






导读
降维是机器学习从业者可视化和理解大型高维数据集的常用方法。最广泛使用的可视化技术之一是 t-SNE,但它的性能受到数据集规模的影响,并且正确使用它可能需要一定学习成本。
UMAP 是 McInnes 等人开发的新算法。与t-SNE相比,它具有许多优势,最显着的是提高了计算速度并更好地保留了数据的全局结构。在本文中,我们将了解UMAP背后的理论,以便更好地了解该算法的工作原理、如何正确有效地使用它,以及与t-SNE进行比较,它的性能如何。
那么,UMAP带来了什么?最重要的是,UMAP速度很快,在数据集大小和维度方面都可以很好地扩展。例如,UMAP可以在不到 3 分钟的时间内降维 784 维、70,000 点的 MNIST 数据集,而 scikit-learn 的t-SNE需要 45 分钟。此外,UMAP倾向于更好地保留数据的全局结构。这可以归因于UMAP强大的理论基础,使得算法能够更好地在强调局部结构与全局结构之间取得平衡。
1. UMAP vs t-SNE
在深入探讨UMAP背后的理论之前,让我们看一下它在现实世界的高维数据上的表现。下面的图片显示了使用UMAP和t-SNE将 784 维 Fashion MNIST 数据集的子集降维到 3 维上的情况。请注意每个不同类别的聚类程度(局部结构),而相似的类别(例如凉鞋、运动鞋和踝靴)倾向于聚集(全局结构)。
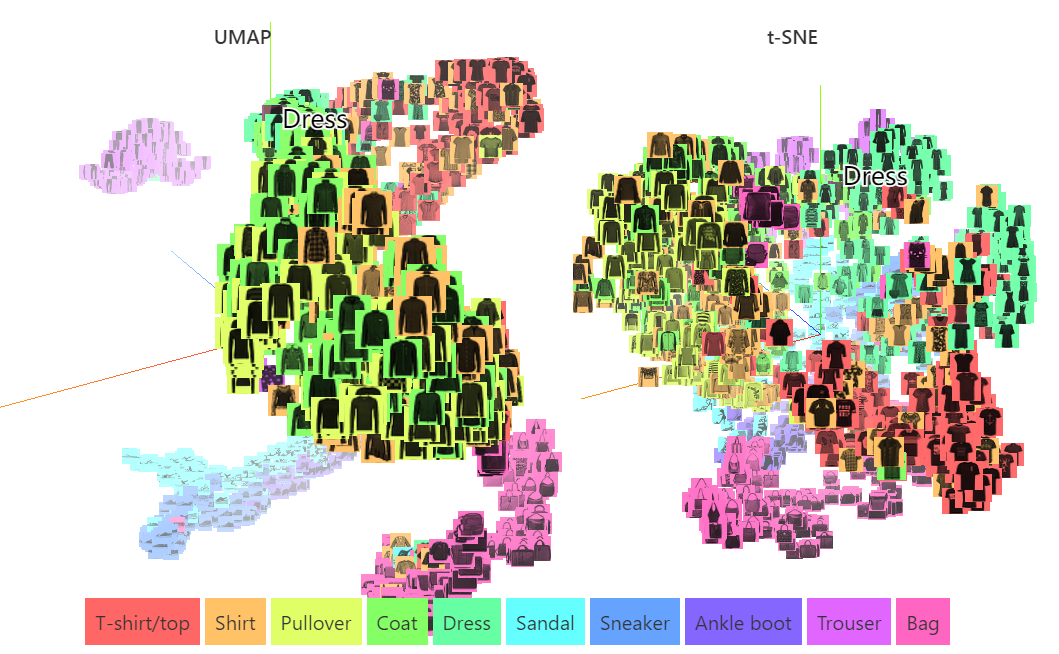
虽然这两种算法都表现出强大的局部聚类,并将相似的类别聚集在一起,但UMAP 更清楚地将这些相似类别的组彼此分开。值得注意的是,计算时间,UMAP需要 4 分钟,而多核t-SNE需要 27 分钟。
