






一
前言
在查询类的接口中, 如果查询的数据量过大,因为http调用的最大时长限制或者系统的内存限制, 都可能引起超时报错或内存溢出报错. 此时就需要把查询接口做分页处理
本文主要介绍使用分页查询接口同步数据的注意事项
二
SQL分页
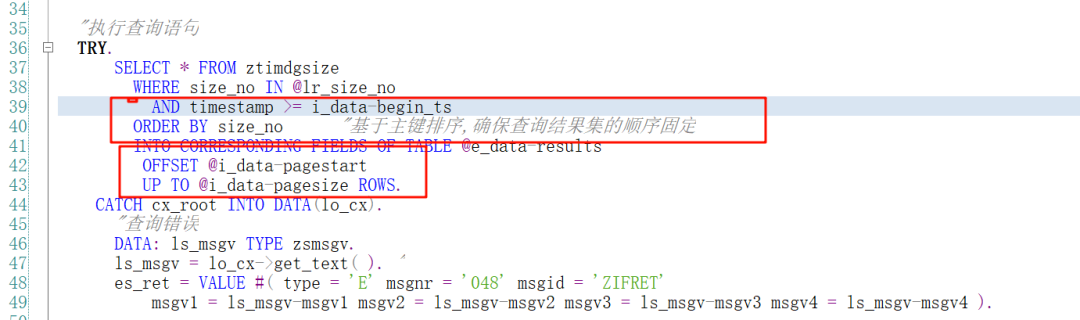
ABAP OPEN SQL新版本支持分页查询.
如下图, 可以通过 OFFSET <M>偏移量 和 UP TO <N> ROWS 两个参数实现分页查询
其中OFFSET <M> 表示跳过 M 条记录 从M + 1开始获取数据
UP TO <N> ROWS 表示获取 N 条记录
分页查询中的排序很重要. 一般情况需要按找主键排序, 以便确保结果集合稳定排序,分页查询不会导致遗漏数据
三
客户端处理方式
如果上述SQL分页查询封装成服务. 客户端调用服务时, 需要通过如下循环实现所有数据的获取
假定总数据量 25 . 每次查询记录数10
循环开始
第一次查询偏移量0 指定每包记录数10 . 返回记录数10
第二次查询偏移量0+10 指定每包记录数10 . 返回记录数10
第三次查询偏移量0+20 指定每包记录数10. 返回记录数 5
判定返回记录数5<每次查询记录数10 . 退出循环
四
遗漏数据的可能情况一
使用SQL语句的分页方式, 可能有如下数据遗漏的可能
删除数据
如果数据集合存在删除. 无论怎么优化查询,都可能导致查询的数据遗漏.
示例
数据集
主键 时间戳
1010 T10
1020 T10
1030 T10
1040 T10
1050 T10
本轮查询的每页最大记录数 2
第一次查询 偏移量 OFFSET 0 UP TO 2 ROWS, 获取数据
1010 T10
1020 T10
第一次查询后, 如果记录1020 被删除. 结果集变成
1010 T10
1030 T10
1040 T10
1050 T10
第二次查询 偏移量 OFFSET 2 UP TO 2 ROWS,获取数据
1040 T10
1050 T10
第三次查询 偏移量OFFSET 4 UP TO 2 ROWS,没有获取数据, 退出查询
可以看到,因为在两次查询间隔删除了主键1020的记录, 从而导致客户端获取的数据集和服务器的数据集不一致,客户端遗漏了不该遗漏的数据 1030 同时因为通过查询同步数据的方式无法获取删除掉的数据1020 的删除信息, 导致服务端和客户端的数据差异
服务端
1010 T10
1030 T10
1040 T10
1050 T10
客户端获取
1010 T10
1020 T10
1040 T10
1050 T10
解决方式
如果数据存在删除,通过查询语句是无法把删除信息传递到客户端系统的,因此设计系统时使用数据的标记删除取代物理删除. 可以避免情况这种麻烦.
