




原文首发于微信公众号whttps://mp.weixin.qq.com/s/AXCiIDcGVlj8DW3AsVFePQ
微信公众号-人工智能与图像处理:目标检测算法-YOLOV11解析
一,YOLOV11概述
YOLOv11是由Ultralytics公司开发的新一代目标检测算法,它在之前YOLO版本的基础上进行了显著的架构和训练方法改进。整合了改进的模型结构设计、增强的特征提取技术和优化的训练方法。真正让YOLO11脱颖而出的是它令人印象深刻的速度、准确性和效率的结合,使其成为Ultralytics迄今为止创造的最强大的型号之一。通过改进设计,YOLO11提供了更好的特征提取,这是从图像中识别重要模式和细节的过程,即使在具有挑战性的场景中,也可以更准确地捕捉复杂的方面。
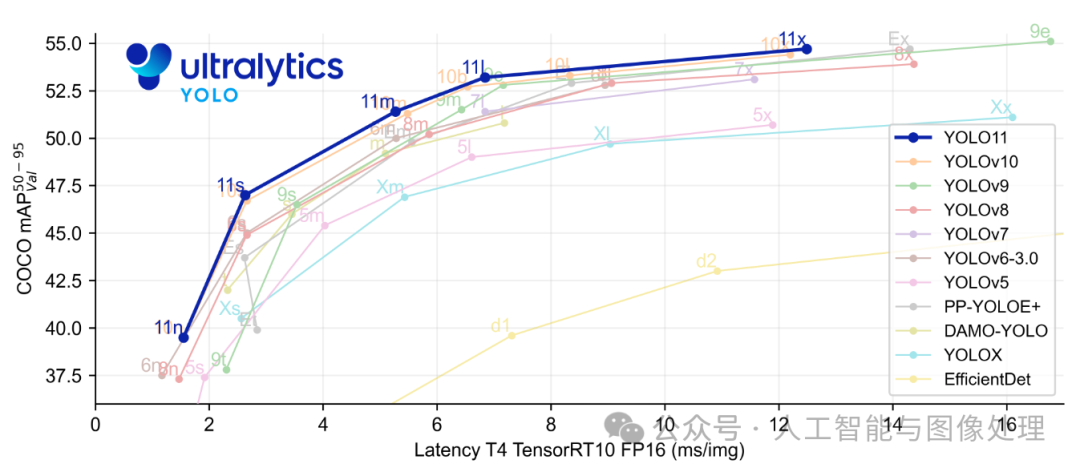
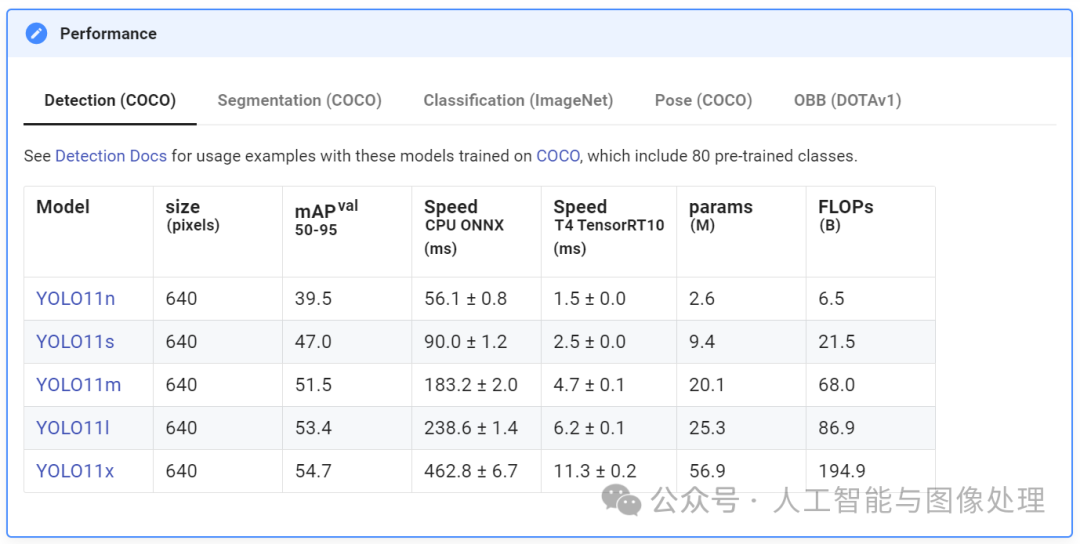
YOLO11m在COCO数据集上实现了更高的平均精度(mAP)得分,同时使用的参数比YOLOv8m少22%,使其在不牺牲性能的情况下计算更轻。这意味着它提供了更准确的结果,同时运行效率更高。最重要的是,YOLO11带来了更快的处理速度,推理时间比YOLOv10快约2%,使其成为实时应用程序的理想选择。
1、主要创新点:
-
增强的特征提取:YOLOv11采用了改进的骨干网络和颈部架构,增强了特征提取能力,以实现更精确的目标检测和复杂任务的性能。
-
优化效率和速度:引入了精细的架构设计和优化的训练流程,提供了更快的处理速度,并在准确性和性能之间保持了最佳平衡。
-
更少参数下的高准确度:YOLOv11在COCO数据集上实现了更高的平均精度均值(mAP),同时比YOLOv8少用了22%的参数,使其在不牺牲准确性的情况下具有计算效率。
-
跨环境的适应性:YOLOv11可以无缝部署在各种环境中,包括边缘设备、云平台和支持NVIDIA GPU的系统,确保了最大的灵活性。
-
支持广泛的任务:YOLOv11不仅支持目标检测,还支持实例分割、图像分类、姿态估计和定向目标检测(OBB),满足一系列计算机视觉挑战。

