





摘要:本文系统介绍生成模型的基本概念、作用及其在现代深度学习中的核心地位。我们将从自动编码器(Autoencoder)出发,逐步深入到变分自编码器(VAE),并为后续引入生成对抗网络(GAN)奠定基础。
一、什么是生成模型?
✅ 定义
在概率统计中,生成模型(Generative Model)是指能够在给定某些隐含参数的条件下,随机生成符合真实数据分布的新样本的模型。
它能:
- 学习训练数据的联合概率分布
- 根据该分布进行采样,生成新的数据点
🌐 类比:
就像你学会了一种语言的语法和词汇后,不仅能理解句子,还能自己造句。
二、生成模型的核心能力
生成模型的关键在于建模数据的真实分布:
-
直接建模数据分布
- 给定输入
,预测其分布
- 可用于数据采样、插值、补全等任务
- 给定输入
-
条件生成
- 如:
—— 给定图像生成文字(OCR)
- 或:
—— 给定类别生成图像(如生成猫)
- 如:
-
高维复杂分布建模
- 图像、语音、文本等都属于高维数据
- 传统方法难以处理,而生成模型擅长于此
三、生成模型的作用与意义
尽管生成模型看似“制造假数据”,但其价值远不止于此。
🔧 应用场景广泛
| 领域 | 应用示例 |
|---|---|
| 计算机视觉 | 图像超分辨率重建、风格迁移、艺术创作 |
| 自然语言处理 | 文本生成、对话系统、机器翻译 |
| 医学影像 | 医学图像合成、病变模拟、数据增强 |
| 工业设计 | 自动生成产品原型、建筑设计 |
| 娱乐产业 | AI 绘画、虚拟角色生成、游戏内容生成 |
💡 例如:
- 使用生成模型将老照片修复成高清版;
- 输入“一只奔跑的红色狐狸”,生成对应图像;
- 自动生成小说或诗歌。
四、经典生成模型演进路线
我们从最简单的结构开始,逐步迈向更强大的生成能力。
1. 自动编码器(Autoencoder)
🔍 基本结构
输入 → 编码器 → 隐含层(压缩表示) → 解码器 → 输出
- 编码器:将原始数据压缩为低维向量(latent code)
- 解码器:将低维向量还原为原始数据
✅ 目标:让输出尽可能接近输入(重构误差最小)
📊 示例:手写数字重建
原图: 2
编码: [0.1, -0.5, 0.8, ...]
解码: ≈ 2(略有模糊)
⚠️ 局限性:
- 无法自由生成新数据
- 仅能还原已见过的数据
- 隐含空间缺乏结构性(不可控)
2. 变分自编码器(Variational Autoencoder, VAE)
🚀 改进目标
解决普通 AE 的问题:不能生成任意新数据
🔁 核心思想
- 强制隐含变量服从一个先验分布(通常是标准正态分布)
- 在编码阶段,不输出固定向量,而是输出均值和方差
- 通过 KL 散度 拉近后验分布与先验分布的距离
🔧 训练损失函数
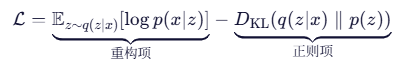
✅ 第一项:希望生成图像尽量像原图;
✅ 第二项:希望隐含变量接近标准正态分布。
🎨 VAE 的强大之处:连续生成
我们可以对隐含空间进行插值:
- 从“手写数字 0”对应的编码 → “手写数字 1”对应的编码
- 在中间插入多个点,解码后得到平滑过渡的图像
🔍 示例:
从左下角的0到右上角的1,中间逐渐变化,形成连续的数字变形序列。

✅ 这说明 VAE 已经学会了数据的潜在结构!
五、VAE 的局限性
尽管 VAE 是一个重要的进步,但它仍存在明显缺陷:
| 缺陷 | 说明 |
|---|---|
| 生成质量一般 | 图像模糊、细节丢失 |
| 模式崩溃风险 | 只能生成少数几种典型样本 |
| 过度拟合真实数据 | 更倾向于复制训练集中的样本,而非创造新事物 |
❌ 举个例子:
如果训练集中有很多“狗”的图片,VAE 很可能只生成各种“狗”,而不会尝试生成“猫”。
六、未来主角登场:生成对抗网络(GAN)
为了克服 VAE 的不足,Ian Goodfellow 提出了 生成对抗网络(GAN)。
🤝 GAN 的核心机制
GAN 由两个网络组成:
- 生成器(Generator):负责生成“假”数据
- 判别器(Discriminator):判断数据是“真”还是“假”
两者进行“零和博弈”:
- 生成器努力骗过判别器
- 判别器努力识别出假货
✅ 最终达到纳什均衡时,生成器能产生以假乱真的数据。
七、总结 :生成模型的发展脉络
| 模型 | 能力 | 局限 | 后续发展 |
|---|---|---|---|
| Autoencoder | 数据压缩、重构 | 不能生成新数据 | → VAE |
| VAE | 可控生成、隐空间连续 | 图像模糊、模式坍塌 | → GAN |
| GAN | 高质量生成、逼真图像 | 训练不稳定、模式崩溃 | → StyleGAN, Diffusion Models |



















 1269
1269

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









