



🔍 前言:为什么要画这张图?
本文参考【小白也能听懂的 bert模型原理解读 预训练语言模型】https://www.bilibili.com/video/BV1Km41117VG?vd_source=e14fbfa32a7c9167af15da4f1666253a![]() https://www.bilibili.com/video/BV1Km41117VG?vd_source=e14fbfa32a7c9167af15da4f1666253a
https://www.bilibili.com/video/BV1Km41117VG?vd_source=e14fbfa32a7c9167af15da4f1666253a
最近在复习 BERT 模型时,发现很多文章讲得过于抽象,公式一堆但看不懂“到底发生了什么”。于是我自己动手画了一张 BERT 手绘结构图,边画边理解,终于把它的核心机制彻底搞明白了!
今天我就用这张图,带你一步步拆解 BERT 到底是怎么工作的——不讲复杂公式,只讲本质逻辑,保证你看完能给别人讲清楚!
📌 本文适合人群:
- 想入门 NLP 的新手
- 准备面试的同学
- 对 Transformer 和 BERT 似懂非懂的开发者
🖼️ 第一步:先看手绘图(重点来了)
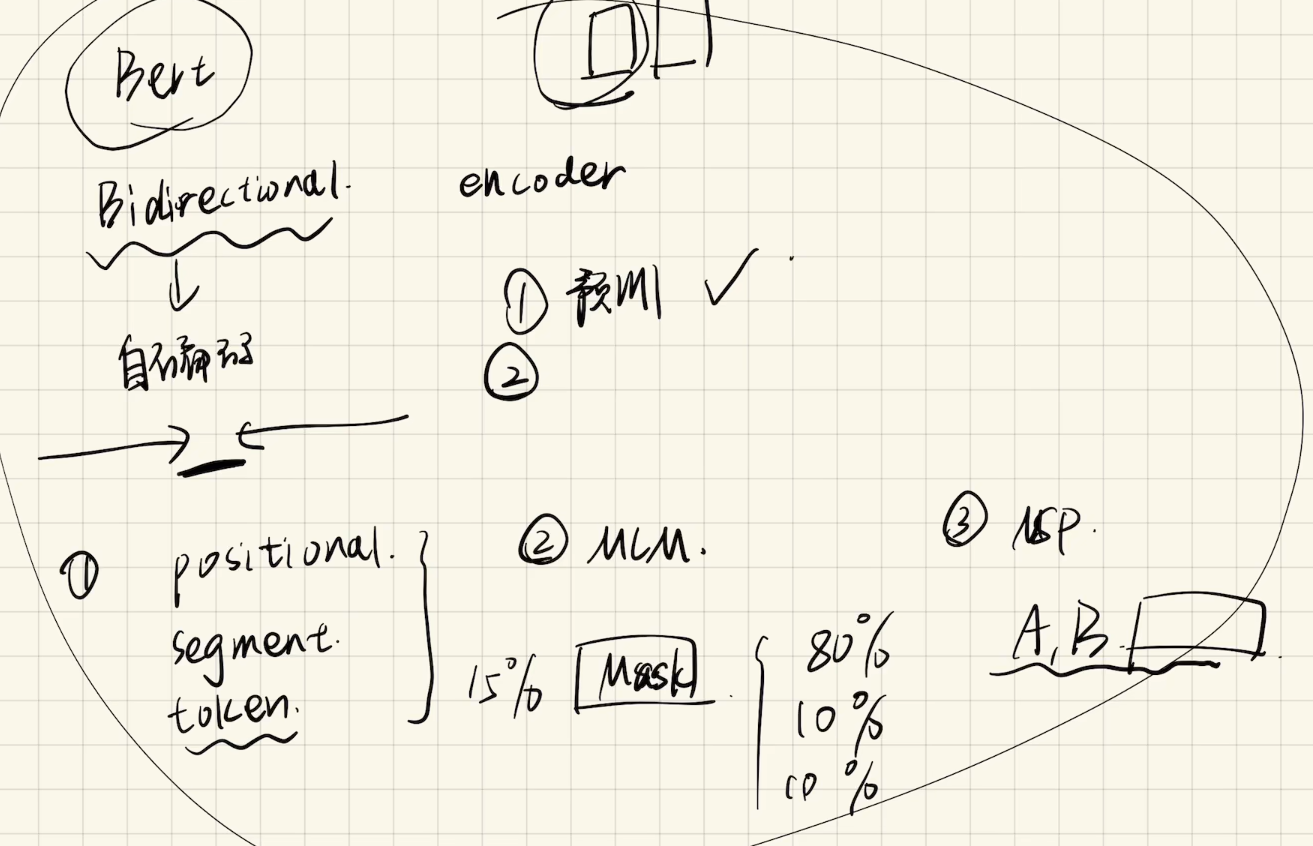
别看它潦草,但这张图包含了 BERT 的所有关键组件:
- Bidirectional
- Encoder
- Token / Position / Segment Embedding
- Masked Language Model (MLM)
- Next Sentence Prediction (NSP)
下面我们一个一个来解读!
