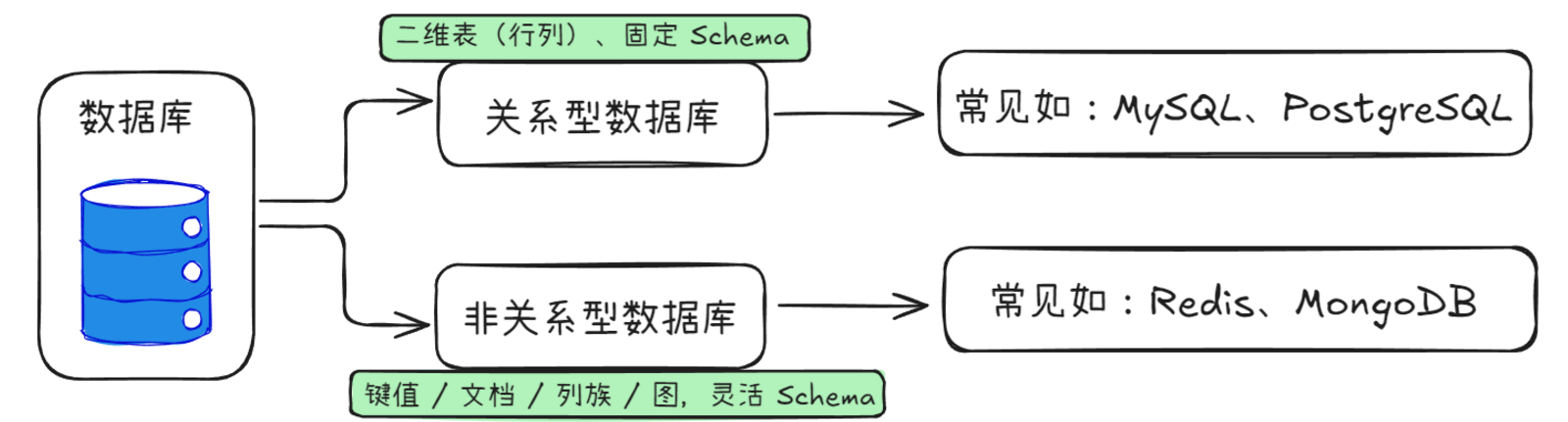
SQL = 关系型数据库(表结构,强一致)NoSQL = 非关系型数据库(灵活结构,最终一致,水平扩展爽)
| 维度 | SQL(关系型) | NoSQL(非关系型) |
|---|---|---|
| 数据模型 | 二维表:行列、固定模式(Schema) | 键值、文档、列族、图等,可动态加字段 |
| 查询语言 | 标准 SQL:SELECT / JOIN / GROUP / TRANSACTION | 各写各的:Redis 命令、MongoDB JSON DSL、Cassandra CQL… |
| 事务 & 一致性 | ACID 强一致(原子、一致、隔离、持久) | BASE 最终一致(基本可用、软状态、最终一致) |
| 扩展方式 | 纵向扩容(买更贵的机器)+ 复杂分库分表 | 横向扩容(加普通机器就 OK) |
| 典型代表 | MySQL、PostgreSQL、Oracle、SQL Server | Redis(键值)、MongoDB(文档)、Cassandra(列族)、Neo4j(图) |
| 适用场景 | 复杂关联、账务、报表、强一致核心业务 | 高并发读写、海量数据、灵活模式、快速迭代 |
2、Redis
Redis(Remote Dictionary Server)是一个开源的、基于内存的 高性能键值数据库,它支持多种数据结构,常用于缓存、消息队列、排行榜、实时统计等场景。
| 特性 | 说明 |
|---|---|
| 内存存储 | 数据主要存在内存中,读写速度极快(每秒十万次以上) |
| 持久化支持 | 支持将内存数据保存到磁盘(RDB 快照 和 AOF 日志) |
| 多种数据结构 | 字符串、列表、集合、哈希、有序集合、位图、HyperLogLog、Stream 等 |
| 支持过期时间 | 可设置 key 的 TTL,自动删除过期数据 |
| 发布/订阅功能 | 可用作轻量级消息队列 |
| 主从复制 + 哨兵 + 集群 | 支持高可用和分布式部署 |
注意:Redis 是内存数据库,内存有限,不能当成 MySQL 那种“海量永久存储”来用。适合热数据或临时数据。
2.1、创建容器
# 拉取最新镜像
# 当然也可以指定版本号
docker pull redis
# 查看是否拉取成功
docker images
# 快速搭建一个无密码的redis容器(不建议)
docker run -d --name <自定义容器名> -p 6379:6379 redis
# 或者搭建一个带密码、持久化数据、自定义配置的redis容器
# 1. 先准备目录和配置文件
# 自定义路径,我以在E盘container文件夹的redis文件夹中准备为例
mkdir -p /mnt/e/container/redis/{conf,data}
touch /mnt/e/container/redis/conf/redis.conf
# 2. 写最小配置 /data/redis/conf/redis.conf
# 可使用以下命令(不过需要将中文注释去除)
# 也可以直接vi编辑文件
cat >/mnt/e/container/redis/conf/redis.conf <<'EOF'
# 若不修改,bind 监听地址默认127.0.0.1,即只允许本地访问,修改为0.0.0.0任意IP均可访问,生产环境不建议修改,当前是测试环境修改为0.0.0.0方便测试
bind 0.0.0.0
port 6379
requirepass <自定义密码>
# 保护模式
protected-mode no
# 持久化设置
appendonly yes
appendfilename "appendonly.aof"
appendfsync everysec
EOF