五
遗漏数据的可能情况二
客户端限定了查询开始及结束时间戳. 服务端使用开始和结束时间戳查询数据.客户端按结束时间戳作为下次查询的开始时间戳
比如如下结果集
主键 时间戳
1010 T10
1020 T10
1030 T10
1040 T10
1050 T10
查询时间戳 >=T01 AND <= T11 . 每页最大记录数 2
第一次查询 偏移量 OFFSET 0 UP TO 2 ROWS, 获取数据
1010 T10
1020 T10
第一次查询后, 关键字 1010数据发生改变, 时间戳变成 T12
查询条件不变, 可以获取的结果集变成
1020 T10
1030 T10
1040 T10
1050 T10
第二次查询 偏移量 OFFSET 2 UP TO 2 ROWS, 获取数据
1040T10
1050T10
第三次查询, 偏移量 OFFSET 4 UP TO 2 ROWS ,没有获取数据. 本轮查询结束
可以看出
客户端遗漏了关键字 1030 的数据. 该记录再下一轮查询中也无法获取.
对于新增记录
因为新增记录的时间戳 > 客户端限定的时间戳T11. 本轮查询无法获取新增的记录,下轮查询中客户端调整了查询时间戳范围, 可以获取
六
数据遗漏的可能情况三
客户端限定了开始时间戳,结束时间戳, 服务端仅使用时间戳>=开始时间戳查询数据, 客户端获取所有查询结果集中最大的时间戳作为下次查询的开始时间戳
比如如下结果集,
主键 时间戳
1010 T10
1020 T10
1030 T10
1040 T10
1050 T10
查询时间戳 >=T01 . 每页最大记录数 2
第一次查询 偏移量 OFFSET 0 UP TO 2 ROWS, 获取数据
1010 T10
1020 T10
第一次查询后, 关键字 1010数据发生改变, 时间戳变成 T11
客户端的查询条件不变 >=T01, 可以获取的结果集不变
1010 T11
1020 T10
1030 T10
1040 T10
1050 T10
第二次查询 偏移量 OFFSET 2 UP TO 2 ROWS, 获取数据
1030 T10
1040 T10
第二次查询后,
如果新增了记录1012 T12 ,1042 T13,使用时间戳>=T01的查询结果集变成
1010 T11
1012 T12
1020 T10
1030 T10
1040 T10
1042 T13
1050 T10
第三次查询, 偏移量 OFFSET 4 UP TO 2 ROWS ,
1040 T10
1042 T12
第四次查询, 偏移量 OFFSET 6 UP TO 2 ROWS ,
1050 T10
本轮结束后,客户端的查询结果集
1010 T10
1020 T10
1030 T10
1040 T10
1040 T10
1042 T13
1050 T10
其中新增的记录1012 T12 在本轮查询中没有获取. 修改的记录 1010 T11,客户端获取的是旧记录,新增记录 1042 T13 获取了.
客户记录时间戳采用本轮查询的最大时间戳 记录下 T13
下轮查询时, 使用 >=T13 查询. 遗漏数据
1012 T12
1010 T13
七
改进的方式
客户端限定了开始时间戳和结束时间戳.并使用结束时间戳作为下次查询的开始时间戳
服务端强制使用时间戳>=开始时间戳查询
比如如下结果集,
主键 时间戳
1010 T10
1020 T10
1030 T10
1040 T10
1050 T10
客户端 使用时间戳 T01 T11 .
查询时间戳 >=T01 . 每页最大记录数 2
第一次查询 偏移量 OFFSET 0 UP TO 2 ROWS, 获取数据
1010 T10
1020 T10
第一次查询后, 关键字 1010数据发生改变, 时间戳变成 T12
客户端的查询条件不变 >=T01, 可以获取的结果集不变
1010T12
1020T10
1030T10
1040T10
1050T10
第二次查询 偏移量 OFFSET 2 UP TO 2 ROWS, 获取数据
1030 T10
1040 T10
第二次查询后,
如果新增了记录1012 T13 ,1042 T14,查询结果集变成
1010 T12
1012 T13
1020 T10
1030 T10
1040 T10
1042 T14
1050 T10
第三次查询, 偏移量 OFFSET 4 UP TO 2 ROWS ,
1040 T10
1042 T14
第四次查询, 偏移量 OFFSET 6 UP TO 2 ROWS ,
1050 T10
本轮结束后,客户端的查询结果集
1010 T10
1020 T10
1030 T10
1040 T10
1040 T10
1042 T14
1050 T10
其中新增的记录1012 T13在本轮查询中没有获取. 新增记录 1042 T14 获取到了.