✅ 一、BERT 是什么?一句话说清楚
BERT = 双向 + Transformer 编码器 + 预训练语言模型
它是 Google 在 2018 年提出的革命性模型,让机器真正“看懂”上下文,而不是只看前后几个词。
🎯 应用场景:
- 文本分类
- 问答系统(如百度搜索)
- 实体识别(NER)
- 情感分析
🧩 二、输入层:三种嵌入融合,缺一不可!
BERT 的输入不是简单的单词向量,而是三种信息的叠加:
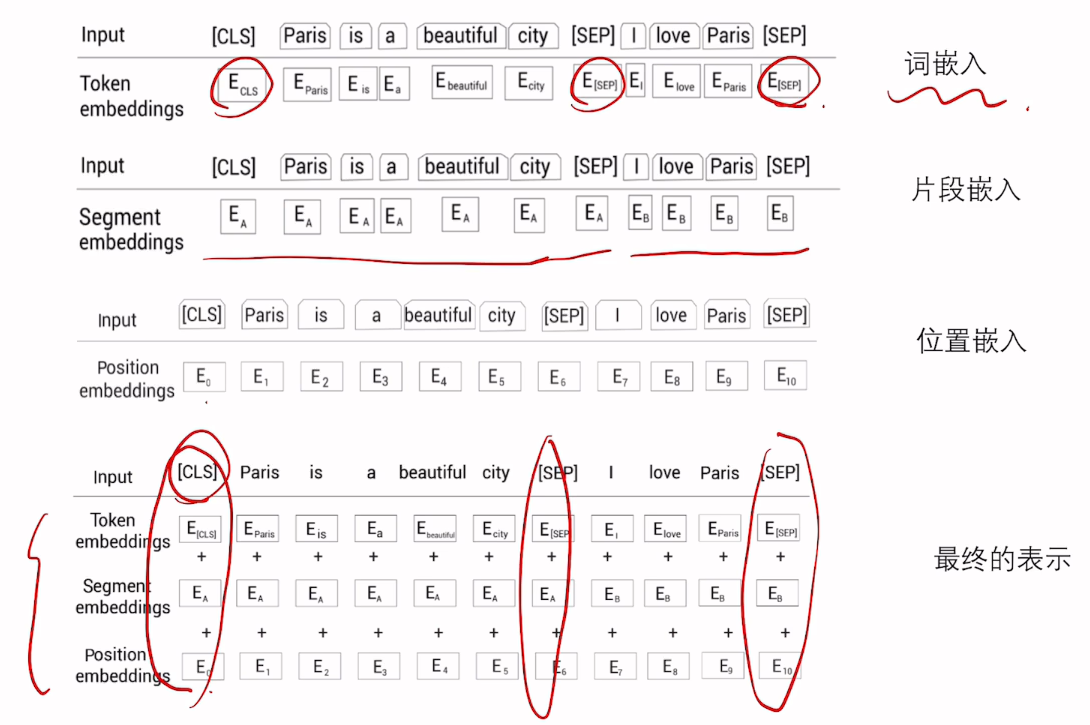
1. Token Embedding(词嵌入)
- 使用 WordPiece 分词法,把句子切成 subword 单元。
- 例如:“playing” → “play” + “##ing”
from transformers import BertTokenizer
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
print(tokenizer.tokenize("我喜欢吃苹果"))
# 输出: ['我', '喜欢', '吃', '苹果']2. Position Embedding(位置嵌入)
- 自注意力机制本身没有顺序概念,所以必须加上位置信息。
- 每个位置都有一个固定的向量表示(可学习)。
3. Segment Embeding(句子类别嵌入)
- 用于区分两个句子 A 和 B。
- 比如 QA 任务中:问题是一个 segment,答案是另一个。
🔹 最终输入 = Token + Position + Segment
📌 图中 [CLS] 和 [SEP] 是什么?