# 3. 启动
docker run -d --name <自定义容器名> \
-p 6379:6379 \
-v /mnt/e/container/redis/conf/redis.conf:/usr/local/etc/redis/redis.conf \
-v /mnt/e/container/redis/data:/data \
redis redis-server /usr/local/etc/redis/redis.conf
# 验证成功
docker exec -it <自定义容器名> bash
# 连接本容器内的 redis-server
redis-cli -a <自定义密码>
# 添加键值对
set <键> <值>
get <键>2.2、实操演示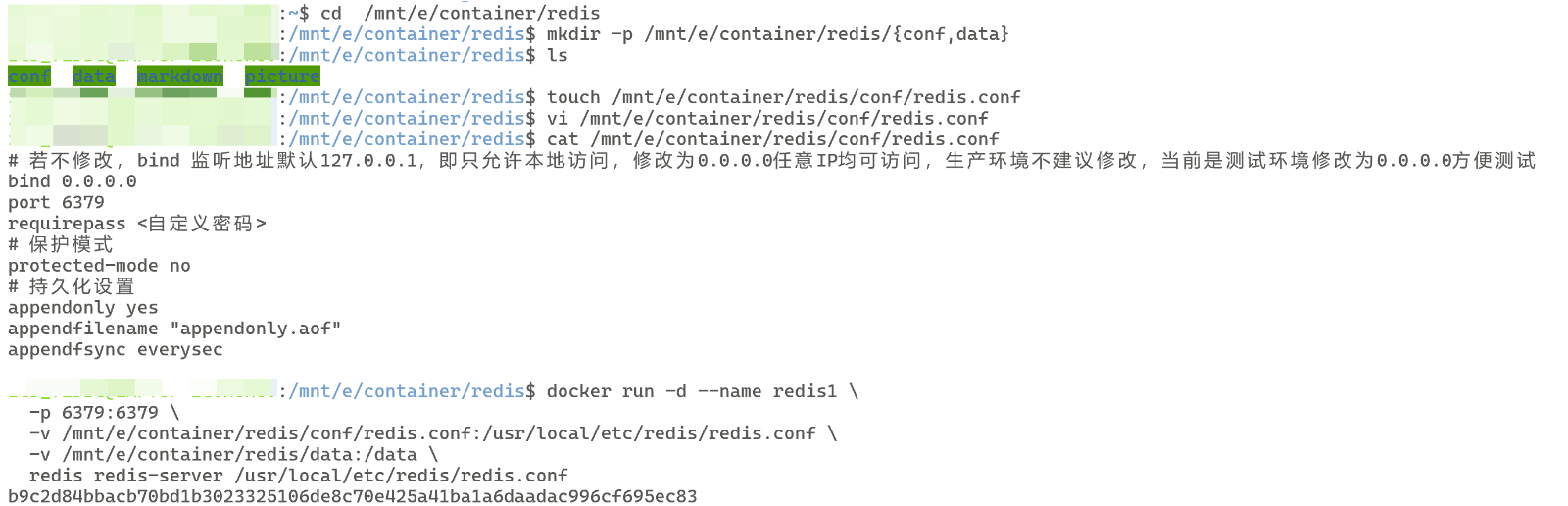

小贴士:vi编辑时可进入粘贴模式以快速编辑
①、刚进入vi编辑模式,默认是普通模式
②、输入 :set paste
③、输入i/a/o进入编辑模式,此时右下角会显示 -- INSERT (paste) --,直接粘贴即可
④、输入esc退回到普通模式
⑤、输入 :set nopaste 退出粘贴模式(下次再进入就是正常插入模式),:wq保存并退出即可
2.3、客户端
redis和MySQL差不多都是一个命令行,一个图形化可视
①、命令行客户端
# 进入命令行
docker exec -it <容器名> redis-cli -a <自定义密码>
# 或者
docker exec -it <自定义容器名> bash
# 连接本容器内的 redis-server
redis-cli -a <自定义密码>②、图形化客户端
Ⅰ、RedisInsight
官方页 https://redisdesktop.com → Download → Windows → 选 .exe(或便携版 .zip)。若访问慢,可直接用 GitHub 发行页:https://github.com/uglide/RedisDesktopManager/releases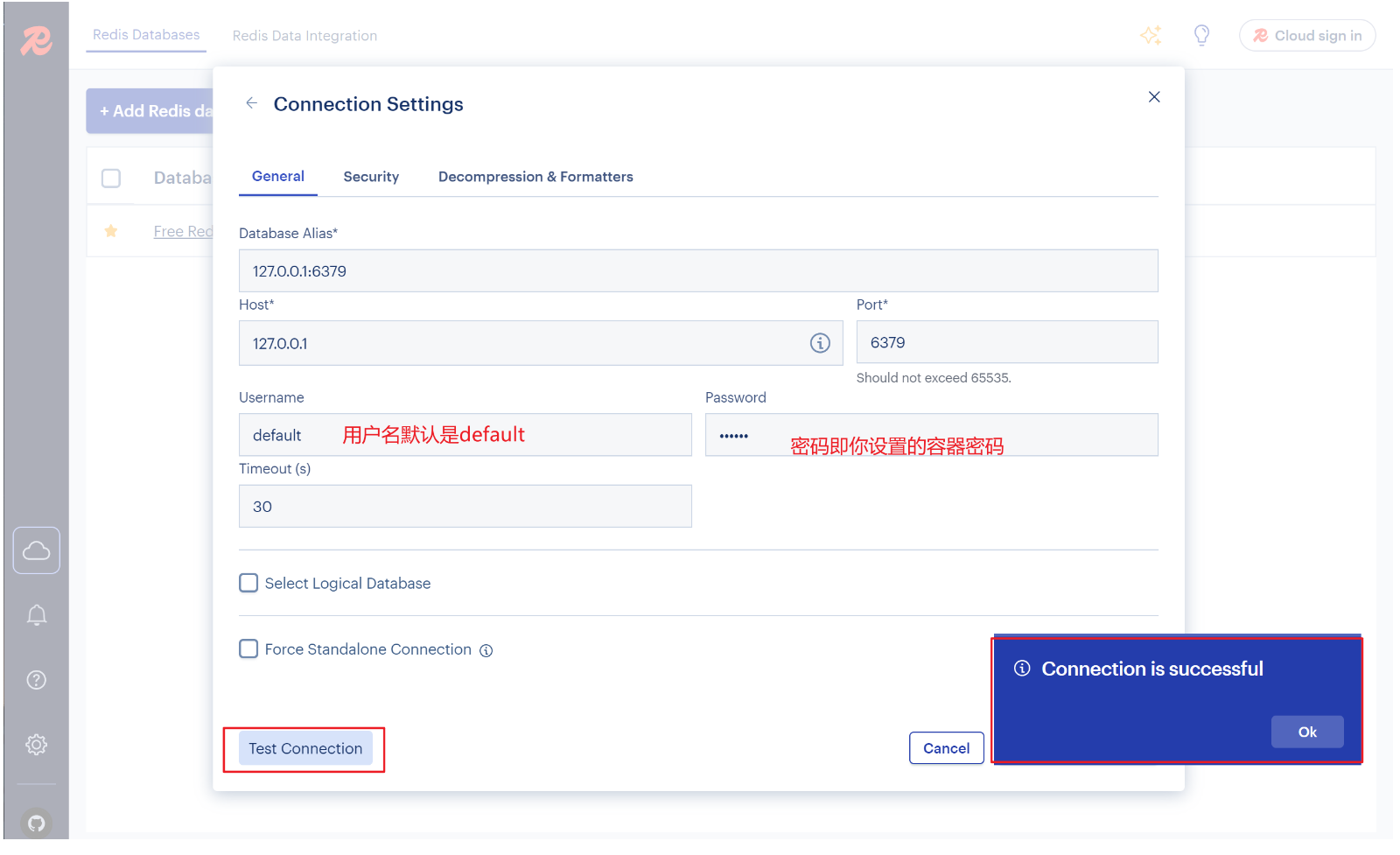
Ⅱ、DataGrip
当然如果由于你的网络问题,无法正确下载出来,考虑到DataGrip 从 2022.3 版本 开始原生支持 Redis,包括单机实例(Single Instance)和键值探索功能,故采用DataGrip 连接redis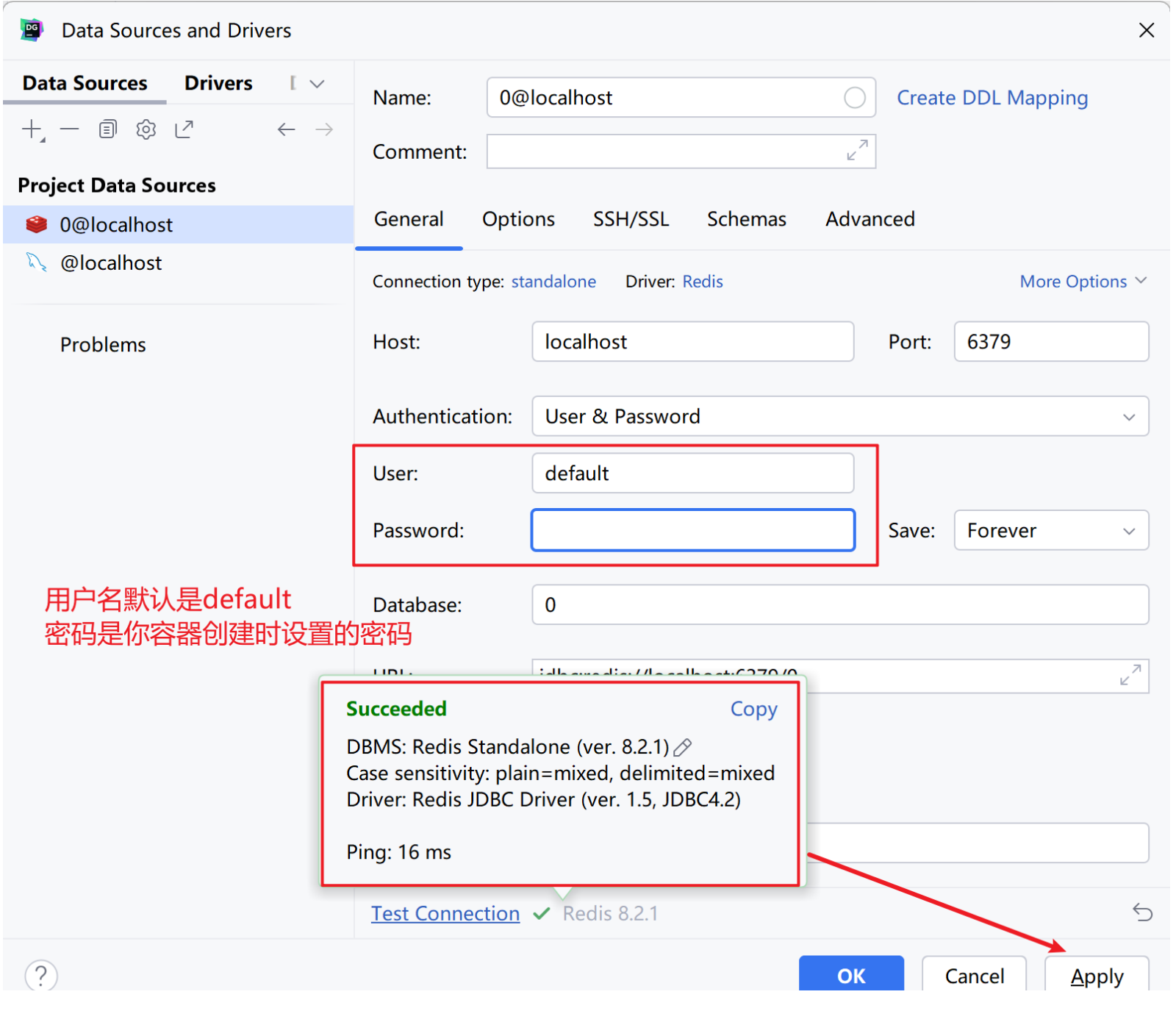
二、常见命令
1、Redis数据结构
1.1、基础数据结构
①、String(字符串)
存储类型:二进制安全的字符串,最大 512MB
②、Hash(哈希表)
存储类型:field-value 映射表
③、List(列表)
存储类型:双向链表
④、Set(集合)
存储类型:无序唯一集合
⑤、Sorted Set(有序集合)
存储类型:带分数的有序集合
1.2、高级数据结构
①、Bitmaps
本质:String 的位操作
②、HyperLogLog
用途:基数统计(去重计数)
③、Geospatial
用途:地理位置信息
底层实现:Sorted Set
④、Stream
用途:消息队列(Redis 5.0+)
2、Redis通用命令
通用命令即对所有数据类型都适用的命令
# 设置键值(支持过期时间)
SET key value [EX seconds|PX milliseconds|EXAT timestamp|PXAT milliseconds-timestamp|KEEPTTL] [NX|XX]
# 获取键值
GET key
# 获取所有键值对,适用于数据量较少
keys *
# 检查键是否存在
EXISTS key [key ...]
# 删除键
DEL key [key ...]
