







论文标题:A Universal Model for Human Mobility Prediction
作者:Qingyue Long, Yuan Yuan, Yong Li
机构:清华大学
论文链接:https://arxiv.org/abs/2412.15294
Cool Paper:https://papers.cool/arxiv/2412.152948
TL, DR:本文提出了UniMob,一个基于提示的通用模型,通过灵活处理多样化时空数据、有效的生成预训练和时空知识引导的提示,实现了在多个城市和领域中的卓越泛化能力和城市时空预测性能。
关键词:轨迹预测,流量预测,统一建模

🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅
摘要
预测人类移动对于城市规划、交通管制和应急响应至关重要。移动行为可分为个体和群体,这些行为由各种移动数据记录,例如个体轨迹和群体流量。作为移动数据的不同模态,个体轨迹和群体流量具有紧密的耦合关系。人群流量源于个体轨迹自下而上的聚合,而人群流量施加的约束塑造了这些个体轨迹。由于个体轨迹和群体流量之间的模态差距,现有的移动预测方法仅限于单一任务。在这项工作中,旨在统一移动预测以突破任务特定模型的局限性。提出了一个通用的人类移动预测模型(名为 UniMob),它可以应用于个体轨迹和群体流量。UniMob 利用多视图移动分词器将轨迹和流量数据转换为时空词元,通过diffusion transformer架构促进统一的序列建模。为了弥合这两种数据模式的不同特征之间的差距,实现了一种新颖的双向个体和群体对齐机制。该机制能够从不同的移动数据中学习常见的时空模式,从而促进轨迹和流量预测的相互增强。在现实世界数据集上进行的大量实验验证了UniMob模型在轨迹和流量预测方面优于最先进的基线。特别是在有噪声和稀疏的数据场景中,模型在 MAPE 和 Accuracy@5 方面实现了最高的性能提升,分别超过 14% 和 25%。
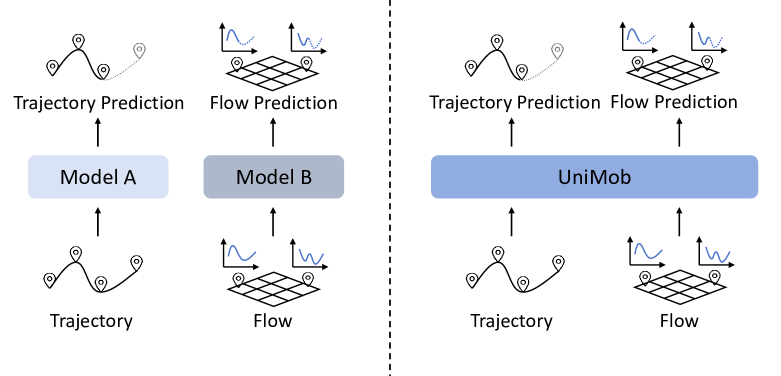
Q: 这篇论文试图解决什么问题?
A: 这篇论文试图解决的问题是如何统一人类移动预测。具体来说,论文指出现有的人类移动预测方法受限于单一任务,因为个体轨迹和群体移动这两种不同模态的移动数据之间存在模态差异。这些方法只能分别针对个体轨迹预测或人群移动预测,而无法实现两者的统一预测。因此,论文提出了一个名为UniMob的通用人类移动预测模型,旨在突破任务特定模型的限制,通过统一建模的方式来同时预测个体轨迹和群体移动。
Q: 有哪些相关研究?

A: 相关研究主要分为以下几个方面:
- 人类移动数据记录和分析:
- 人类移动数据记录人在空间上的移动,支持各种活动,并反映城市的时空动态。
- 个体移动和群体流量预测模型:
- 个体预测关注个人偏好,例如Qiao等人和Wang等人开发的基于马尔可夫模型。
- 群体流量预测强调建模群体移动趋势,例如DeepSTN+和CrowdNet。
- 轨迹和流量数据的集成:
- 一些研究开始整合轨迹和流量数据以更好地理解人类移动,例如TrGNN和GETNext。
- 基于扩散模型的人类移动研究:
- DiffTraj和ControlTraj结合了扩散模型的生成能力和从轨迹中提取的时空特征。
- PriSTI使用条件扩散框架进行时空插补,增强了先验建模。
- 基础模型在时空领域的扩展:
- 基础模型已经在自然语言处理和计算机视觉领域取得了成功,扩展到时空领域是自然的下一步。例如UniST和GPD。
- 大型语言模型(LLMs)在移动预测中的潜力:
- 研究人员开始探索LLMs在移动预测中的潜力,例如LLM-Mob、AgentMove、TrajAgent和CoPB。
Q: 论文如何解决这个问题?