[CLS]:分类标记,用于最终分类任务(如情感分析)[SEP]:分隔符,表示一句结束
🔁 三、核心机制:双向上下文理解
传统模型(如 LSTM)只能从左到右或从右到左读取文本,而 BERT 是双向的!
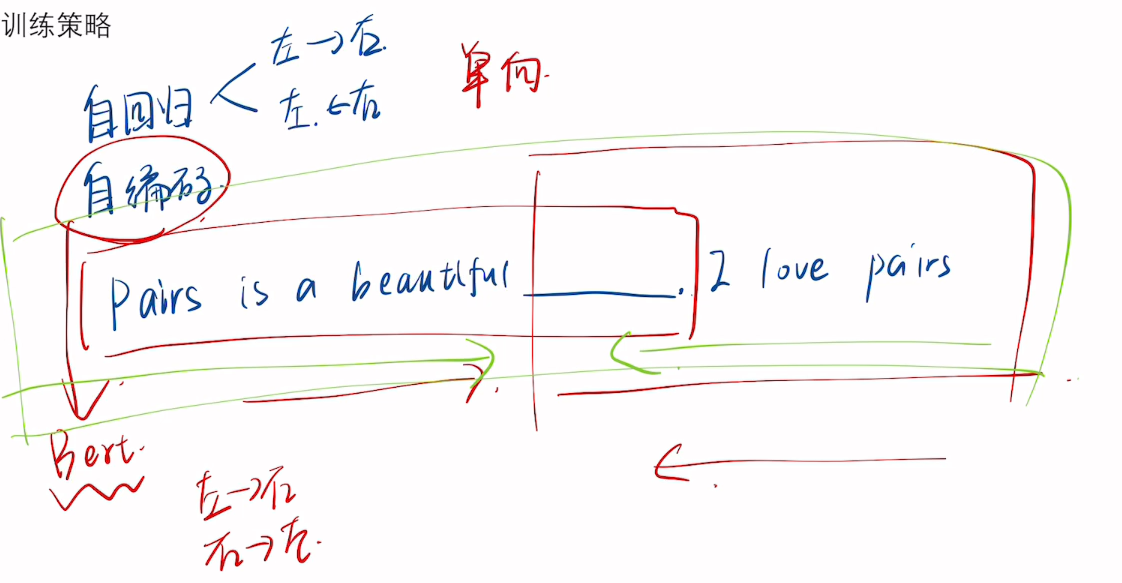
这意味着:
当你看到“银行”这个词时,BERT 能同时知道前面是“去”还是后面是“存款”,从而判断是“河边的 bank”还是“金融机构”。
实现方式:多层 Transformer Encoder
每一层都包含:
- Multi-Head Self-Attention:计算每个词与其他所有词的关系权重
- Feed-Forward Network:进一步提取特征
✅ 效果:每个词的输出向量都融合了整个句子的上下文信息!
🎯 四、预训练任务1:Masked Language Model(MLM)
这是 BERT 学会“猜词”的秘密武器!
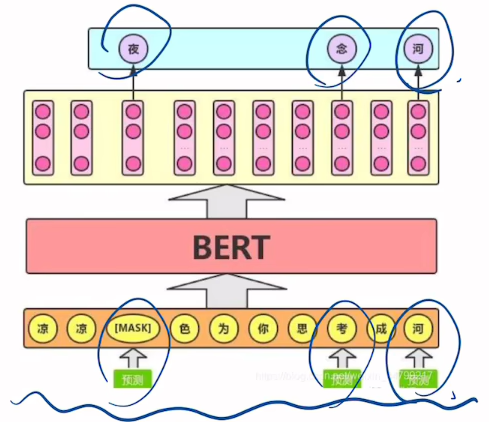
📌 MLM 是怎么做的?