2、YOLOv11的网络结构和关键创新点包括:
-
C3k2机制:这是一种新的卷积机制,它在网络的浅层将c3k参数设置为False,类似于YOLOv8中的C2f结构。
-
C2PSA机制:这是一种在C2机制内部嵌入的多头注意力机制,类似于在C2中嵌入了一个PSA(金字塔空间注意力)机制。
-
深度可分离卷积(DWConv):在分类检测头中增加了两个DWConv,这种卷积操作减少了计算量和参数量,提高了模型的效率。
-
自适应锚框机制:自动优化不同数据集上的锚框配置,提高了检测精度。
-
EIoU损失函数:引入了新的EIoU(Extended IoU)损失函数,考虑了预测框与真实框的重叠面积,长宽比和中心点偏移,提高了预测精度。
3、训练:
YOLOv11的训练过程包括数据准备、数据增强、超参数优化和模型训练几个阶段。它使用混合精度训练技术,在不降低模型精度的情况下,加快了训练速度,并减少了显存的占用。
4、部署:
在部署方面,YOLOv11支持导出为不同的格式,如ONNX、TensorRT和CoreML,以适应不同的部署平台。它还采用了多种加速技术,如半精度浮点数推理(FP16)、批量推理和硬件加速,以提升推理速度。
YOLOv11的成功标志着目标检测技术又迈出了重要的一步,它为开发者提供了更强大的工具来应对日益复杂的视觉检测任务。
二、各个模块解析
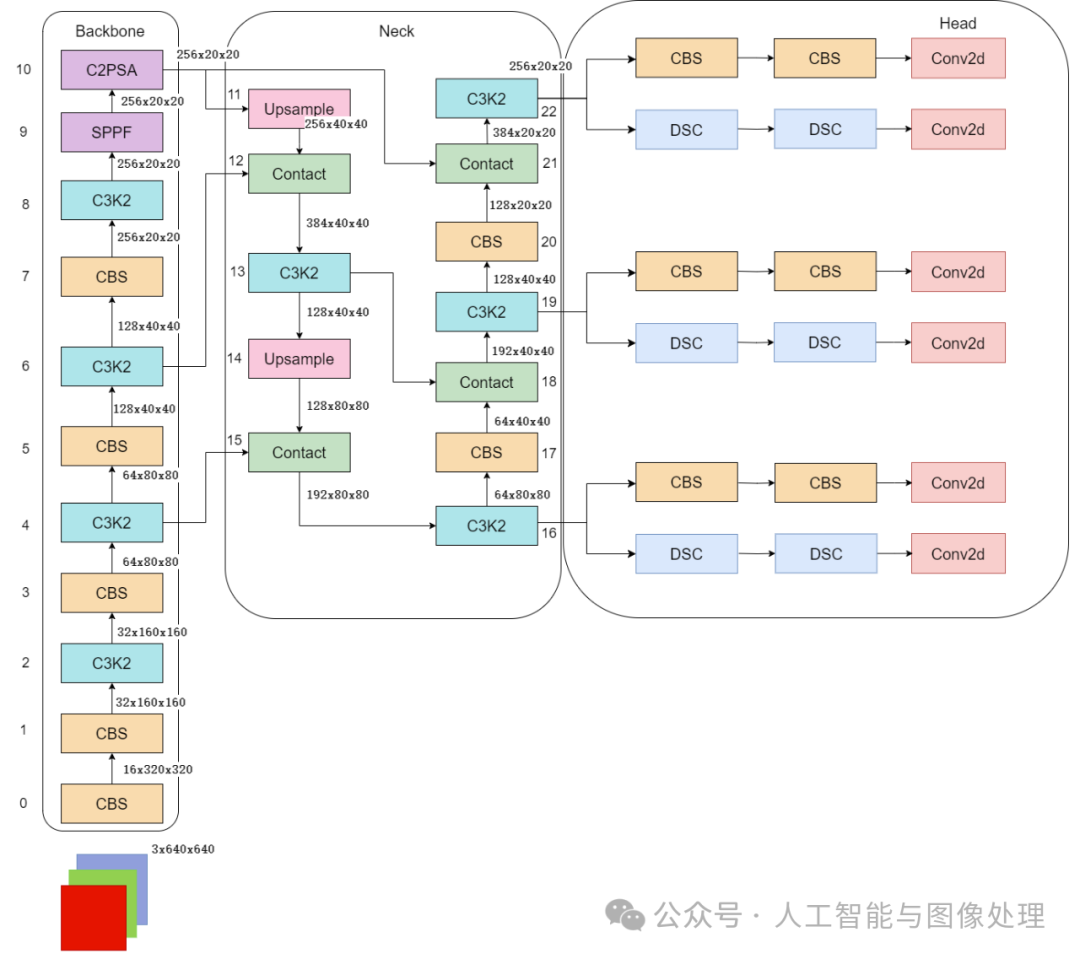
整体的检测算法框架图如下(yolov11n)
1、input
输入要求以及预处理,可选项比较多,可以参考这个配置文件:ultralytics/ultralytics/nn/tasks.py at main · ultralytics/ultralytics (github.com) · GitHub 的Hyperparameters 部分。
基础输入仍然为640*640。预处理就是熟悉的letterbox(根据参数配置可以为不同的缩放填充模式,主要用于resize到640)+ 转换rgb、chw、int8(0-255)->float(0-1),注意没有归一化操作。需要注意的是作者实现的mosaic和网上看到的不同,对比如下图(上边网上版本,下边是YOLO的实现)。并且作者添加了在最后10轮关闭mosaic增强。