# 查看键类型
TYPE key
# 重命名键
RENAME key newkey
# 设置过期时间(秒)
EXPIRE key seconds
# 设置过期时间(毫秒)
PEXPIRE key milliseconds
# 查看剩余生存时间(秒)
TTL key
# 查看剩余生存时间(毫秒)
PTTL key
# 移除过期时间(持久化)
PERSIST key3、String类型
String 是 Redis 最基本的数据类型,可以存储文本、数字或二进制数据。
3.1、基本特性
存储内容:
-
文本字符串(最大 512MB)
-
数字(整数或浮点数)
-
二进制数据(如图片序列化)
底层实现:
-
简单动态字符串(SDS, Simple Dynamic String)
-
根据内容自动选择编码方式:
-
int:8字节长整型 -
embstr:≤44字节字符串 -
raw:>44字节字符串
-
3.2、常用命令
# 设置键值(支持过期时间)
SET key value [EX seconds] [PX milliseconds] [NX|XX]
# 获取值
GET key
# 批量设置
MSET key1 value1 key2 value2
# 批量获取
MGET key1 key2
# 获取字符串长度
STRLEN key
# 有就插入失败,无则插入成功
SETNX key value
# 将SET和EXPIRE合二为一
SETEX key seconds value
# 整数递增
INCR key # +1
INCRBY key 5 # +n
# 整数递减
DECR key # -1
DECRBY key 3 # -n
# 浮点数增减
# 浮点数必须指定步长
INCRBYFLOAT key 2.5
# 设置指定位的值(0/1)
SETBIT key offset value
# 获取指定位的值
GETBIT key offset
# 统计值为1的位数
BITCOUNT key [start end]
# 位运算(AND/OR/XOR/NOT)
BITOP AND destkey srckey1 srckey2
# 追加内容
APPEND key value
# 获取子串
GETRANGE key start end
# 覆盖子串
SETRANGE key offset value
# 设置新值并返回旧值
GETSET key newvalue3.3、层级结构
Redis 虽然本身是扁平的键值存储,但通过合理的命名规范可以实现逻辑上的层级结构,提高数据组织性和可维护性。使用 : 作为层级分隔符。

4、哈希类型
哈希是 Redis 中用于存储对象数据的理想数据结构,它特别适合存储具有多个字段的键值对集合。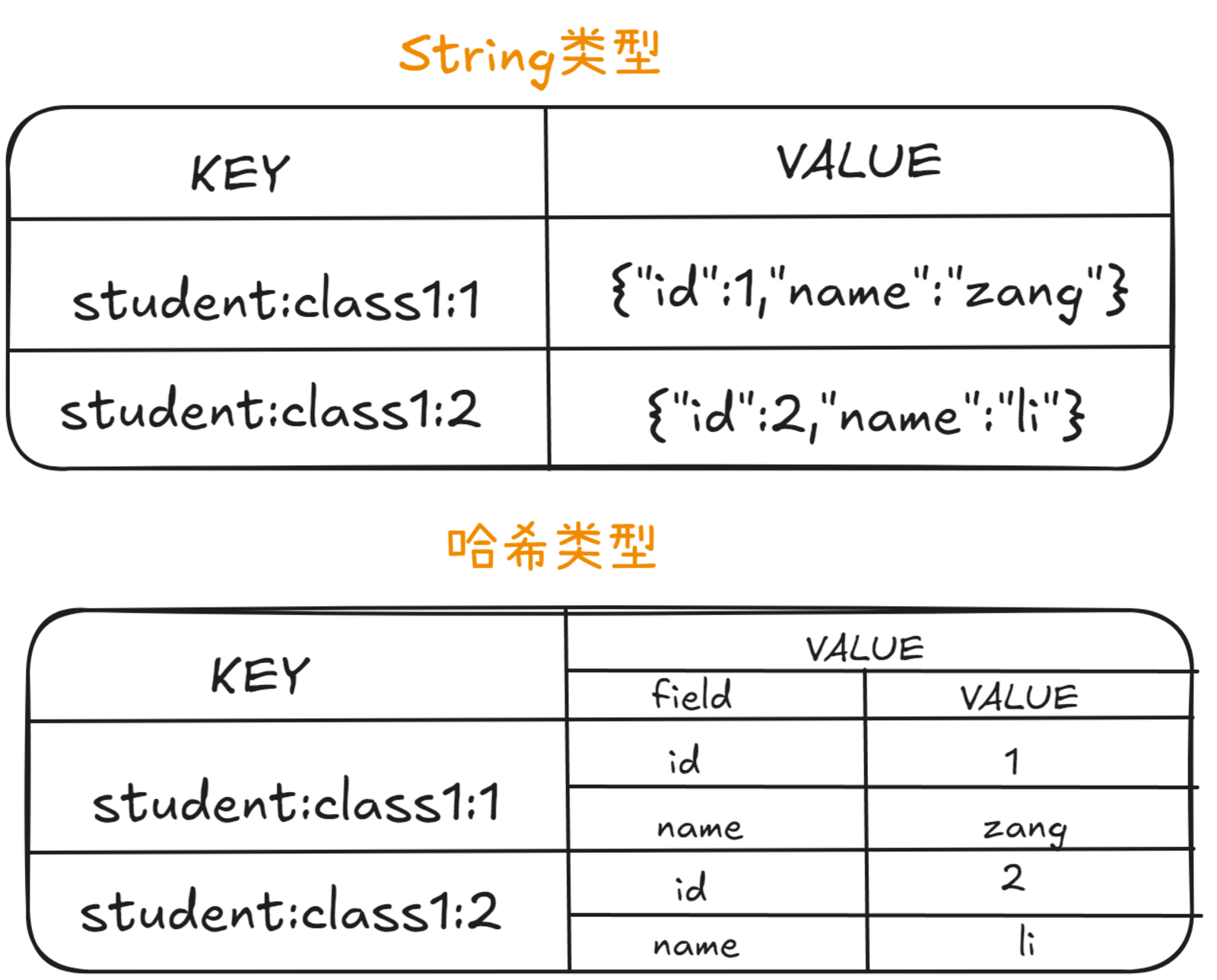
4.1、基本特性
①、存储结构:
-
键值对集合,键是字符串,值可以是字符串或数字
-
每个哈希最多可存储 2³² -1 个字段-值对(约40亿)
②、底层实现:
-
ziplist(压缩列表):当字段数 ≤
hash-max-ziplist-entries(默认512)且所有值 ≤hash-max-ziplist-value(默认64字节) -
hashtable(哈希表):不满足上述条件时自动转换
③、适用场景:
-
对象存储(用户信息、商品属性)
-
频繁访问部分字段的场景
-
需要原子更新多个字段的场景
4.2、常用命令
# 设置字段值
HSET key field value [field value ...]
# 获取字段值
HGET key field
# 检查字段是否存在
HEXISTS key field
# 删除字段
HDEL key field [field ...]
# 获取所有字段值
HGETALL key
# 批量设置
HMSET key field1 value1 field2 value2 # 新版HSET已兼容
# 批量获取
HMGET key field1 field2
# 获取所有字段名
HKEYS key
# 获取所有字段值
HVALS key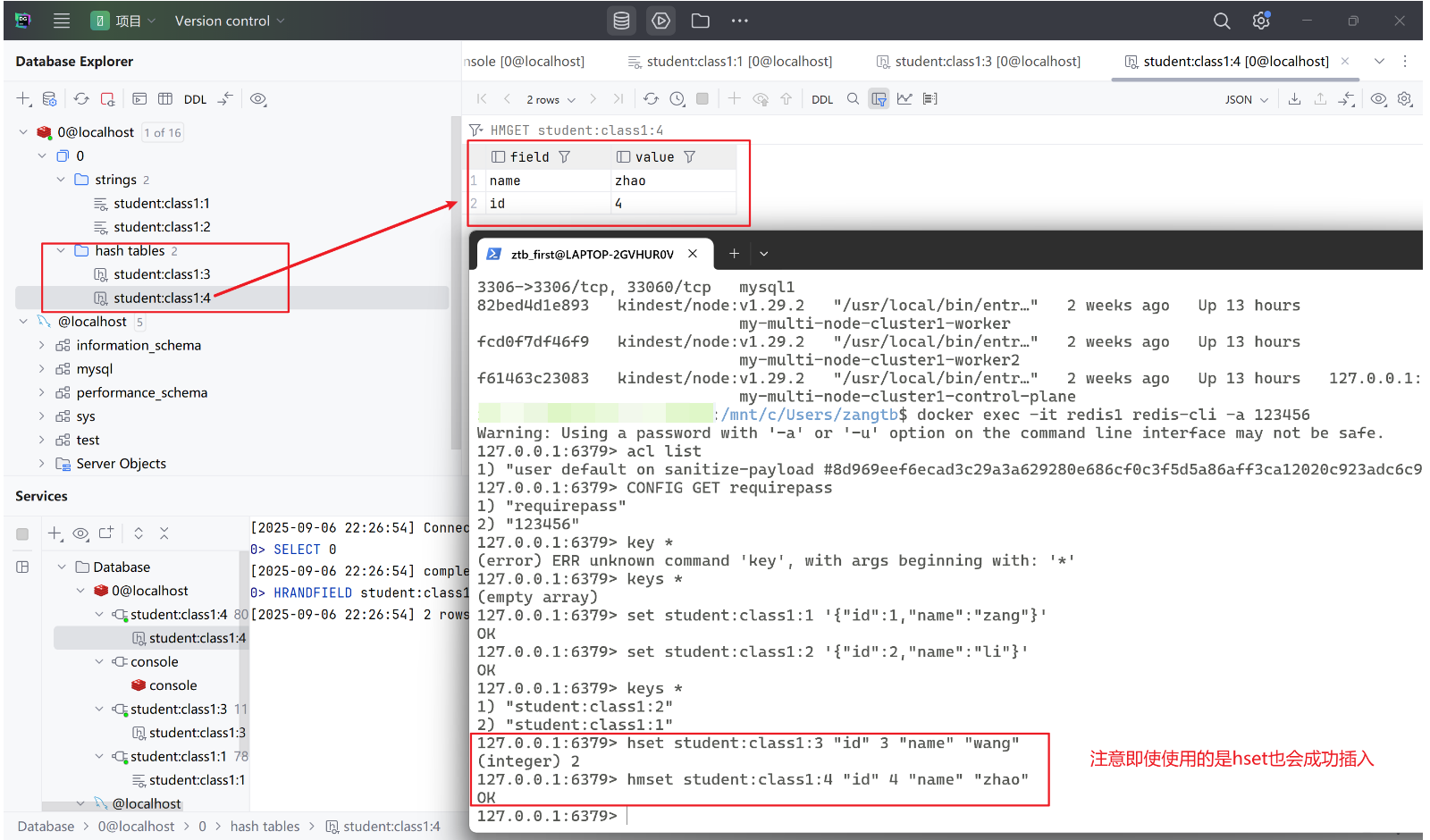
5、List类型
List 是 Redis 中的一种线性数据结构,它按照插入顺序存储多个字符串元素,支持从两端高效插入和删除操作。
类似双向列表,可正向和反向检索
5.1、基本特性
①、存储结构:
-
有序的字符串元素集合
-
每个列表最多可存储 2³² -1 个元素(约40亿)
-
元素可重复
②、底层实现:
-
ziplist(压缩列表):当元素数量 ≤
list-max-ziplist-entries(默认512)且所有元素 ≤list-max-ziplist-value(默认64字节) -
linkedlist(3.2版本前)
-
quicklist(3.2+版本):ziplist组成的双向链表
③、时间复杂度:
-
头尾操作:O(1)
-
按索引访问:O(n)
5.2、常用命令
# 左端插入元素
LPUSH key element [element ...]