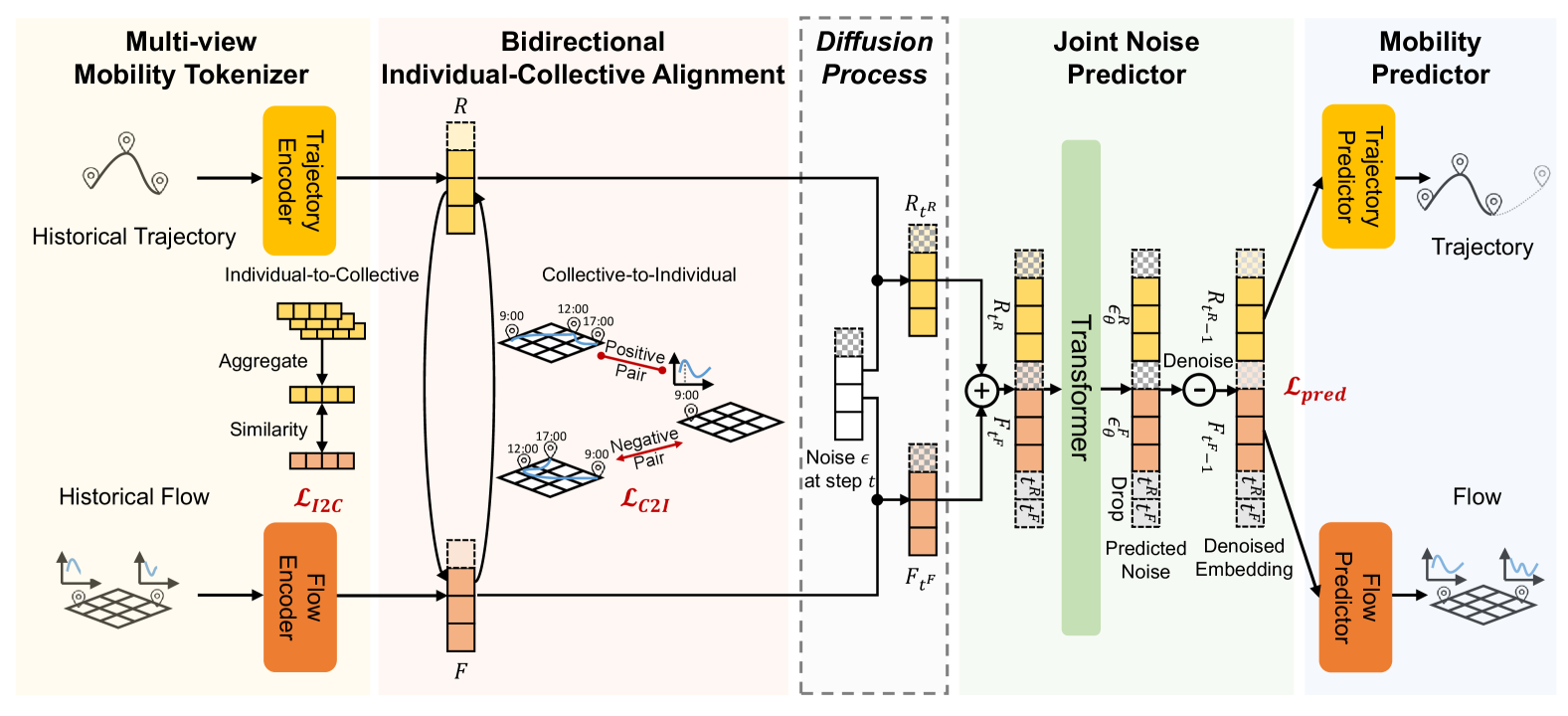
A: 论文通过以下几个关键步骤解决了统一人类移动预测的问题:
-
多视图移动分词器(Multi-view Mobility Tokenizer):
- 设计了一个多视图移动分词器,将个体轨迹和群体移动数据转换为统一的时空词元格式,便于利用强大的扩散变换架构进行建模。
-
双向个体与群体对齐机制(Bidirectional Individual-Collective Alignment):
- 引入了创新的双向对齐机制,包括从个体到群体(Individual-to-Collective)和从群体到个体(Collective-to-Individual)的对齐,以解决两种数据模态之间的显著特征差异。
- 个体到群体对齐通过将聚合后的轨迹与移动数据对齐,帮助建模群体流量趋势。
- 群体到个体对齐使用对比学习来识别语义相似的移动和轨迹,捕获宏观和微观层面上一致的时空模式。
-
