



WebRTC中的NoiseSuppressor类是实现实时音频噪声抑制的核心模块。它采用基于维纳滤波的频域处理算法,通过分析-处理两阶段工作流程:分析阶段进行噪声估计、语音概率检测和SNR计算,构建噪声模型;处理阶段应用自适应滤波器在频域抑制噪声,并通过重叠相加恢复时域信号。该模块支持多通道处理,采用保守的抑制策略确保噪声充分消除,同时通过零帧检测防止无声段影响噪声统计。其智能内存管理和频域时域结合的设计,在保持语音质量的前提下有效抑制背景噪声,显著提升实时音视频通信的听觉体验。
1. 核心功能
NoiseSuppressor 是 WebRTC 中的噪声抑制模块,主要功能:
-
实时音频噪声抑制
-
多通道音频处理
-
频域噪声估计和抑制
-
语音概率估计
-
自适应滤波器设计
2. 核心算法原理
2.1 维纳滤波算法
数学公式:
H(ω) = P_s(ω) / [P_s(ω) + P_n(ω)]
其中:
-
H(ω)是维纳滤波器频域响应 -
P_s(ω)是语音功率谱 -
P_n(ω)是噪声功率谱
// 计算先验和后验SNR
void ComputeSnr(rtc::ArrayView<const float, kFftSizeBy2Plus1> filter,
rtc::ArrayView<const float> prev_signal_spectrum,
rtc::ArrayView<const float> signal_spectrum,
rtc::ArrayView<const float> prev_noise_spectrum,
rtc::ArrayView<const float> noise_spectrum,
rtc::ArrayView<float> prior_snr,
rtc::ArrayView<float> post_snr) {
for (size_t i = 0; i < kFftSizeBy2Plus1; ++i) {
// 先前帧的后验SNR估计,基于前一帧的增益滤波器
float prev_estimate = prev_signal_spectrum[i] /
(prev_noise_spectrum[i] + 0.0001f) * filter[i];
// 当前后验SNR计算
if (signal_spectrum[i] > noise_spectrum[i]) {
post_snr[i] = signal_spectrum[i] / (noise_spectrum[i] + 0.0001f) - 1.f;
} else {
post_snr[i] = 0.f; // 避免负值
}
// 基于决策导向的先验SNR估计,结合当前和先前估计
prior_snr[i] = 0.98f * prev_estimate + (1.f - 0.98f) * post_snr[i];
}
}
2.2 语音概率估计
// 更新语音概率估计
ch_p->speech_probability_estimator.Update(
num_analyzed_frames_, prior_snr, post_snr,
ch_p->noise_estimator.get_conservative_noise_spectrum(),
signal_spectrum, signal_spectral_sum, signal_energy);
2.3 噪声估计
// 噪声估计器预处理
ch_p->noise_estimator.PreUpdate(num_analyzed_frames_, signal_spectrum,
signal_spectral_sum);
// 噪声估计器后处理,基于语音概率更新噪声谱
ch_p->noise_estimator.PostUpdate(
ch_p->speech_probability_estimator.get_probability(), signal_spectrum);
3. 关键数据结构
3.1 ChannelState - 通道状态
struct ChannelState {
ChannelState(const SuppressionParams& suppression_params, size_t num_bands);
SpeechProbabilityEstimator speech_probability_estimator; // 语音概率估计器
WienerFilter wiener_filter; // 维纳滤波器
NoiseEstimator noise_estimator; // 噪声估计器
std::array<float, kFftSizeBy2Plus1> prev_analysis_signal_spectrum; // 先前分析信号频谱
std::array<float, kFftSize - kNsFrameSize> analyze_analysis_memory; // 分析内存
std::array<float, kOverlapSize> process_analysis_memory; // 处理分析内存
std::array<float, kOverlapSize> process_synthesis_memory; // 处理合成内存
std::vector<std::array<float, kOverlapSize>> process_delay_memory; // 延迟内存
};
3.2 FilterBankState - 滤波器组状态
struct FilterBankState {
std::array<float, kFftSize> real; // FFT实部
std::array<float, kFftSize> imag; // FFT虚部
std::array<float, kFftSize> extended_frame; // 扩展帧
};
4. 核心方法详解
4.1 Analyze - 分析阶段
void NoiseSuppressor::Analyze(const AudioBuffer& audio) {