# 右端插入元素
RPUSH key element [element ...]
# 左端弹出元素
LPOP key [count] # Redis 6.2+支持批量弹出
# 右端弹出元素
RPOP key [count]
# 获取列表长度
LLEN key
# 获取指定范围内的元素,第一个元素索引是 0
LRANGE key start stop # 包含stop位置
# 修剪列表,只保留指定范围
LTRIM key start stop
# 获取指定位置的元素
LINDEX key index
# 左端阻塞弹出(超时秒)
# 相较于LPOP(没有就报错),BLPOP(可等timeout这么长的时间,之后没有才报错)
BLPOP key [key ...] timeout
# 右端阻塞弹出
BRPOP key [key ...] timeout
# 右端弹出并左端插入到另一列表
BRPOPLPUSH source destination timeout当入口和出口在同一边,即栈(先进后出),如LPUSH和LPOP、RPUSH和RPOP
当入口和出口不在同一边,即队列(先进先出),如LPUSH和RPOP、RPUSH和LPOP
6、SET类型
Set 是 Redis 中的一种无序且唯一的数据结构,它提供高效的成员检查、集合运算等操作
6.1、基本特性
①、存储结构:
-
无序的字符串元素集合
-
元素唯一不重复
-
最大可存储 2³² -1 个元素(约40亿)
②、底层实现:
-
intset(整数集合):当所有元素都是整数且数量 ≤
set-max-intset-entries(默认512) -
hashtable(哈希表):不满足上述条件时使用
③、时间复杂度:
-
添加/删除/检查存在:O(1)
-
集合运算:O(n)
6.2、常用命令
# 添加元素
SADD key member [member ...]
# 删除元素
SREM key member [member ...]
# 获取所有元素
SMEMBERS key
# 检查元素是否存在
SISMEMBER key member
# 获取集合元素数量
SCARD key
# 交集
SINTER key [key ...]
# 并集
SUNION key [key ...]
# 差集(第一个集合有而其他集合没有的元素)
SDIFF key [key ...]
# 运算结果存储到新集合
SINTERSTORE destination key [key ...]
SUNIONSTORE destination key [key ...]
SDIFFSTORE destination key [key ...]7、SortedSet类型
Sorted Set 是 Redis 中一种兼具 Set 的唯一性和排序特性的数据结构,每个元素都关联一个分数(score),可以按分数排序
7.1、核心特性
①、存储结构:
-
唯一成员(member) + 浮点数分数(score)
-
自动按分数排序(默认升序)
-
最大元素数:2³² -1(约40亿)
②、底层实现:
-
ziplist:元素数 ≤
zset-max-ziplist-entries(默认128)且所有元素 ≤zset-max-ziplist-value(默认64字节) -
skiplist + dict:不满足条件时使用(跳表保证有序,字典保证O(1)查询)
③、时间复杂度:
-
添加/删除/更新:O(logN)
-
按分数范围查询:O(logN + M)(M为返回数量)
-
按排名查询:O(logN)
7.2、常用命令
# 添加元素(分数可重复,成员唯一)
ZADD key [NX|XX] [GT|LT] [CH] [INCR] score member [score member ...] # 默认自动升序排序
# 获取元素分数
ZSCORE key member
# 获取元素排名(从0开始)
ZRANK key member # 升序排名
ZREVRANK key member # 降序排名
# 获取集合大小
ZCARD key
# 按分数升序查询
ZRANGE key start stop [WITHSCORES] # 包含stop
ZRANGEBYSCORE key min max [WITHSCORES] [LIMIT offset count]
# 按分数降序查询
ZREVRANGE key start stop [WITHSCORES]
ZREVRANGEBYSCORE key max min [WITHSCORES]
# 查询分数范围内的元素数量
ZCOUNT key min max三、Redis的Java客户端
1、主流客户端
| 客户端 | 维护方 | 特点 | 适用场景 |
|---|---|---|---|
| Jedis | Redis官方 | 轻量级、同步阻塞、API直接,多线程 | 简单应用、传统项目 |
| Lettuce | Spring官方 | 异步非阻塞、Netty实现、功能全面 | 高并发、Spring项目 |
| Redisson | 社区 | 分布式服务、丰富高级功能 | 分布式系统、复杂场景 |
| Spring Data Redis | Spring官方 | 抽象层、统一API、支持多种客户端 | Spring生态整合 |
-
快速脚本、单元测试、低并发 Web
→ Jedis 足够,引入少、代码直观。
-
Spring Boot 2.x+、高并发、响应式 WebFlux
→ Lettuce 是默认,直接