联合噪声预测器(Joint Noise Predictor):
- 学习移动行为的时空分布可以表示为去噪扩散过程,使用联合噪声预测器为轨迹和移动建模个体和群体移动。
-
移动预测器(Mobility Predictor):
- 目标是将嵌入转换回原始数据形式,捕获轨迹或移动的动态变化,并实现准确的预测结果。
-
训练与损失函数(Training and Loss Function):
- 模型的训练受到三种损失的监督:I2C损失、C2I损失和预测损失。前两个损失旨在促进个体和群体之间的对齐,而预测损失则针对扩散模型的联合噪声预测器,以估计需要去除的噪声并提高预测精度。
-
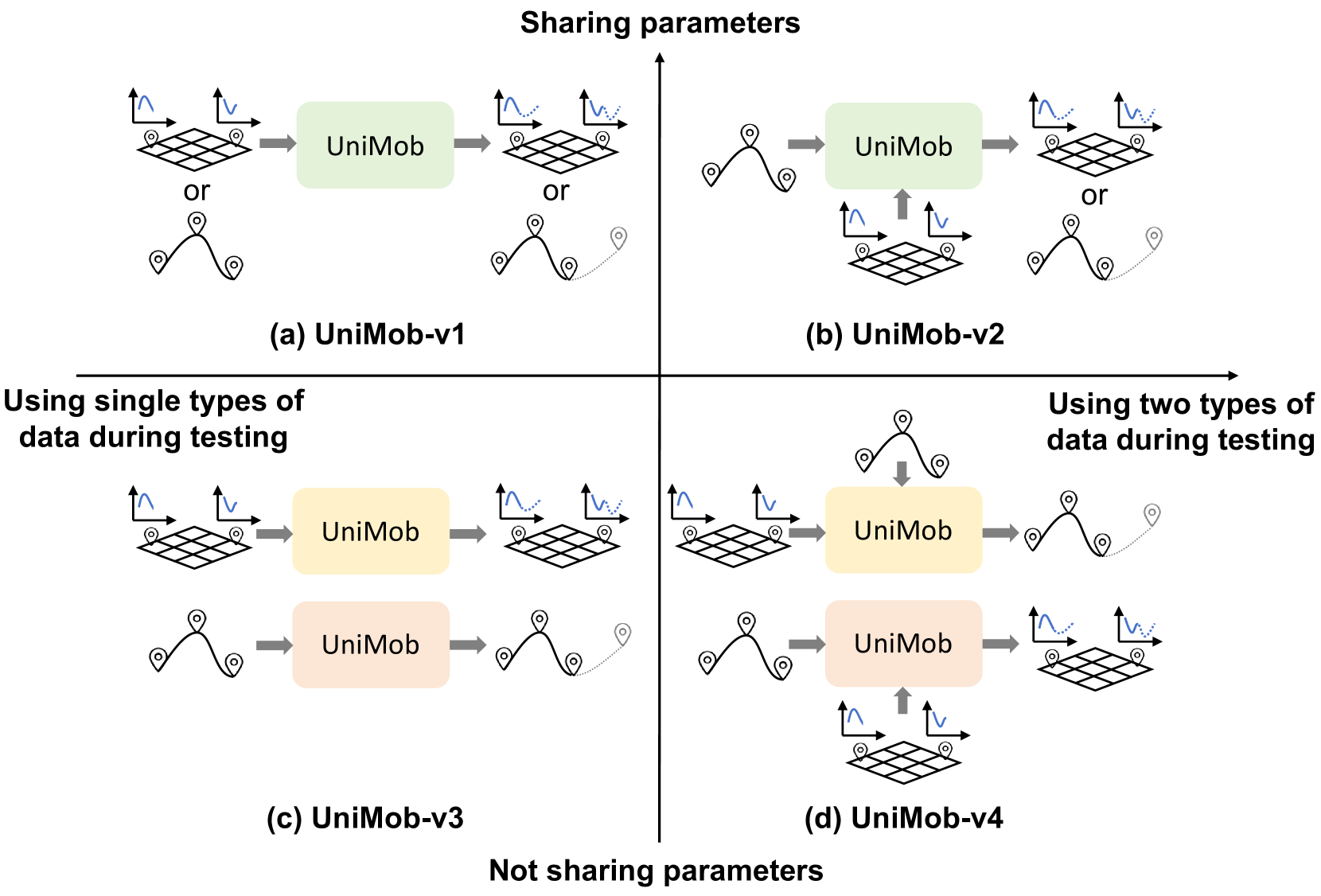
模型变体(Model Variants):
- 设计了四种模型变体,以确保模型能够灵活适应不同的应用场景和需求,包括参数共享和不共享的情况,以及在测试期间是否使用两种类型的移动数据。
Q: 论文做了哪些实验?