2. 理论
UMAP的核心与t-SNE非常相似,两者都使用图形布局(graph layout)算法在低维空间中排列数据。简单来说,UMAP首先构建数据的高维图表示,然后优化低维图以使其在结构上尽可能相似。虽然UMAP用于构建高维图的数学是复杂的,但背后的想法是非常简单的。
为了构建初始的高维图,UMAP构建了一个叫做fuzzy simplicial complex的东西。这实际上只是加权图的表示,边权重表示两个点连接的可能性。为了确定连通性,UMAP从每个点向外扩展一个半径,当这些半径重叠时连接点。这个半径的选择很关键:太小会导致小而孤立的集群,太大会将所有东西全连接在一起。UMAP根据到每个点的第 n 个最近邻点的距离在本地选择半径来克服这个困难。UMAP然后通过随着半径的增长降低连接的可能性来使图形fuzzy。最后,通过规定每个点必须至少连接到其最近的邻居,UMAP确保局部结构与全局结构保持平衡。
一旦构建了高维图,UMAP就会优化低维模拟的布局,使其尽可能相似。这个过程与t-SNE基本相同,但使用了一些技巧来加速该过程。
有效使用UMAP的关键在于理解初始高维图的构造。尽管该过程背后的想法非常直观,但该算法依赖于一些高级数学来为该图实际表示数据的程度提供强有力的理论保证。有兴趣的读者可以在:深入了解UMAP理论。
3. 参数
通过理解UMAP背后的理论后,理解算法的参数变得容易得多,尤其是与t-SNE中的perplexity参数相比。我们将考虑两个最常用的参数:n_neighbors 和 min_dist,它们有效地用于控制最终降维结果中局部和全局结构之间的平衡。