- 随机选择 15% 的 token 进行遮蔽
- 其中:
- 80% 替换为
[MASK] - 10% 替换为随机词
- 10% 保持不变
- 80% 替换为
👉 目的是防止模型偷懒只依赖 [MASK] 标记。
💡 举个例子:
原句:我爱北京天安门
遮蔽后:我爱[MASK]京天安门
BERT 的任务就是预测 [MASK] 应该是“北”。
🎯 训练目标:交叉熵损失函数,最大化正确词汇的概率。
🔄 五、预训练任务2:Next Sentence Prediction(NSP)
除了猜词,BERT 还要学会判断两句话是不是连续的。
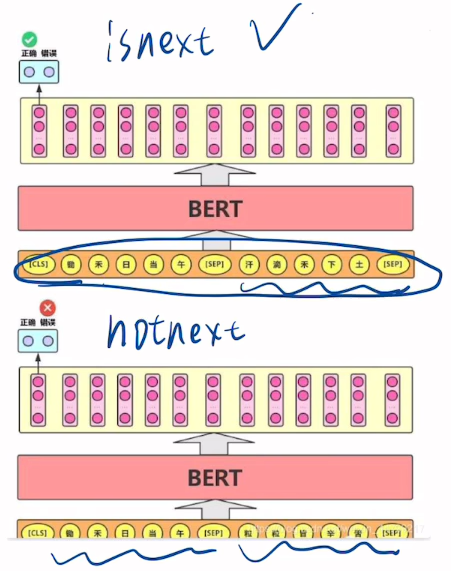
输入格式:
[CLS] 句子A [SEP] 句子B [SEP]任务目标:
- 判断 B 是否是 A 的下一句(Yes/No)
-
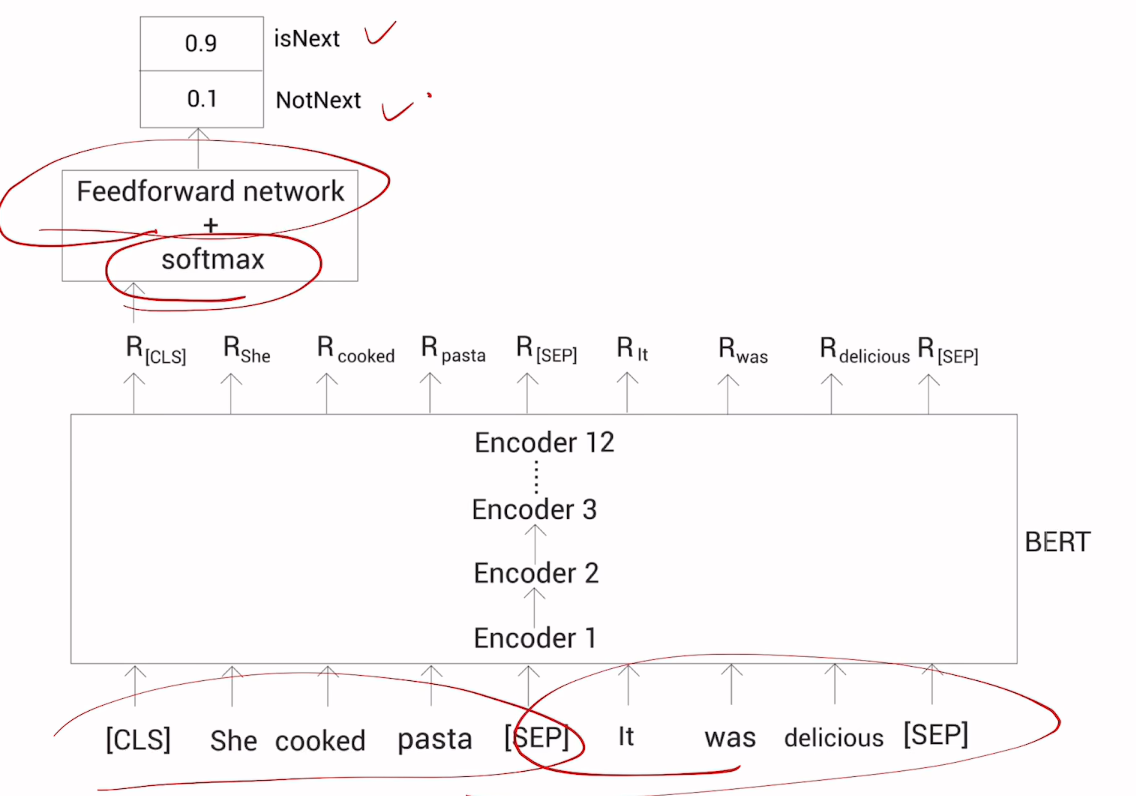
📌 举例说明:
| 句子A | 句子B | 是否连续 |
|---|---|---|
| 我今天很开心 | 因为天气很好 | ✅ 是 |
| 我今天很开心 | 明天要考试了 | ❌ 否 |
📌 这个任务对问答、句子匹配等非常有用!