A: 论文中进行了以下实验来验证所提出的UniMob模型的性能和有效性:
-
实验设置:
- 使用了三个真实世界的移动数据集,分别是上海、塞内加尔和新疆的数据集,每个数据集都包含轨迹和流量数据。

-
基线比较:
- 与现有的最先进基线模型进行性能比较,包括轨迹预测和移动预测两个方面的模型。
-
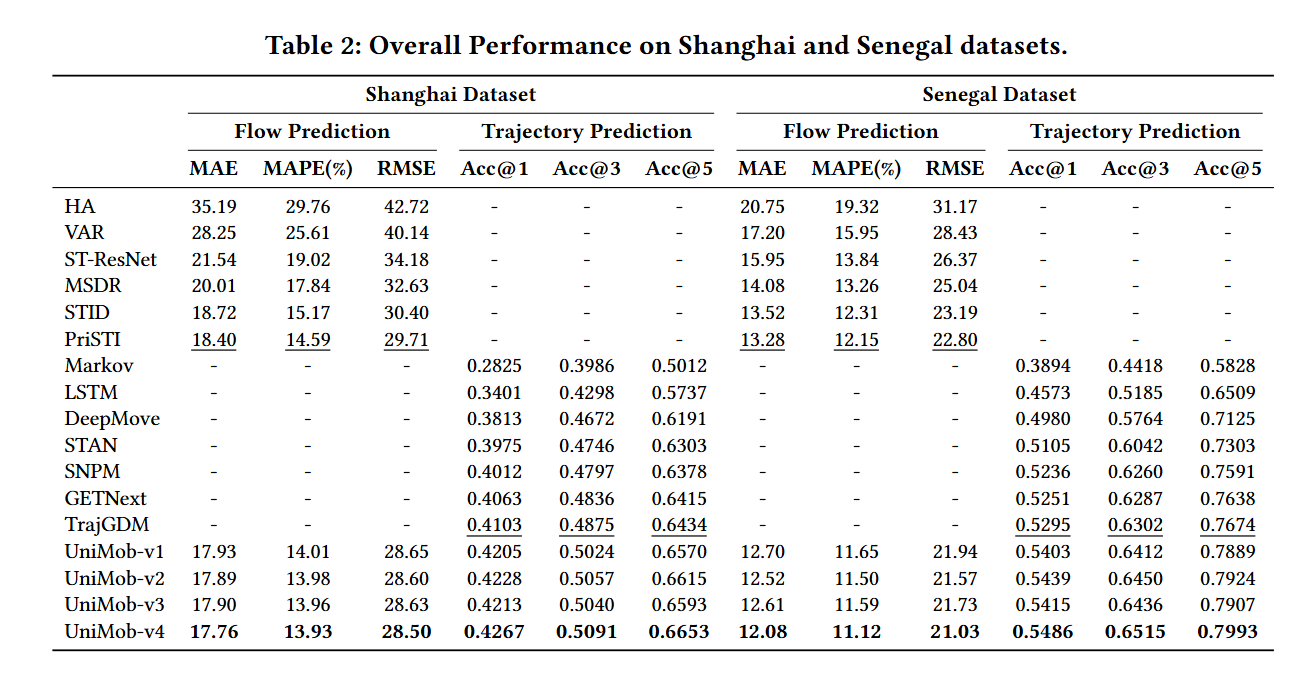
总体性能:
- 在上海和塞内加尔数据集上展示了UniMob模型与基线模型在轨迹和移动预测任务上的性能对比。
- 使用了四个模型变体进行每项任务,并与基线方法进行比较,展示了模型的灵活性和优秀性能。
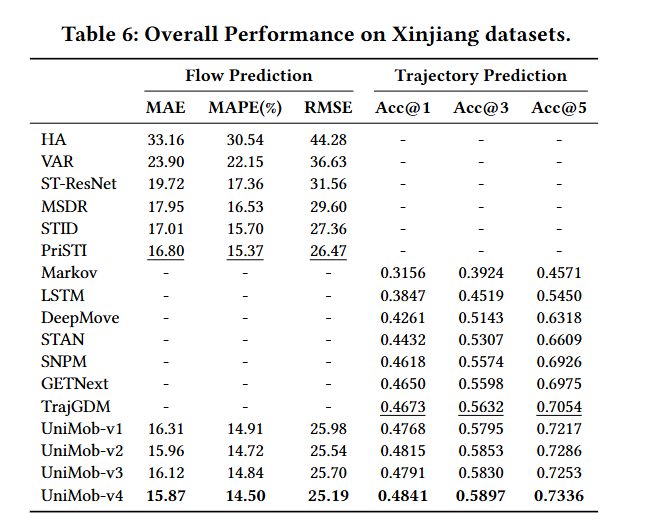
-
消融实验:
- 对模型设计和数据使用进行了消融实验,以评估每个模块对UniMob性能的影响。
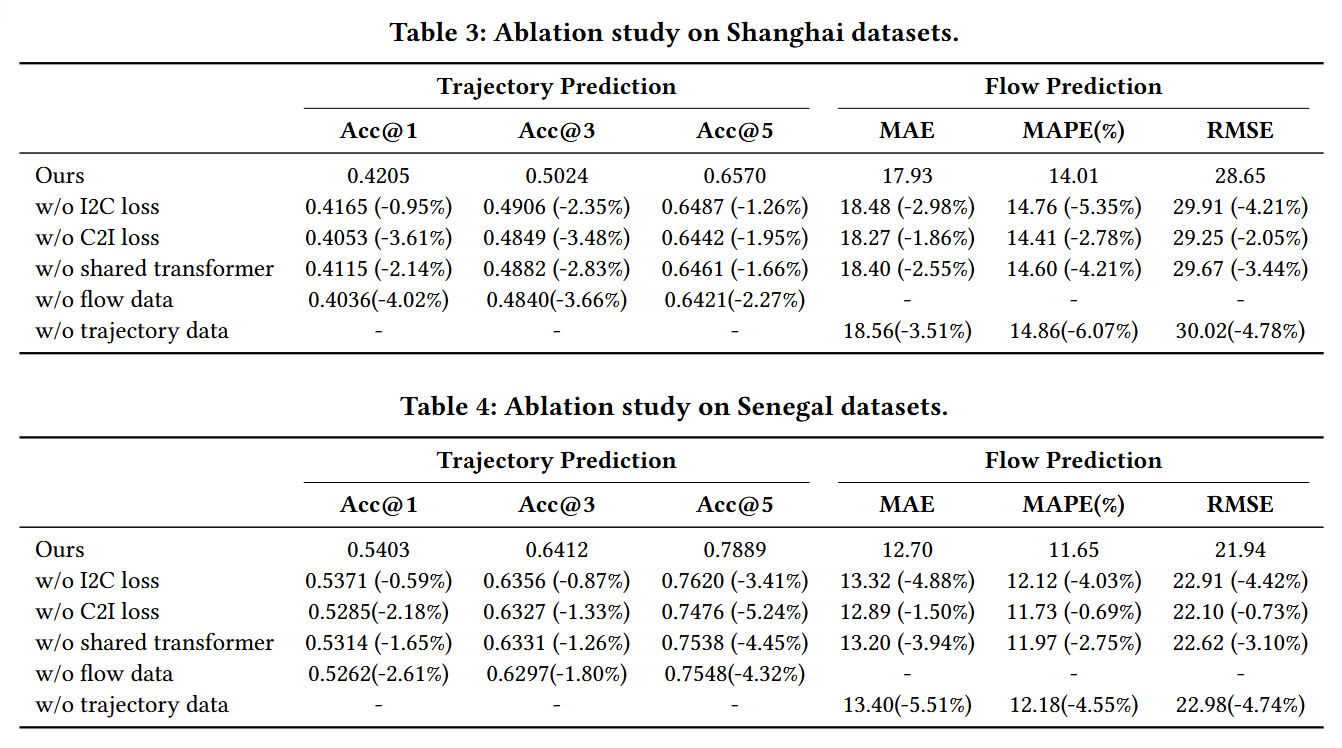