客户端记录采用本轮查询的结束时间戳 记录下 T11
下轮查询时, 使用 >=T11查询. 获取的数据,包括上轮查询未获取的数据 1012 T13 及修改的数据
1010 T12
1012 T13
1042 T14
这样确保了客户端最终的数据集等同于服务端的数据集
八
时间戳分包获取变化量的方式
在数据集不存在物理删除的情况下. 可以使用下述方式获取服务器的数据
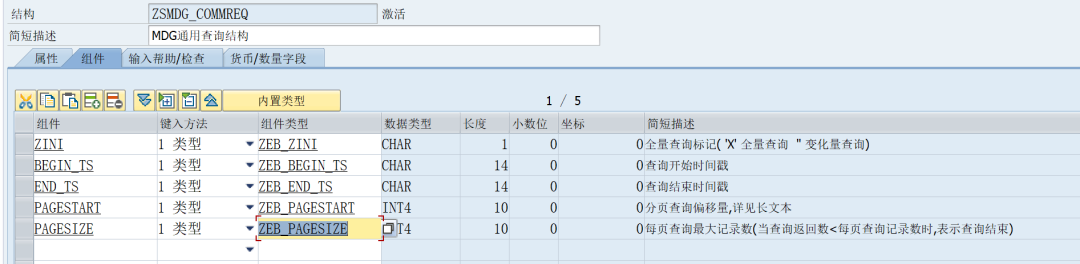
非业务查询字段的附加查询字段:
ZINI 全量查询标记( 'X' 全量查询 '' 变化量查询)
BEGIN_TS 查询开始时间戳
END_TS 查询结束时间戳
PAGESTART 分页查询偏移量,详见长文本
PAGESIZE 每页查询最大记录数(当查询返回数<每页查询记录数时,表示查询结束)
两种查询方式
01
全量查询
客户端:循环执行
传递业务查询条件,
传递查询开始时间戳,结束时间戳,分页查询偏移量,每页查询最大记录数
不记录时间戳
当查询记录数<每页查询的最大记录数,退出循环
服务端:
使用业务查询条件和时间戳>=开始时间戳 ,时间戳<=结束时间戳及分页信息查询数据.
02
变化量查询
客户端:循环执行
不传递业务查询条件,
传递查询开始时间戳,结束时间戳,分页查询偏移量,每页查询最大记录数
用查询结束时间戳记录时间戳作为下轮查询的开始时间戳
当查询记录数<每页查询的最大记录数,退出循环
服务端: 使用时间戳>=开始时间戳及分页信息查询数据
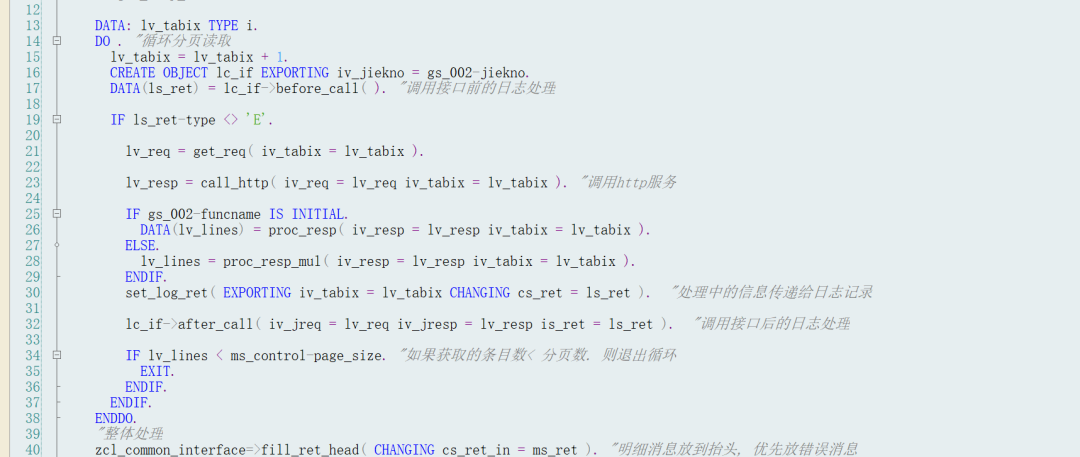
客户端代码示例:
分页查询的偏移量的处理:
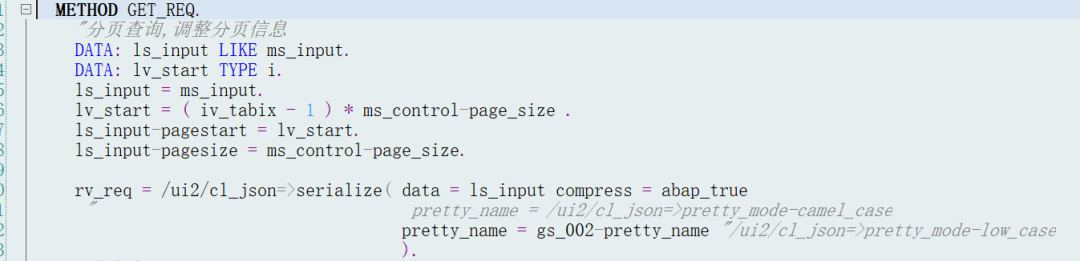
服务端代码示例