2、backbone
主干网络以及改进
这里不去特意强调对比YOLOv5、V8等等的改进,因为各个系列都在疯狂演进,着重看看一些比较重要的模块即可。源代码:
大多数模块:ultralytics/ultralytics/nn/modules/block.py at main · ultralytics/ultralytics (github.com)
head 部分:ultralytics/ultralytics/nn/modules/head.py at main · ultralytics/ultralytics (github.com)
串联模块构造网络:ultralytics/ultralytics/nn/tasks.py at main · ultralytics/ultralytics (github.com)
1)CBS 模块(后面叫做Conv)
就是pytorch 自带的conv + BN +SiLU,这里对应上面的配置文件的Conv 的 args 比如[64, 3, 2] 就是 conv2d 的c2=64、k=3、 s =2、c1 自动为上一层参数、p 为自动计算,真实需要计算scales 里面的with 和 max_channels 缩放系数。
这里连续使用两个3*3卷积stride为2的CBS模块直接横竖各降低了4倍分辨率(整体变为原来1/16)。这个还是比较猛的,敢在如此小的感受野下连续两次仅仅用一层卷积就下采样,当然作为代价它的特征图还是比较厚的分别为16、32。

class Conv(nn.Module):"""Standard convolution with args(ch_in, ch_out, kernel, stride, padding, groups, dilation, activation)."""default_act = nn.SiLU() # default activationdef __init__(self, c1, c2, k=1, s=1, p=None, g=1, d=1, act=True):"""Initialize Conv layer with given arguments including activation."""super().__init__()self.conv = nn.Conv2d(c1, c2, k, s, autopad(k, p, d), groups=g, dilation=d, bias=False)self.bn = nn.BatchNorm2d(c2)self.act = self.default_act if act is True else act if isinstance(act, nn.Module) else nn.Identity()def forward(self, x):"""Apply convolution, batch normalization and activation to input tensor."""ret
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 4万+
4万+

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