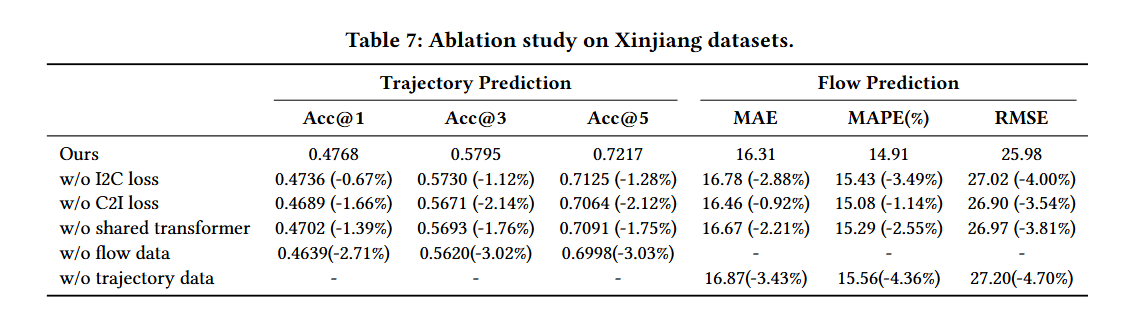
-
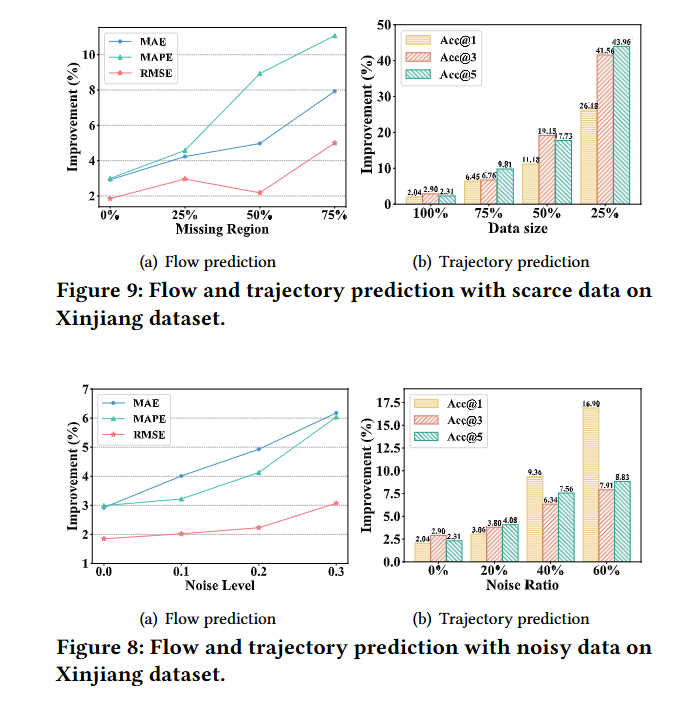
噪声扰动:
- 评估了UniMob模型在数据中添加噪声时的性能,以测试模型对噪声的稳健性。
-
少样本性能:
- 模拟了现实世界中由于隐私问题、数据收集挑战或其他限制而可能存在的数据量有限的情况,并测试了UniMob模型在少量样本数据上的预测性能。
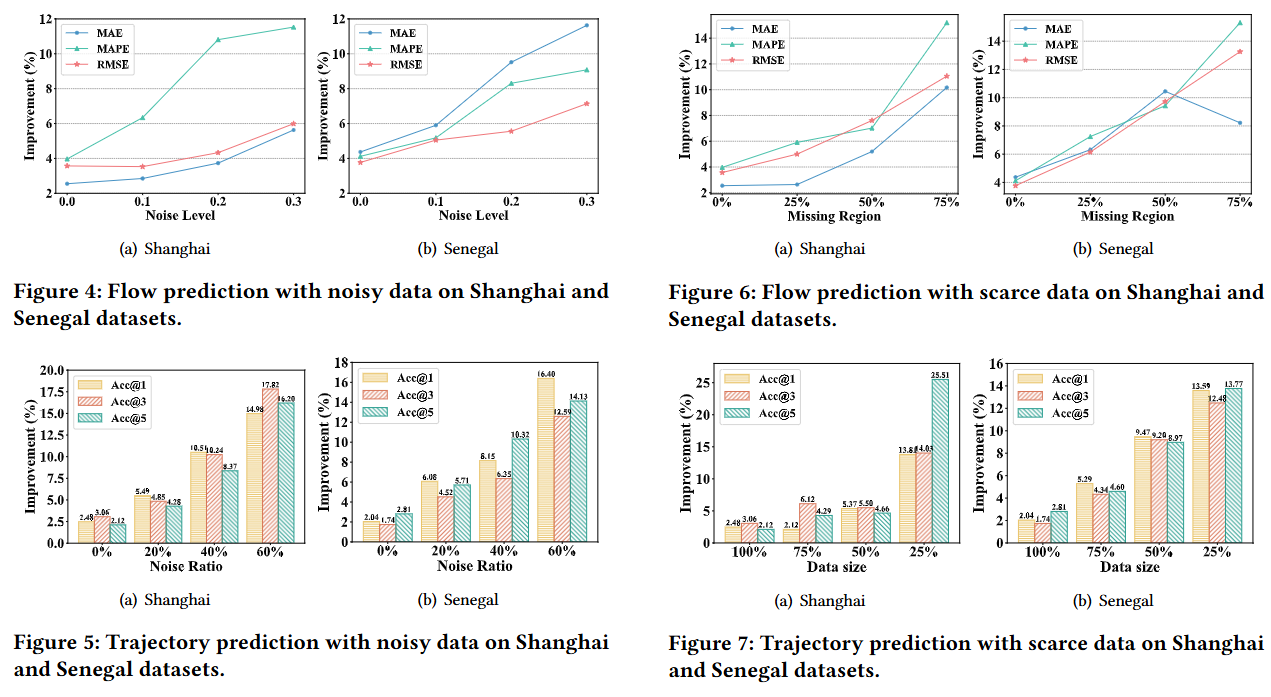
Q: 总结一下论文的主要内容
A: 本文提出了一个名为UniMob的通用人类移动预测模型,旨在突破现有方法在单一任务上的局限性,实现对个体轨迹和群体移动的统一预测。主要内容包括:
- 问题背景:预测人类移动对于城市规划、交通控制和紧急响应等领域至关重要。现有方法受限于单一任务,无法有效整合个体轨迹和群体移动这两种不同模态的移动数据。