n_neighbors
最重要的参数是n_neighbors,用于构造初始高维图的近似最近邻的数量。它有效地控制UMAP如何平衡局部结构与全局结构 :较小的值将通过限制在分析高维数据时考虑的相邻点的数量来推动UMAP更多地关注局部结构,而较大的值将推动UMAP代表全局结构,同时失去了细节。
min_dist
我们将研究的第二个参数是 min_dist,即低维空间中点之间的最小距离。此参数控制UMAP将点聚集在一起的紧密程度,较低的值会导致嵌入更紧密。较大的 min_dist值将使UMAP将点更松散地打包在一起,而是专注于保留广泛的拓扑结构。
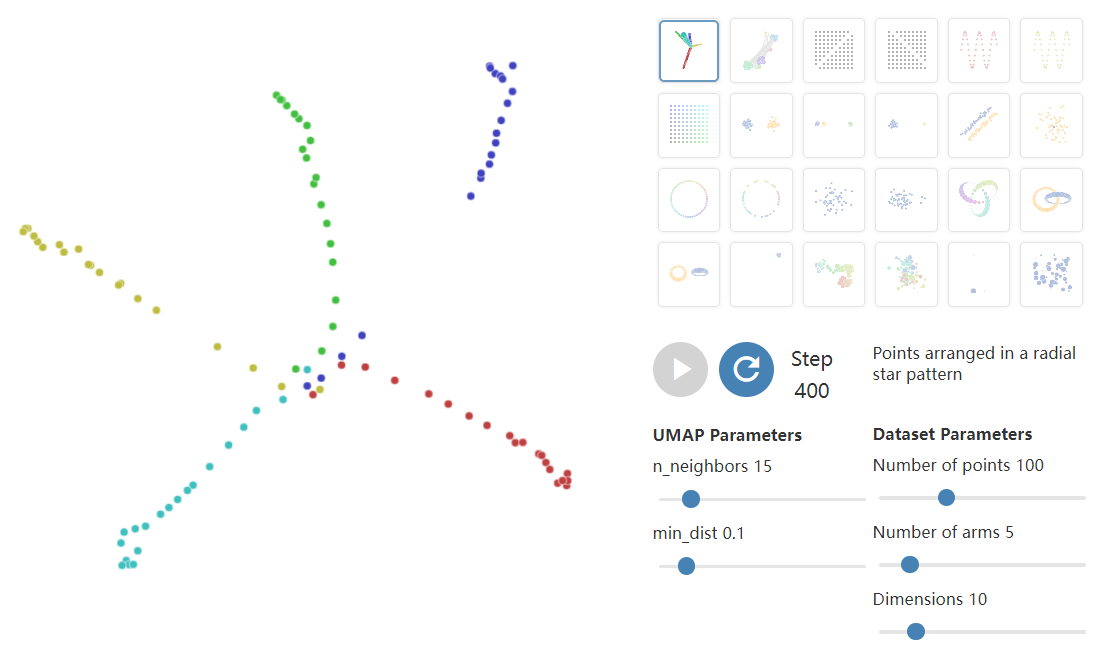
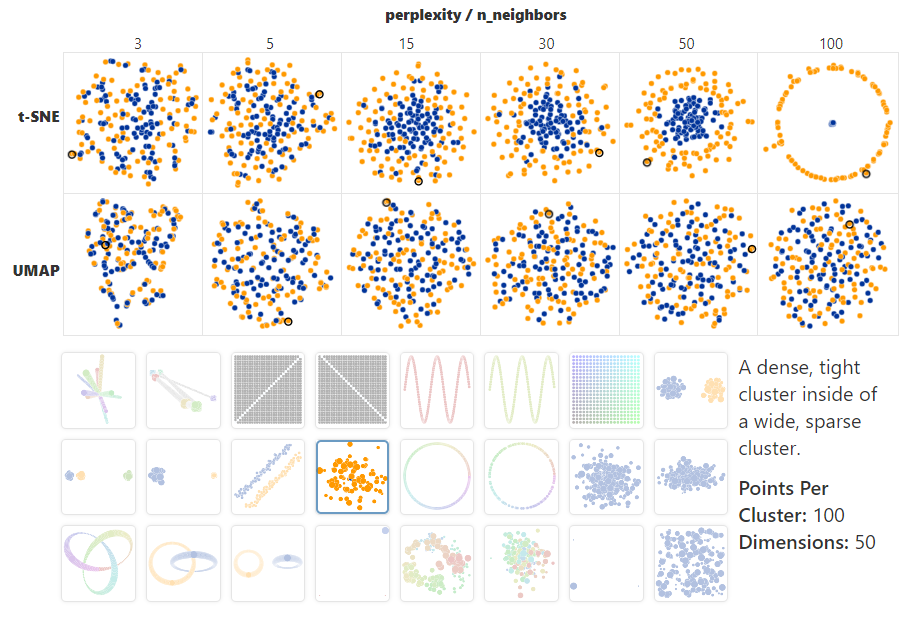
下面的可视化,探索了UMAP参数对 3D 数据的 2D 投影的影响。通过更改 n_neighbors和min_dist参数,您可以探索它们对生成投影的影响。
虽然UMAP的大多数应用都涉及高维数据的投影,但 3D 的投影可以作为一个有用的类比来理解UMAP如何根据其参数优先考虑全局结构和局部结构。随着n_neighbors的增加,UMAP在构建高维数据的图表示时连接的相邻点越来越多,从而导致更准确地反映数据的全局结构的投影。在非常低的值下,任何全局结构的信息都几乎完全丢失。随着min_dist参数的增加,UMAP倾向于“散开”投影点,导致数据的聚类减少,对全局结构的重视程度降低。
4. UMAP vs t-SNE 2.0
