




今天继续完成k8s的集群搭建,没看上一篇的建议看看上一篇,有超详细的搭建思路哦~
创建多节点集群
1、编写kind文件
①注意事项:
-
配置文件的编写工具:任何文本编辑器编写均可,eg、Notepad、Vs Code等等
-
使用记事本编写,默认保存为 UTF-8 with BOM,可能导致 Kind 无法识别,只需要在保存文件的时候选择“另存为” → 编码选择
UTF-8
-
-
文件保存格式:必须是 YAML 格式(后缀为
.yaml或.yml) -
配置文件保存位置:任意目录均可(当然你要记得住呀,待会利用配置文件创建集群的时候要用得着哦~)
②编写文件并保存
-
【基础配置,只为搭建最简单的集群】在你的配置文件中写入:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane # Master 节点
- role: worker # Worker 节点 1
- role: worker # Worker 节点 2
-
【高级配置,应对你有特别需求】如我需要指定版本或暴露 Master 节点的端口等等
在你的配置文件中写入:
kind: Cluster
apiVersion: kind.x-k8s.io/v1alpha4
nodes:
- role: control-plane # Master 节点
extraPortMappings:
- containerPort: 6443
hostPort: 36443 # 宿主机端口,之后可以通过localhost:36443访问API Server
protocol: TCP
image: kindest/node:v1.27.3 # 指定版本
- role: worker # Worker 节点 1
image: kindest/node:v1.27.3 # 指定版本
- role: worker # Worker 节点 2
image: kindest/node:v1.27.3 # 指定版本
注意:Kind 对节点角色有严格的命名规范,不能自定义名称,也就是说你的配置文件中的角色名称不可 以自定义!!!
Kind 目前不支持动态扩容,如果要增加新的节点,需删除,然后修改你的配置文件并重建集群
之后如下图保存在你的任意目录中
2、使用配置文件创建集群
本步创建集群有两种方法,一种是使用绝对路径创建,一种是相对路径创建
Ⅰ、绝对路径
# 先进入你的Ubuntu或者是其他发行版
wsl -d Ubuntu
# 使用配置文件创建集群
kind create cluster --name my-multi-node-cluster1 --config "/mnt/e/cloud-native/k8s/kindconfigfile1.yaml"
Ⅱ、相对路径
# 先进入你的Ubuntu或者是其他发行版
wsl -d Ubuntu
# 先移到你的配置文件所在目录
cd /mnt/e/cloud-native/k8s/
# 使用配置文件创建集群
kind create cluster --name my-multi-node-cluster1 --config kindconfigfile1.yaml
--name :指的是你创建的多节点集群的名字,可自定义
--config :指的是你刚刚编辑的kind配置文件,后面要加入对应的路径(注意最好是使用Linux路径格式)
可能问题:Docker 无法从镜像仓库拉取 kindest/node:v1.29.2 镜像,这百分之八九十就是因为我们是在国内导致的网络问题,我们只要给我们的wsl2中的docker配置镜像源加速即可(你也可以将你Windows本地的docker中的镜像源复制加到Ubuntu中的docker),以下我提供一个简单的解决方法:
# 首先确认 Docker 服务正在运行
# 如果没启动报错就重启一下docker restart
docker ps
# 编辑 Docker 配置文件,一般在/etc/docker/daemon.json(若不存在则新建)
# 配置镜像源,加速下载,但可能仍下载比较慢,但还是可以下下来的
sudo tee /etc/docker/daemon.json <<EOF
{
"registry-mirrors": [
"https://docker.mirrors.ustc.edu.cn",
"https://registry-1.docker.io"
],
"insecure-registries": []
}
EOF
# 重启docker使修改生效
sudo systemctl restart docker
如果还是拉取失败,看看你有没有关闭 VPN 或代理工具,这些也可能有影响
拉取成功,集群创建成功可以得到类似如图提示:
3、验证节点状态
输入以下代码验证:
kubectl get nodes
你将会看到类似画面:

显示了 1 个 Master(control-plane)和 2 个 Worker 节点
可能问题:STATUS显示NOTREADY,这一般是多台虚拟机通过minikube或其他工具搭建集群容易遇到的问题,即网络问题,你可能需要配置部署一下CNI网络的一些插件,这也恰恰体现了kind的优势
4、查看主节点的核心组件
输入以下代码查看Pod:
# 记住要指定你要查看的Pod的指定的命名空间
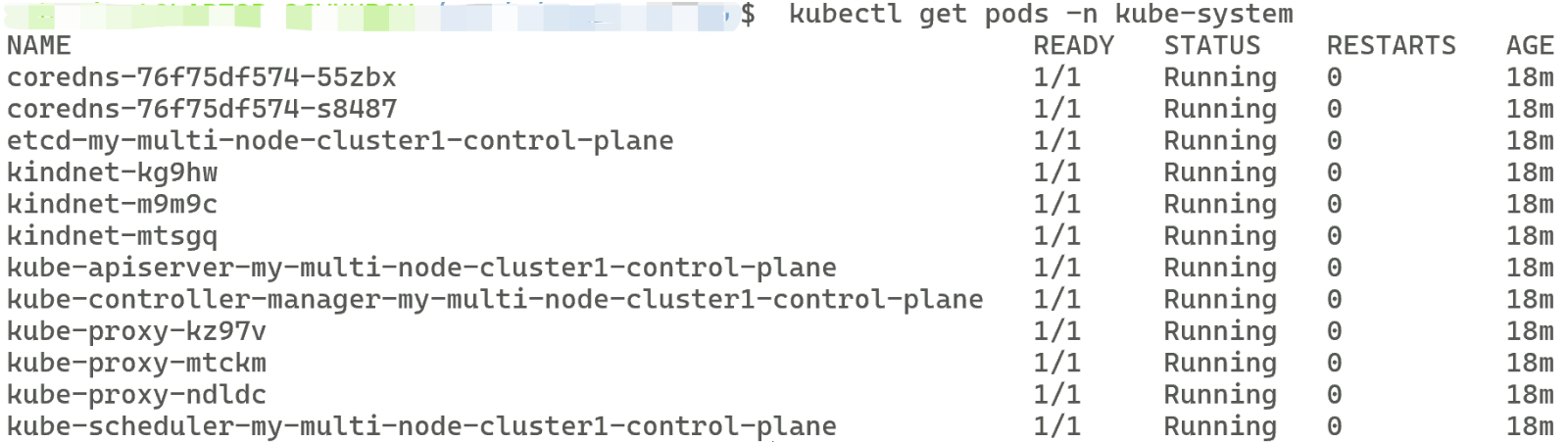
kubectl get pods -n kube-system
如果正确搭建完成,可以看见如下输出:
5、kubectl核心基础命令
①常见资源类型
-
Pods----po(别名)
-
deployments----deploy(别名)
-
services----svc(别名)
-
namespace----ns(别名)
-
nodes----no(别名)
②、Pod操作
-
创建Pod:kubectl create -f pod.yaml
-
获取 Pod 列表:kubectl get pods
-
删除 Pod:kubectl delete pod <pod-name>
-
进入 Pod 的容器:kubectl exec -it <pod-name> -- /bin/sh
③、 Deployment 操作
-
创建 Deployment:kubectl create -f deployment.yaml
-
获取 Deployment 列表:kubectl get deployments
-
更新 Deployment:kubectl set image deployment/<deployment-name> <container-name>=<new-image>
-
删除 Deployment:kubectl delete deployment <deployment-name>
④. Service 操作
-
创建 Service:kubectl create -f service.yaml
-
获取 Service 列表:kubectl get services
-
删除 Service:kubectl delete service <service-name>
⑤. Namespace 操作
-
创建 Namespace:kubectl create namespace <namespace-name>
-
获取 Namespace 列表:kubectl get namespaces
-
删除 Namespace:kubectl delete namespace <namespace-name>
更多常见操作参考官方文档哈~
6、多节点使用kubectl【可选】
不建议在 Kubernetes Worker 节点上安装和使用
kubectl,安全风险高、维护复杂化、资源浪费,但如果你想,觉得方便也可以但是我更建议仅在 Control Plane 或外部机器使用
kubectl
①、进入你要安装kubectl的容器
②、在 容器内安装 kubectl
③、复制主节点的 kubeconfig 到容器
整体下来如下:
docker exec -it <worker容器名称> /bin/bash
# 下载 kubectl(使用国内镜像加速)
curl -LO https://dl.k8s.io/release/$(curl -L -s https://dl.k8s.io/release/stable.txt)/bin/linux/amd64/kubectl
# 安装到可执行路径
chmod +x kubectl
mv kubectl /usr/local/bin/
# 验证安装
kubectl version --client
# 查看主节点的 kubeconfig
cat /etc/kubernetes/admin.conf
# 复制主节点的 kubeconfig
scp /etc/kubernetes/admin.conf
# 创建 .kube 目录
mkdir -p ~/.kube
# 粘贴内容到配置文件
cat > ~/.kube/config <<EOF
<paste kubeconfig content here>
EOF
# 设置权限
chmod 600 ~/.kube/config

















 3994
3994

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