- UniMob模型:提出了一个通用的人类移动预测模型UniMob,能够同时处理个体轨迹和群体移动数据。模型利用多视图移动分词器将数据转换为统一格式,并通过扩散变换架构进行建模。此外,引入了双向个体和群体对齐机制来处理两种数据模态之间的特征差异。
- 关键技术:
- 多视图词元化:将轨迹和流量数据转换为统一的时空词元格式。
- 双向对齐机制:包括个体到群体和群体到个体的对齐,以提取共同的时空模式。
- 联合噪声预测器:建模个体移动和群体移动的时空分布。
- 移动预测器:将嵌入转换回原始数据形式,实现准确的预测。
- 实验验证:在真实世界的轨迹和流量数据集上进行了广泛的实验,验证了UniMob在轨迹和移动预测任务上的优越性能。特别是在噪声和数据稀缺的情况下,UniMob显示出比其他基线方法更高的性能提升。
- 模型变体:设计了四种模型变体,以适应不同的应用场景和计算资源限制。
- 未来工作:提出了未来可能的研究方向,包括集成更多城市数据模态、优化模型泛化能力、提高模型解释性等。
总体而言,本文通过提出UniMob模型,为统一人类移动预测提供了一个有效的解决方案,并在实验中展示了其优越的性能和稳健性。
应不同的应用场景和计算资源限制。
6. 未来工作:提出了未来可能的研究方向,包括集成更多城市数据模态、优化模型泛化能力、提高模型解释性等。
总体而言,本文通过提出UniMob模型,为统一人类移动预测提供了一个有效的解决方案,并在实验中展示了其优越的性能和稳健性。
🌟【紧跟前沿】“时空探索之旅”与你一起探索时空奥秘!🚀
欢迎大家关注时空探索之旅时空探索之旅

















 1634
1634

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