与t-SNE相比,UMAP的输出最大的区别在于局部结构和全局结构之间的平衡,UMAP 通常更擅长在最终投影中保留全局结构。这意味着簇间的关系可能比 t-SNE更有意义。重要的是,因为UMAP和t-SNE在投影到低维时都必然会扭曲数据的高维形状,所以任何给定的轴或较低维度的距离仍然不能用 PCA 等技术直接解释。
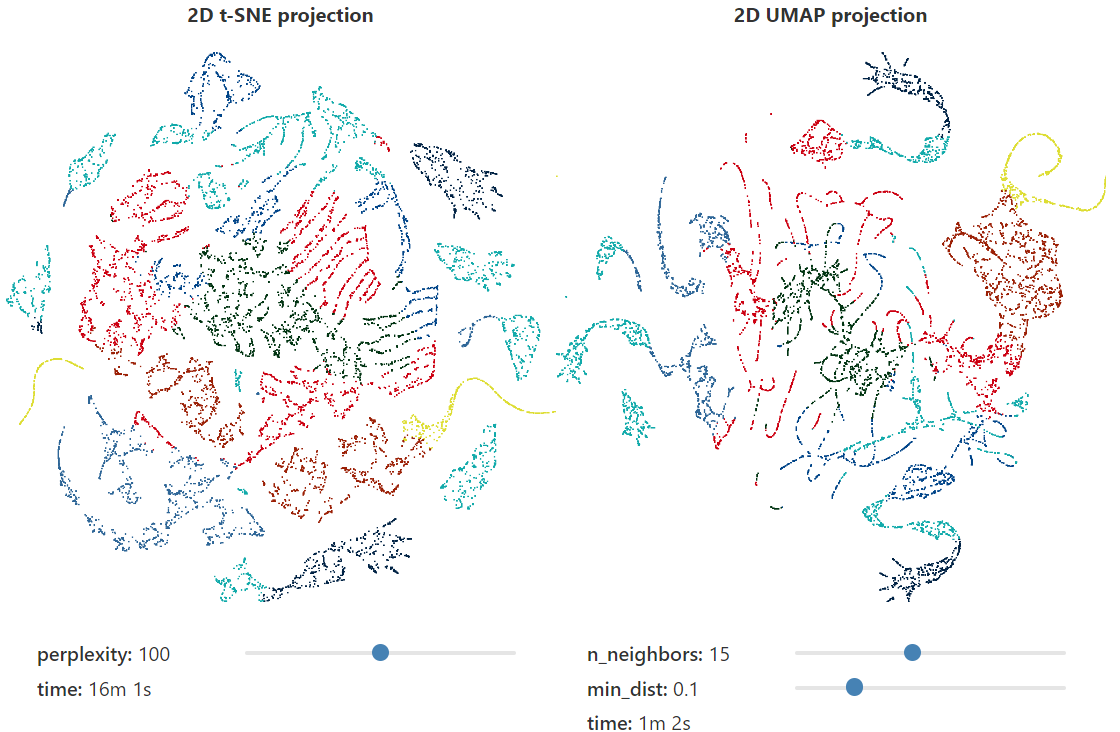
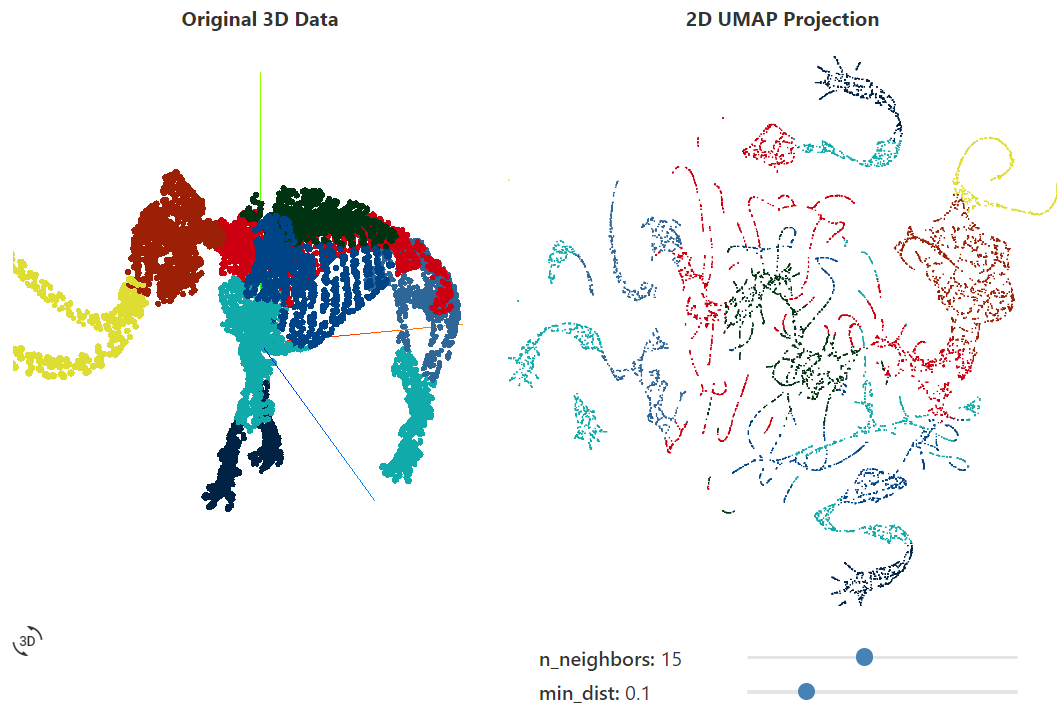
回到 3D 猛犸象的例子,我们可以很容易地看到两种算法输出之间的一些巨大差异。对于较低的perplexity参数值,t-SNE倾向于“展开”投影数据,而很少保留全局结构。相比之下,UMAP倾向于将高维结构的相邻部分在低维中组合在一起,这反映了全局结构。注意,使用t-SNE需要极高的perplexity(~1000)才能开始看到全局结构,并且在如此大的perplexity值下,计算时间显著延长。同样值得注意的是,每次运行的t-SNE投影差异很大,不同的高维数据被投影到不同的位置。虽然UMAP也是一种随机算法,但令人惊讶的是,每次运行和使用不同参数时,生成的投影是十分相似的。
值得注意的是,t-SNE和UMAP在早期图中的玩具示例上的表现非常相似,除了下面的示例例外。有趣的是,UMAP无法分离两个嵌套集群,尤其是在高维时。
该算法未能处理这种包含的情况可能是由于UMAP在初始图形构造中使用的是局部距离。由于高维点之间的距离往往非常相似(维度灾难),UMAP似乎将内部集群的外部点与外部集群的外部点连接起来。这实际上将两个集群混合在一起。
5. 理解
虽然UMAP提供了许多优于t-SNE的优势,但它绝不是灵丹妙药,阅读和理解其结果需要小心谨慎。