// 准备噪声估计器进行分析阶段
for (size_t ch = 0; ch < num_channels_; ++ch) {
channels_[ch]->noise_estimator.PrepareAnalysis();
}
// 零帧检测:避免在无声时更新统计信息
bool zero_frame = true;
for (size_t ch = 0; ch < num_channels_; ++ch) {
rtc::ArrayView<const float, kNsFrameSize> y_band0(
&audio.split_bands_const(ch)[0][0], kNsFrameSize);
float energy = ComputeEnergyOfExtendedFrame(
y_band0, channels_[ch]->analyze_analysis_memory);
if (energy > 0.f) {
zero_frame = false;
break;
}
}
if (zero_frame) return; // 跳过零帧处理
// 分析计数器更新
if (++num_analyzed_frames_ < 0) {
num_analyzed_frames_ = 0;
}
// 多通道分析处理
for (size_t ch = 0; ch < num_channels_; ++ch) {
// 形成扩展帧并应用滤波器组窗
std::array<float, kFftSize> extended_frame;
FormExtendedFrame(y_band0, ch_p->analyze_analysis_memory, extended_frame);
ApplyFilterBankWindow(extended_frame);
// FFT变换和幅度谱计算
std::array<float, kFftSize> real;
std::array<float, kFftSize> imag;
fft_.Fft(extended_frame, real, imag);
std::array<float, kFftSizeBy2Plus1> signal_spectrum;
ComputeMagnitudeSpectrum(real, imag, signal_spectrum);
// 噪声和语音概率估计
ch_p->noise_estimator.PreUpdate(num_analyzed_frames_, signal_spectrum,
signal_spectral_sum);
// SNR计算和语音概率更新
ComputeSnr(ch_p->wiener_filter.get_filter(),
ch_p->prev_analysis_signal_spectrum, signal_spectrum,
ch_p->noise_estimator.get_prev_noise_spectrum(),
ch_p->noise_estimator.get_noise_spectrum(), prior_snr, post_snr);
ch_p->noise_estimator.PostUpdate(
ch_p->speech_probability_estimator.get_probability(), signal_spectrum);
// 存储当前幅度谱供处理阶段使用
std::copy(signal_spectrum.begin(), signal_spectrum.end(),
ch_p->prev_analysis_signal_spectrum.begin());
}
}
4.2 Process - 处理阶段
void NoiseSuppressor::Process(AudioBuffer* audio) {
// 内存分配策略:小通道数用栈,大通道数用堆
std::array<FilterBankState, kMaxNumChannelsOnStack> filter_bank_states_stack;
// ... 其他栈数组
if (NumChannelsOnHeap(num_channels_) > 0) {
// 使用堆内存
filter_bank_states = rtc::ArrayView<FilterBankState>(
filter_bank_states_heap_.data(), num_channels_);
// ... 其他堆数组
}
// 计算所有通道的抑制滤波器
for (size_t ch = 0; ch < num_channels_; ++ch) {
// 扩展帧形成和窗函数应用
FormExtendedFrame(y_band0, channels_[ch]->process_analysis_memory,
filter_bank_states[ch].extended_frame);
ApplyFilterBankWindow(filter_bank_states[ch].extended_frame);
// FFT分析和幅度谱计算
fft_.Fft(filter_bank_states[ch].extended_frame,
filter_bank_states[ch].real, filter_bank_states[ch].imag);
// 维纳滤波器更新
channels_[ch]->wiener_filter.Update(
num_analyzed_frames_,
channels_[ch]->noise_estimator.get_noise_spectrum(),
channels_[ch]->noise_estimator.get_prev_noise_spectrum(),
channels_[ch]->noise_estimator.get_parametric_noise_spectrum(),
signal_spectrum);
// 高频带增益计算(多频带情况)
if (num_bands_ > 1) {