spring-boot-starter-data-redis开箱即用。 -
分布式锁、延迟队列、限流、Tomcat 会话共享、对象映射
→ Redisson 一站式,提供
RLock,RMap,RDelayedQueue等高级 API,节省自研成本
2、快速入门Jedis
为了实现快速入门,我就不进行连接池等配置,而是为了实现最简单的导入依赖,测试连接。
注意前提是你已经下载好了Maven和JDK合适的版本
2.1、补充下载Maven
①、下载 Maven
-
选 Binary zip(例如
apache-maven-3.9.11-bin.zip)→ 解压到 无中文无空格 路径,比如"E:\java\maven\apache-maven-3.9.11-bin\apache-maven-3.9.11"
② 、配环境变量
-
Win + S 搜索 “环境变量” → 打开 “编辑系统环境变量”
-
新建系统变量变量名:
MAVEN_HOME变量值:E:\java\maven\apache-maven-3.9.11-bin\apache-maven-3.9.11 -
选中 Path → 编辑 → 新建 → 把下面两行依次加进去
%MAVEN_HOME%\bin
-
全部确认 → 重启 PowerShell
③、 验证
新开 PowerShell 输入:
mvn -v
# 得到类似效果即正确安装配置
Apache Maven 3.9.11 (3e54c93a704957b63ee3494413a2b544fd3d825b)
Maven home: E:\java\maven\apache-maven-3.9.11-bin\apache-maven-3.9.11
Java version: 24.0.1, vendor: Oracle Corporation, runtime: E:\java\JDK
Default locale: zh_CN, platform encoding: UTF-8
OS name: "windows 11", version: "10.0", arch: "amd64", family: "windows"④、实操演示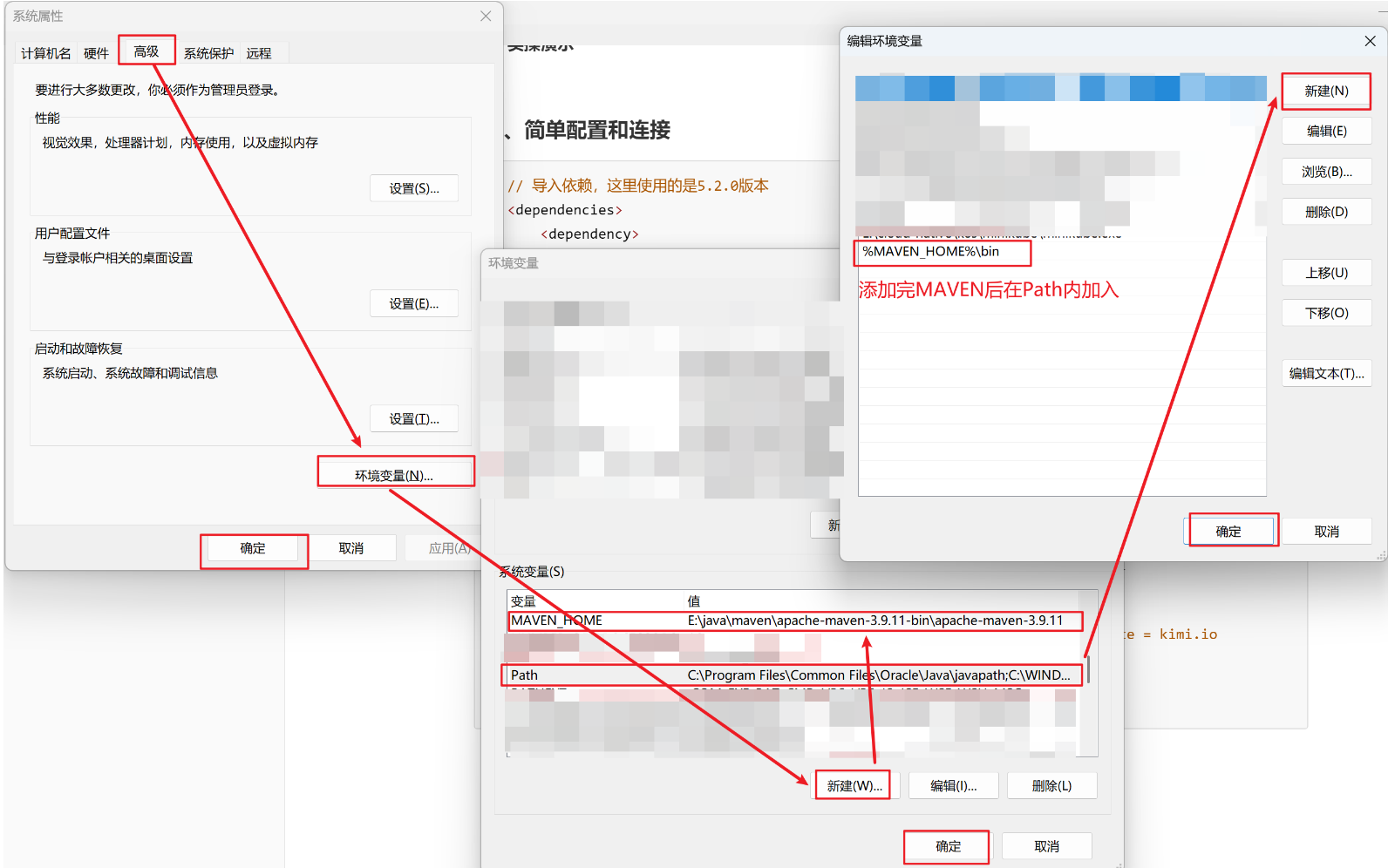
2.2、非池化直连测试(Jedis为例)
①、创建 Maven 工程
注意选择Java项目中的普通maven工程即可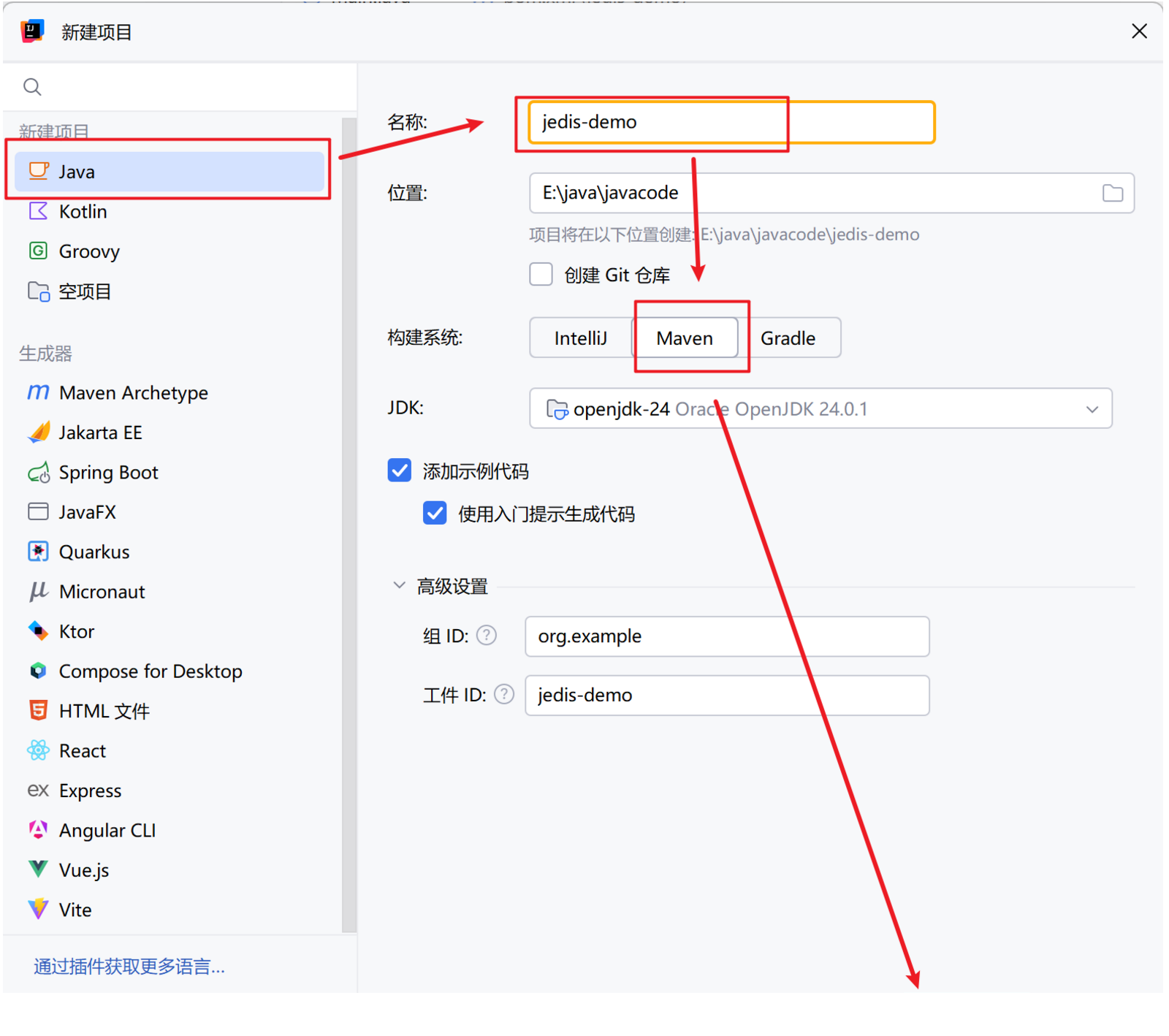
②、导入核心依赖
// 导入依赖,这里使用的是5.2.0版本
<dependencies>
<dependency>
<groupId>redis.clients</groupId>
<artifactId>jedis</artifactId>
<version>5.2.0</version>
</dependency>
</dependencies>③、非池化连接测试
package org.example;
// 导入 Jedis 类
import redis.clients.jedis.Jedis;
public class Main {
public static void main(String[] args) {
// 简单连接 Redis 服务器
Jedis jedis = new Jedis("localhost", 6379);
// 认证,设置的密码
jedis.auth("123456");
// 选择数据库
jedis.select(0);
// 插入一个键值对进行测试
jedis.set("name", "tb_first");
System.out.println("name = " + jedis.get("name")); // name = tb_first
}
// 提供一个释放连接的方法
public static void close(Jedis jedis) {
if (jedis != null) {
jedis.close();
}
}
}④、实操演示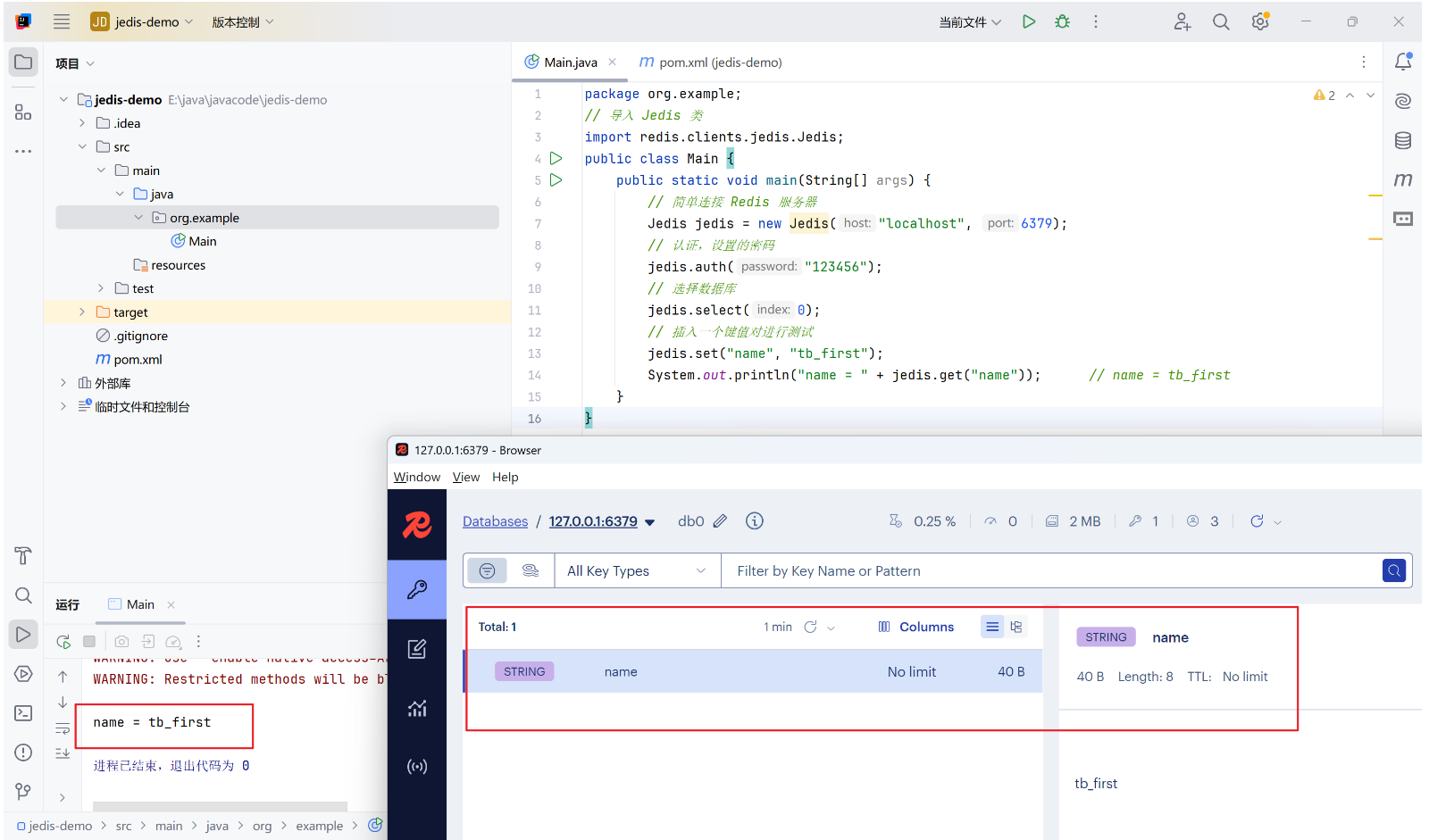
2.3、Jedis连接池连接(Jedis为例)
Jedis 连接池是生产环境中使用 Redis 的必备组件,它能有效管理连接资源,提升性能。由于Jedis的线程不安全,频繁的销毁和创建还容易导致性能的损耗,故使用连接池比非池化直连更高效。
①、连接池常见参数
| 参数名 | 说明 | 生产环境推荐值 |
|---|---|---|
maxTotal | 连接池最大连接数 | 根据QPS调整(100-500) |
maxIdle | 最大空闲连接数 | maxTotal的1/4-1/2 |
minIdle | 最小空闲连接数(保持可用连接) | 5-20 |
maxWaitMillis | 获取连接最大等待时间(ms) | 2000-5000 |
testOnBorrow | 获取连接时是否测试有效性(true会降低性能但保证连接可用) | 根据业务需求(true/false) |
testWhileIdle | 空闲时是否测试连接有效性 | true |
timeBetweenEvictionRuns | 空闲连接检测周期(ms) | 30000 |
numTestsPerEvictionRun | 每次检测的空闲连接数 | 建议等于maxIdle |
②、实操演示
// 新建类中
package org.example;
import redis.clients.jedis.Jedis;