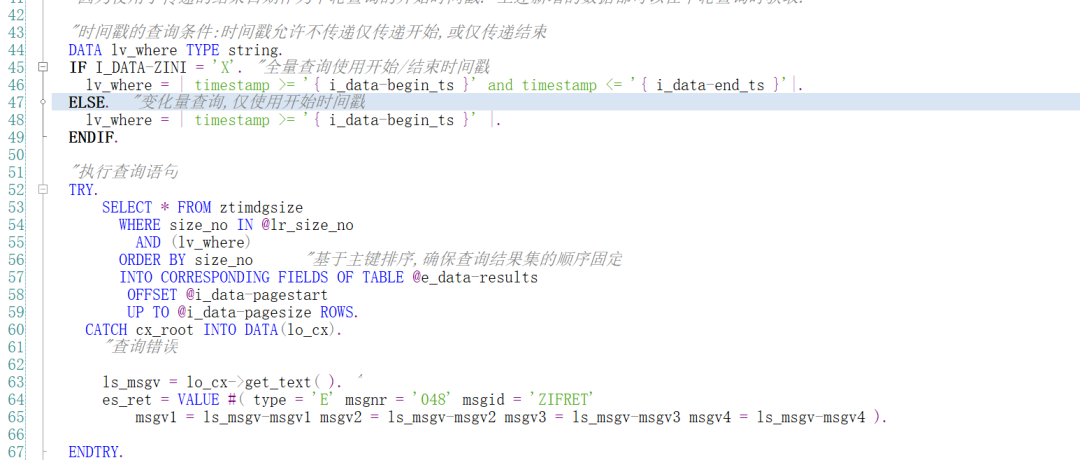
九
其它安全的分页方式
先获取查询集的所有关键字或所有查询集内容,
如果查询集个数<=每页查询最大记录数,一次性返回所有查询内容.
如果查询集个数>每页查询最大记录数,生成一个查询号临时存储本次查询的所有关键字或数据,返回第一页的数据,附带这个查询号.
后续查询需要添加该查询号及偏移量. 根据查询号获取关键字信息或全部内容, 如果是关键字信息,再根据偏移量及每页查询的最大记录数关联查询数据返回
定期删除过期的查询号临时存储的数据(关键字或全部数据集)
这种分页查询的方式可以确保不会存在数据遗漏,但是因为设计到全量查询及查询的关键字或结果集的存储,对系统性能开销较大.
十
总结
数据的物理删除无法通过查询方式传递到目标系统.
对于专门的数据同步工具,
SAP DS 基于查询语句获取数据也无法解决这个问题.
SAP SLT 根据数据库的日志获取数据的改变信息,可以把删除传递到目标系统实现数据的删除
因此设计系统尽量不要使用物理删除数据,而使用删除标记字段标记数据的删除.
变化量的分页查询在时间戳的记录及服务端使用时间戳的方式上需要特别注意, 使用不当容易出现数据丢失或不一致的情况.
时间戳方式无论如何都可能造成数据重复传输的情况, 仅适用于主数据的传输. 对于单据类数据最好使用标记字段及锁来确保数据的一次性传输
THE
END
约定
如果你对这篇文章感兴趣,请帮忙点赞,在看,分享.
请微信联系管理员:
syjf1976
sharry_xlp
Yannick_Duan
申请进入公众号讨论群提问或者参与话题讨论

















 1026
1026

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