- 超参数真的很重要
选择好的超参数并不容易,并且取决于数据和目标。这是UMAP速度的一大优势所在,通过使用各种超参数多次运行UMAP,您可以更好地了解投影如何受其参数影响。
- 簇大小没有任何意义
就像在t-SNE中一样,簇相对于彼此的大小本质上是没有意义的。这是因为UMAP使用局部距离概念来构建其高维图形表示。
- 集群之间的距离可能没有任何意义
同样,集群之间的距离可能毫无意义。虽然确实在UMAP中更好地保留了集群的全局位置,但它们之间的距离没有意义。同样,这是由于在构建图形时使用了局部距离。
- 随机噪声并不总是看起来随机
尤其是在n_neighbors值较低时,可以观察到虚假聚类。
- 需要多次可视化结果
由于UMAP算法是随机的,因此使用相同超参数的不同运行可能会产生不同的结果。此外,由于超参数的选择非常重要,因此使用各种超参数多次运行投影可能非常有用。
总结
UMAP是数据科学家武器库中非常强大的工具,与t-SNE相比具有许多优势。虽然UMAP和 t-SNE 的输出有些相似,但速度的提高、全局结构的更好保存和更易于理解的参数使UMAP成为可视化高维数据的更有效工具。最后,重要的是要记住,没有任何降维技术是完美的,UMAP也不例外。然而,通过建立对算法工作原理的直观理解以及如何调整其参数,我们可以更有效地使用这个强大的工具来可视化和理解大型高维数据集。
本文由mdnice多平台发布

















 768
768

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