import redis.clients.jedis.JedisPool;
import redis.clients.jedis.JedisPoolConfig;
// 创建一个连接池工具类
public class RedisConnectionPool {
// 创建一个连接池对象
private static JedisPool jedisPool;
static {
// 1. 创建连接池配置
JedisPoolConfig poolConfig = new JedisPoolConfig();
// 关键参数配置
poolConfig.setMaxTotal(8); // 最大连接数
poolConfig.setMaxIdle(4); // 最大空闲连接
poolConfig.setMinIdle(2); // 最小空闲连接
poolConfig.setTestOnBorrow(true); // 获取连接时测试连通性
poolConfig.setTestWhileIdle(true); // 空闲时定期测试连接
// 2. 创建连接池 (根据实际情况选择构造方法)
jedisPool = new JedisPool(
poolConfig,
"localhost", // Redis服务器地址
6379, // Redis端口
2000, // 连接超时时间(ms)
"123456" // 密码(没有则省略)
);
}
// 提供一个获取连接的方法
public static Jedis getResource() {
return jedisPool.getResource();
}
}
// 测试类中
package org.example;
// 导入 Jedis 类
import redis.clients.jedis.Jedis;
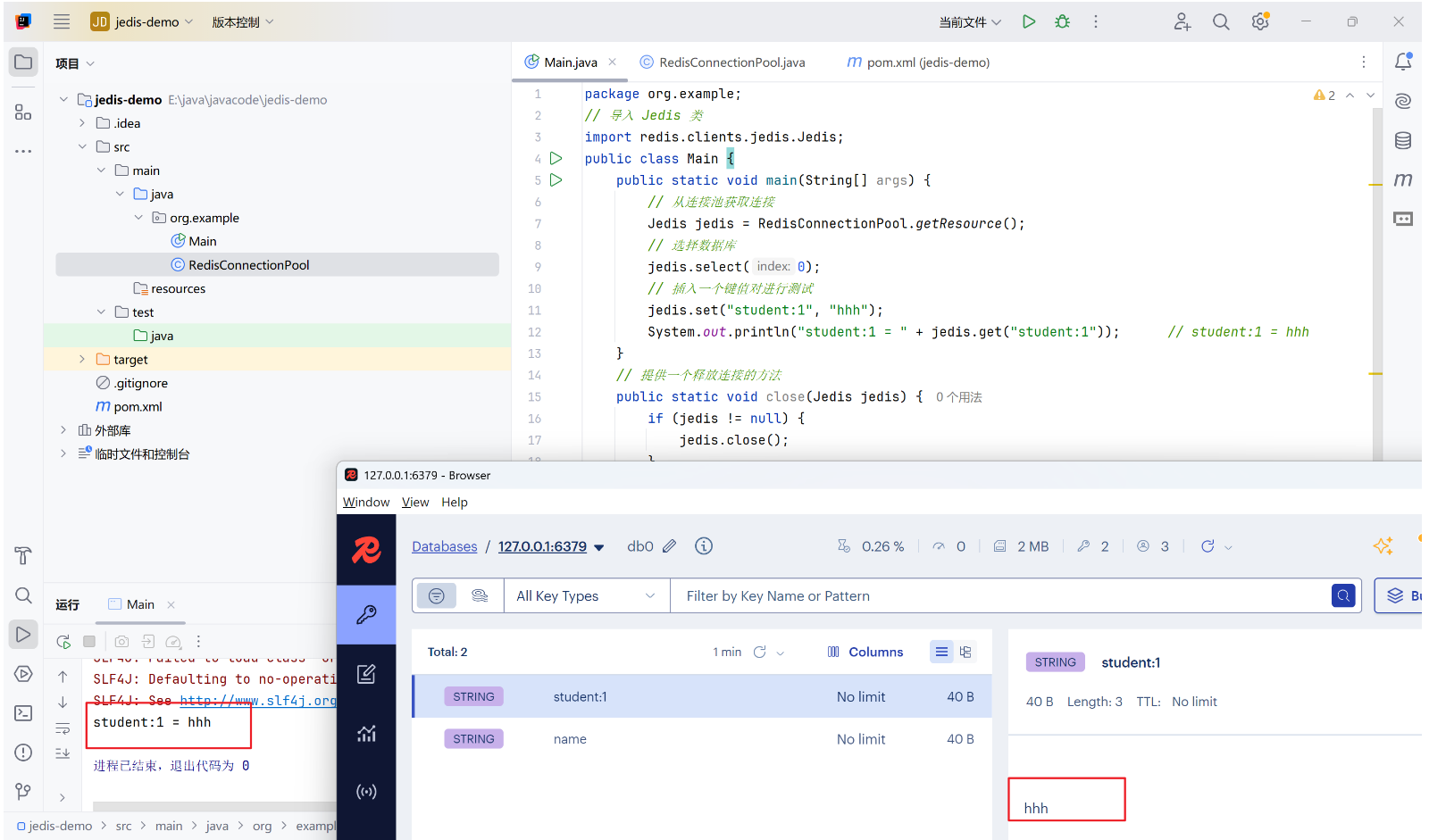
public class Main {
public static void main(String[] args) {
// 从连接池获取连接
Jedis jedis = RedisConnectionPool.getResource();
// 选择数据库
jedis.select(0);
// 插入一个键值对进行测试
jedis.set("student:1", "hhh");
System.out.println("student:1 = " + jedis.get("student:1")); // student:1 = hhh
}
// 提供一个释放连接的方法
public static void close(Jedis jedis) {
if (jedis != null) {
jedis.close();
}
}
}
2.4、SpringDataRedis
Spring Data Redis 是 Spring 生态中用于访问 Redis 的抽象框架,它提供了统一的操作接口,支持多种 Redis 客户端(Lettuce、Jedis等)。
①、创建Maven工程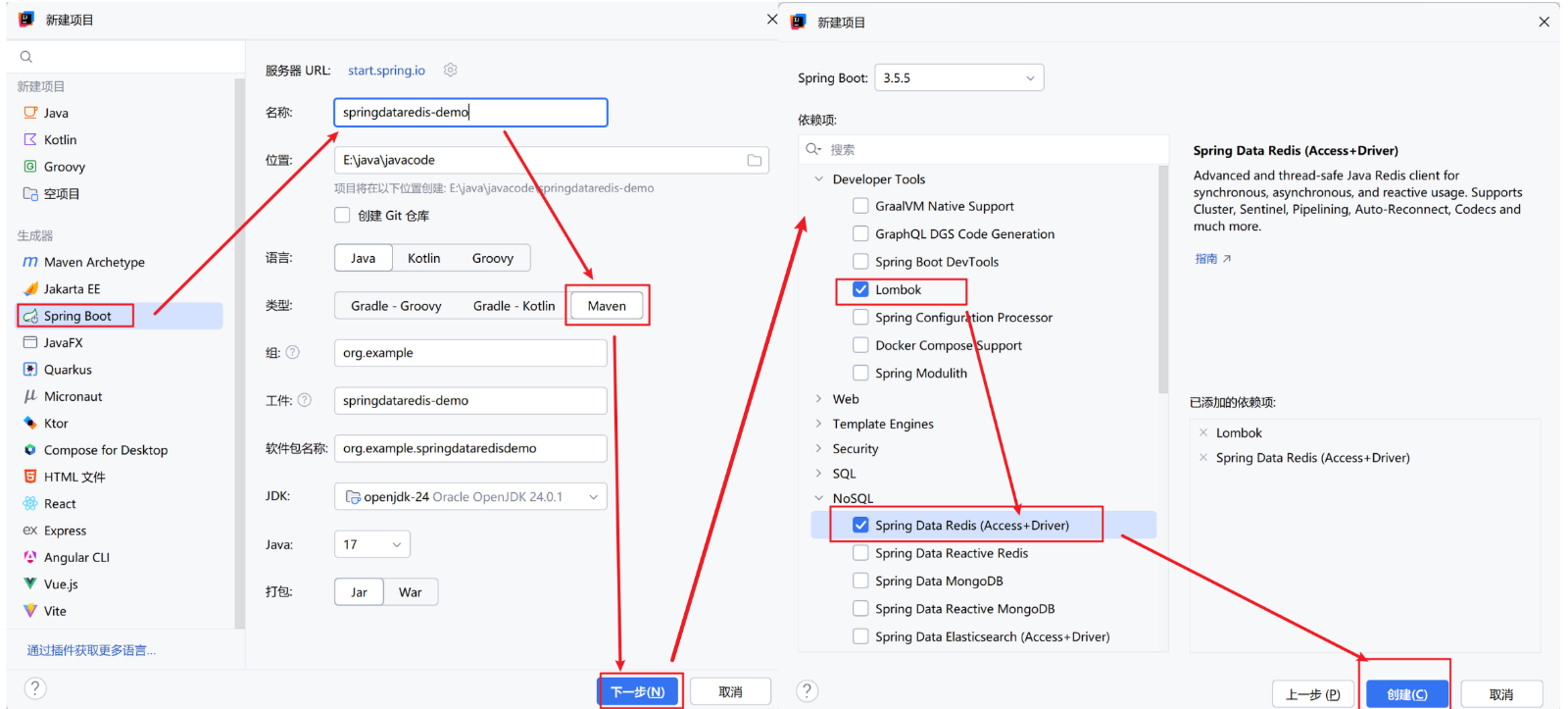
创建完成后,可选择删除多余文件,最终保留文件.idea、src、pom.xml,application可改为yaml文件
②、添加依赖
<dependencies>
<!-- 引入redis依赖 -->
<!-- 该依赖创建好工程自动含有 -->
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-data-redis</artifactId>
</dependency>
<!-- 引入连接池依赖 -->
<!-- 该依赖需要我们自己手动加入 -->
<dependency>
<groupId>org.apache.commons</groupId>
<artifactId>commons-pool2</artifactId>
</dependency>
<!-- 添加 Jackson Databind 依赖 -->
<!--Spring Boot 3.5.5 默认使用 Jackson 2.17+,所以不需要指定版本号,Spring Boot 会自动管理-->
<!-- 方便后续将Value进行JSON序列化 -->
<dependency>
<groupId>com.fasterxml.jackson.core</groupId>
<artifactId>jackson-databind</artifactId>
</dependency>
<dependency>
<groupId>org.projectlombok</groupId>
<artifactId>lombok</artifactId>
<optional>true</optional>
</dependency>
<dependency>
<groupId>org.springframework.boot</groupId>
<artifactId>spring-boot-starter-test</artifactId>
<scope>test</scope>
</dependency>
</dependencies>③、配置文件
注意较新版本Java已经废止 spring:redis ,改为 spring:data:redis
# 注意以下只是给出一个模板,具体情况具体分析
spring:
data:
redis:
# host: 127.0.0.1
host: localhost