⚙️ 六、模型结构总览(结合手绘图再看一遍)
让我们再回顾一下这张图的关键点:
| 区域 | 功能 |
|---|---|
| 左上角 “Bidirectional” | 强调模型能同时利用前后文 |
| 中间 “Encoder” | 表示使用的是 Transformer 的编码器部分 |
| 下方三种 embedding | 输入由三部分相加而成 |
| 右侧 MLM & NSP | 两大预训练任务 |
🧠 总结一句话:
BERT 通过双向编码器 + 两种预训练任务,在海量文本上学到了通用的语言理解能力。
🚀 七、下游任务如何微调?
预训练完成后,BERT 就像一个“语言通识学霸”,只需要少量数据就能快速适应具体任务。
常见任务举例:
| 任务类型 | 微调方法 |
|---|---|
| 文本分类 | 取 [CLS] 的输出,接一个全连接层做分类 |
| 命名实体识别(NER) | 取每个 token 的输出,预测标签序列 |
| 问答系统(SQuAD) | 预测答案起始和结束位置 |
| 句子相似度 | 输入两个句子,判断是否相关 |
代码示例(HuggingFace):
from transformers import BertForSequenceClassification, BertTokenizer
import torch
model = BertForSequenceClassification.from_pretrained('bert-base-chinese', num_labels=2)
tokenizer = BertTokenizer.from_pretrained('bert-base-chinese')
inputs = tokenizer("这部电影太好看了!", return_tensors="pt")
with torch.no_grad():
logits = model(**inputs).logits
predicted_class = torch.argmax(logits, dim=-1)
print(predicted_class) # 输出: 1 (正面情感)❗ 八、BERT 的局限与后续发展
虽然 BERT 很强,但也有一些缺点:
| 问题 | 改进方案 |
|---|---|
| 训练成本高 | DistilBERT、TinyBERT(轻量化版本) |
| 不擅长生成 | GPT 系列更适合文本生成 |
| NSP 效果一般 | RoBERTa 移除了 NSP,效果反而更好 |
| 上下文长度限制(512) | Longformer、BigBird 支持更长文本 |
📌 所以后续出现了:
- RoBERTa:优化训练策略
- ALBERT:参数共享降低内存
- DeBERTa:增强解码器设计
- Chinese-BERT-wwm:中文全词掩码版
✅ 九、总结:一张图胜过千言万语
回到开头那张手绘图,你现在是不是已经完全看懂了?
📌 再送你一句口诀,方便记忆:
“双编三嵌,遮词判句,预训微调,通吃 NLP!”
解释:
- 双编:双向编码器
- 三嵌:Token + Position + Segment Embedding
- 遮词:MLM
- 判句:NSP
- 预训微调:Pre-train + Fine-tune
- 通吃 NLP:适用于几乎所有自然语言任务



















 1124
1124

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