upper_band_gains[ch] = ComputeUpperBandsGain(
suppression_params_.minimum_attenuating_gain,
channels_[ch]->wiener_filter.get_filter(),
channels_[ch]->speech_probability_estimator.get_probability(),
channels_[ch]->prev_analysis_signal_spectrum, signal_spectrum);
}
}
// 聚合多通道维纳滤波器(取最小值策略)
std::array<float, kFftSizeBy2Plus1> filter_data;
if (num_channels_ == 1) {
filter = channels_[0]->wiener_filter.get_filter();
} else {
AggregateWienerFilters(filter_data); // 多通道时取各通道滤波器的最小值
}
// 应用滤波器到频域数据
for (size_t ch = 0; ch < num_channels_; ++ch) {
for (size_t i = 0; i < kFftSizeBy2Plus1; ++i) {
filter_bank_states[ch].real[i] *= filter[i];
filter_bank_states[ch].imag[i] *= filter[i];
}
}
// IFFT合成回时域
for (size_t ch = 0; ch < num_channels_; ++ch) {
fft_.Ifft(filter_bank_states[ch].real, filter_bank_states[ch].imag,
filter_bank_states[ch].extended_frame);
}
// 重叠相加输出
for (size_t ch = 0; ch < num_channels_; ++ch) {
OverlapAndAdd(filter_bank_states[ch].extended_frame,
channels_[ch]->process_synthesis_memory, y_band0);
}
// 高频带处理(对齐延迟和增益应用)
if (num_bands_ > 1) {
// 选择最小高频增益
float upper_band_gain = upper_band_gains[0];
for (size_t ch = 1; ch < num_channels_; ++ch) {
upper_band_gain = std::min(upper_band_gain, upper_band_gains[ch]);
}
// 高频带延迟对齐和增益应用
for (size_t ch = 0; ch < num_channels_; ++ch) {
for (size_t b = 1; b < num_bands_; ++b) {
DelaySignal(y_band, channels_[ch]->process_delay_memory[b - 1],
delayed_frame);
// 应用时域噪声衰减增益
for (size_t j = 0; j < kNsFrameSize; j++) {
y_band[j] = upper_band_gain * delayed_frame[j];
}
}
}
}
}
5. 设计亮点
5.1 内存优化策略
// 栈堆混合内存分配:小通道数用栈,大通道数用堆
constexpr size_t kMaxNumChannelsOnStack = 2;
size_t NumChannelsOnHeap(size_t num_channels) {
return num_channels > kMaxNumChannelsOnStack ? num_channels : 0;
}
5.2 多通道聚合策略
// 多通道滤波器聚合:取各通道最小值,确保保守的噪声抑制
void AggregateWienerFilters(rtc::ArrayView<float, kFftSizeBy2Plus1> filter) const {
std::copy(filter0.begin(), filter0.end(), filter.begin());
for (size_t ch = 1; ch < num_channels_; ++ch) {
for (size_t k = 0; k < kFftSizeBy2Plus1; ++k) {
filter[k] = std::min(filter[k], filter_ch[k]); // 最小值聚合
}
}
}
5.3 零帧检测机制
// 避免在无声帧更新统计信息,防止阈值漂移
if (zero_frame) {
// 在零信号情况下更新统计信息会导致阈值向零信号情况移动
// 一旦信号"开启",所有内容都将被视为语音,没有噪声抑制效果
return;
}
6. 典型工作流程
6.1 时序图
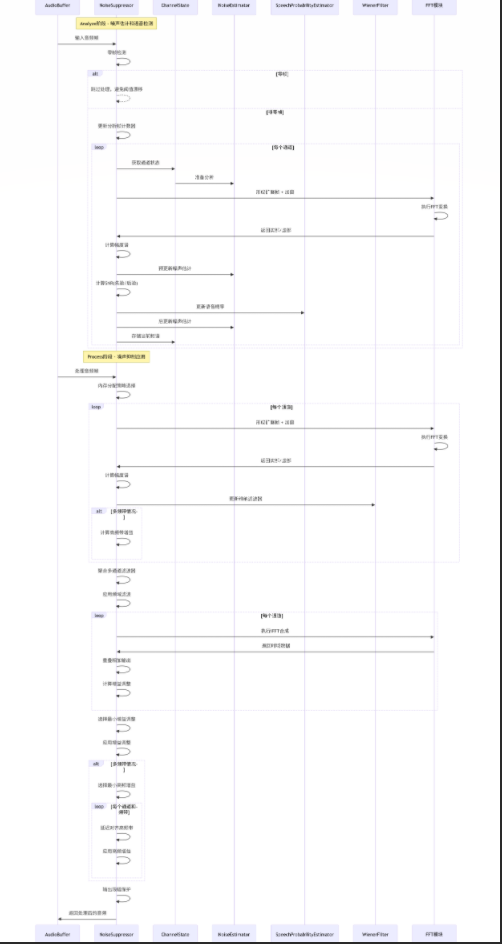
6.2 处理流程图
6.3 关键处理步骤说明
分析阶段关键点:
-
零帧检测:防止无声帧影响噪声统计,避免阈值漂移
-
决策导向SNR估计:结合当前和先前帧信息,提高估计稳定性
-
保守噪声估计:在语音概率低时更新噪声模型
处理阶段关键点:
-
多通道保守策略:取各通道滤波器最小值,确保噪声充分抑制
-
频域时域结合:低频带频域处理 + 高频带时域增益
-
延迟对齐:高频带延迟处理以匹配低频带处理延迟
-
输出保护:限制输出在有效范围内,防止溢出
这个噪声抑制器采用了经典的维纳滤波框架,结合了先进的噪声估计和语音概率检测技术,在保持语音质量的同时有效抑制背景噪声。


















 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