port: 6379
password: 123456
database: 0
lettuce:
pool:
max-active: 8 # 最大连接数
max-idle: 4 # 最大空闲连接
min-idle: 2 # 最小空闲连接
max-wait: 2000ms # 获取连接最大等待时间
timeout: 1000ms # 连接超时时间④、注入redisTemplate并测试
package org.example.springdataredisdemo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringdataredisDemoApplicationTests {
@Autowired
private RedisTemplate redisTemplate;
@Test
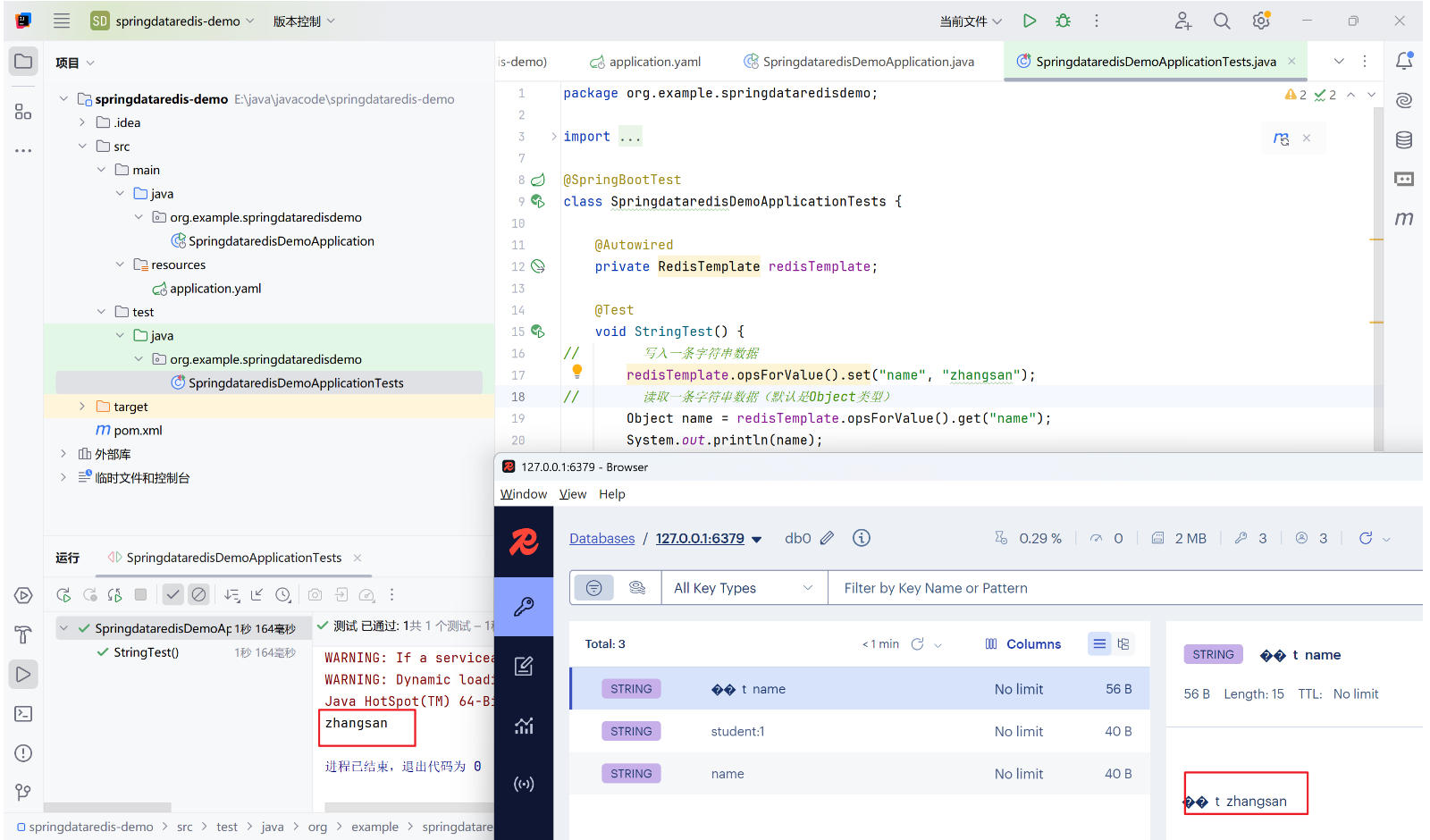
void StringTest() {
// 写入一条字符串数据
redisTemplate.opsForValue().set("name", "zhangsan");
// 读取一条字符串数据(默认是Object类型)
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}
}
⑤、Java 默认序列化
如上图,我们已经成功插入了一个name为zhangsan的键值对,同时看上图可见我们插入的zhangsan的key有部分乱码,按道理来说使用命令行查看应该也是可以取得结果,可事实是我们得到的是key 序列化后的二进制乱码以及nil(二进制序列化和JDK序列化),如图:
我们用的是默认的 RedisTemplate<Object, Object>,它默认使用:
-
JdkSerializationRedisSerializer对 key 和 value 进行序列化。 -
所以写入 Redis 的 key 是二进制格式,不是纯字符串 "name"
即 SpringDataRedis 可帮助我们将任何类型对象转化成redis可识别的字节
Ⅰ、各数据类型默认序列化器
| 操作类型 | 默认序列化器 | 存储示例 |
|---|---|---|
| Key | JdkSerializationRedisSerializer | \xac\xed\x00\x05t\x00\x03foo |
| Value | JdkSerializationRedisSerializer | 二进制Java序列化格式 |
| Hash Key | JdkSerializationRedisSerializer | 同Key |
| Hash Value | JdkSerializationRedisSerializer | 同Value |
| 所有ZSet/TX/管道操作 | JdkSerializationRedisSerializer | 二进制格式 |
Ⅱ、常用redis序列化策略
| 序列化器 | 优点 | 缺点 | 适用场景 |
|---|---|---|---|
| JdkSerializationRedisSerializer | Java原生支持 | 兼容性差、体积大、可读性差 | 不推荐使用 |
| StringRedisSerializer | 简单字符串、高效 | 只能处理String类型 | Key序列化、简单Value |
| Jackson2JsonRedisSerializer | 可读性好、跨语言 | 需要类有无参构造、反射开销 | 复杂对象存储 |
| GenericJackson2JsonRedisSerializer | 存储类信息、支持多类型 | 占用稍多空间 | 需要类型转换的场景 |
| OxmSerializer | XML格式、可读 | 效率低、体积大 | 需要XML格式的场景 |
Ⅲ、主要问题
-
可读性差:Redis CLI中无法直接识别
-
兼容性问题:不同JVM版本可能不兼容
-
存储膨胀:二进制格式比文本格式占用更多空间
-
跨语言障碍:其他语言无法直接读取
Ⅳ、解决方案RedisSerializer
自定义RedisTemplate序列化方式
// 创建RedisConfig类
package org.example.springdataredisdemo.redis.config;
import org.springframework.context.annotation.Bean;
import org.springframework.context.annotation.Configuration;
import org.springframework.data.redis.connection.RedisConnectionFactory;
import org.springframework.data.redis.core.RedisTemplate;
import org.springframework.data.redis.serializer.GenericJackson2JsonRedisSerializer;
import org.springframework.data.redis.serializer.StringRedisSerializer;
// 标记这是一个 Spring 配置类,会被 Spring 扫描并加载
@Configuration
public class RedisConfig {
// 注册一个名为 redisTemplate 的 Bean,类型是 RedisTemplate<String, Object>
@Bean
public RedisTemplate<String, Object> redisTemplate(RedisConnectionFactory factory) {
// 创建一个 RedisTemplate 实例 template
RedisTemplate<String, Object> template = new RedisTemplate<>();
// 把连接工厂注入进来,建立与 Redis 的连接
template.setConnectionFactory(factory);
// 使用 String 序列化 Key
template.setKeySerializer(new StringRedisSerializer());
// 使用 JSON 序列化 Value
template.setValueSerializer(new GenericJackson2JsonRedisSerializer());
// Hash结构也使用 String 序列化 HashKey,JSON 序列化 HashValue
template.setHashKeySerializer(new StringRedisSerializer());
template.setHashValueSerializer(new GenericJackson2JsonRedisSerializer());
return template;
}
}
// 在main文件中重新测试
package org.example.springdataredisdemo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringdataredisDemoApplicationTests {
@Autowired
private RedisTemplate<String, Object> redisTemplate;
@Test
void StringTest() {
// 写入一条字符串数据
redisTemplate.opsForValue().set("name", "zhangsan");
// 读取一条字符串数据(默认是Object类型)
Object name = redisTemplate.opsForValue().get("name");
System.out.println(name);
}
}结果如图: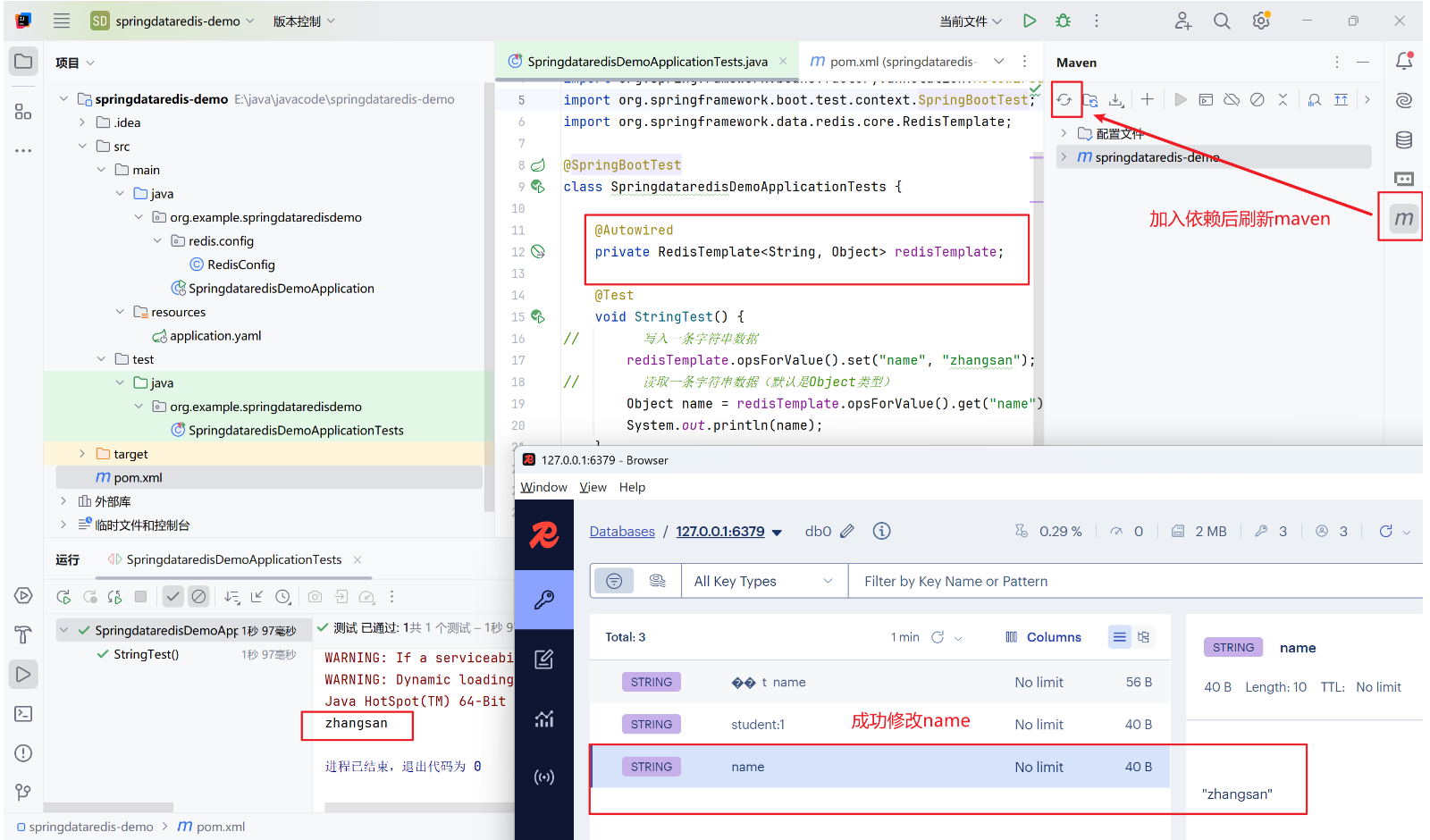
Ⅴ、可选优化
由于上方Ⅲ给出的解决方案自动化JSON会带来内存占用问题,所以我们可以选择只进行String序列化,但这也要求我们存入的 key 和 value 必须是字符串类型,而如果需要存入JSON格式的对象,则需要我们自己手动完成对象的序列化,如使用ObjectMapper等等工具。
package org.example.springdataredisdemo;
import org.junit.jupiter.api.Test;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.boot.test.context.SpringBootTest;
import org.springframework.data.redis.core.RedisTemplate;
@SpringBootTest
class SpringdataredisDemoApplicationTests {
@Autowired
private StringRedisTemplate stringRedisTemplate;
@Test
void StringTest() {
// 写入一条字符串数据
stringRedisTemplate.opsForValue().set("name", "zhangsan");
// 读取一条字符串数据(默认是Object类型)
String name = stringRedisTemplate.opsForValue().get("name");
System.out.println(name);
}
@Test
void test() throws JsonProcessingException {
User user = new User("张三", 20);
// 手动序列化
String json = objectMapper.writeValueAsString(user);
redisTemplate.opsForValue().set("user:1", json);
// 手动反序列化
String jsonBack = redisTemplate.opsForValue().get("user:1");
User userBack = objectMapper.readValue(jsonBack, User.class);
System.out.println(userBack.getName()); // 张三
}
















&spm=1001.2101.3001.5002&articleId=151290184&d=1&t=3&u=881ee6c33367467c85eb71a2dd655c5e)
 1513
1513

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









