



学习stable diffusion之前,需要先掌握CLIP和VAE两个经典的多模态预训练模型。这两个模型的核心思想纯深度学习风格,相对stable diffusion来说简单很多,以后有机会再写,这里默认已经了解,我们直接进入stable diffusion的学习。 stable diffusion为什么我感觉要更复杂呢?因为它的核心思想是基于机器学习的扩散模型的。但凡涉及机器学习思想的模型都难顶一些,强化学习是这样,扩散模型也是这样。我自己学习的感受就是机器学习算法要比深度学习算法难很多,机器学习往往需要很多数学和统计学方面很多先验知识,经常是基于某某某定理或者什么公式理论的假设,可以自己推不利索,但一定得知道它是用来做什么的。
停止碎碎念,言归正传。学习stable diffusion,我认为应该先放弃模型中复杂又琐碎的代码实现细节,先抓住核心思想(因为这些实现细节很大概率是作者在实现过程中发现的各种小trick,不影响主线思想学习)。随便搜索一下,我们就知道stable diffusion与其说是个模型,不如说是个含扩散模型的架构。因为它包含三大核心组件:CLIP、VAE以及U-NET,其中CLIP和VAE是预训练好的,不参与stable diffusion模型训练的参数更新,也就是模型只更新U-NET(扩散模型)部分。
1、扩散思想在stable diffusion中的应用
用初中物理学习的扩散现象来比喻,扩散模型包含两个关键阶段:
(1)正向扩散过程 (Forward Diffusion Process):逐渐破坏数据(如图像),加入噪声(就像墨水在水中扩散)。
(2)逆向扩散过程 (Reverse Diffusion Process):学习如何从噪声中恢复原始数据(就像让墨水重新聚集成一滴)。
stable diffusion就巧妙利用了这两个阶段。我们想象一下文生图使用场景:用户输入文本,模型输出符合文本内容的图像。

不就像是从一个完全随机的噪点图中,逐渐根据文本信息降噪,最终还原图像吗(逆向扩散过程)?刚才说的是stable diffusion的推理场景,我们一定还疑惑,如何训练呢?我们准备的数据集肯定是标注好的文图对,这种一一对应的文和图怎么在训练中发挥作用(正向扩散过程)?
2、stable diffusion的训练和推理流程简述
(1)模型训练时
先说结论,再解析过程
准备: (文本, 图像) 对。
文本编码:
文本-> CLIP Text Encoder ->text_embeddings。图像编码:
图像-> VAE Encoder -> 干净潜变量z_0。加噪(正向扩散):
随机选择一个时间步
t(1 ≤t≤ T)。根据
t对应的噪声强度,向z_0添加高斯噪声noise-> 带噪潜变量z_t。(公式:
z_t = sqrt(α_t) * z_0 + sqrt(1 - α_t) * noise,其中α_t是噪声调度参数)U-Net 训练(逆向扩散):
输入:
z_t, 时间步t的embedding,text_embeddings。U-Net 内部通过 Cross-Attention 融合文本信息(文本作 K, V;U-Net 特征作 Q)。
输出:预测的噪声
noise_pred。损失:
MSE(noise_pred, noise)。目标是最小化预测噪声与真实添加噪声的差异。
乍一看上面这个流程,估计有2处疑惑:时间步和loss怎么理解。我们把上图里面那个image information creater展开,下面这个图中两个红框框就描述了image information creater做的事情。
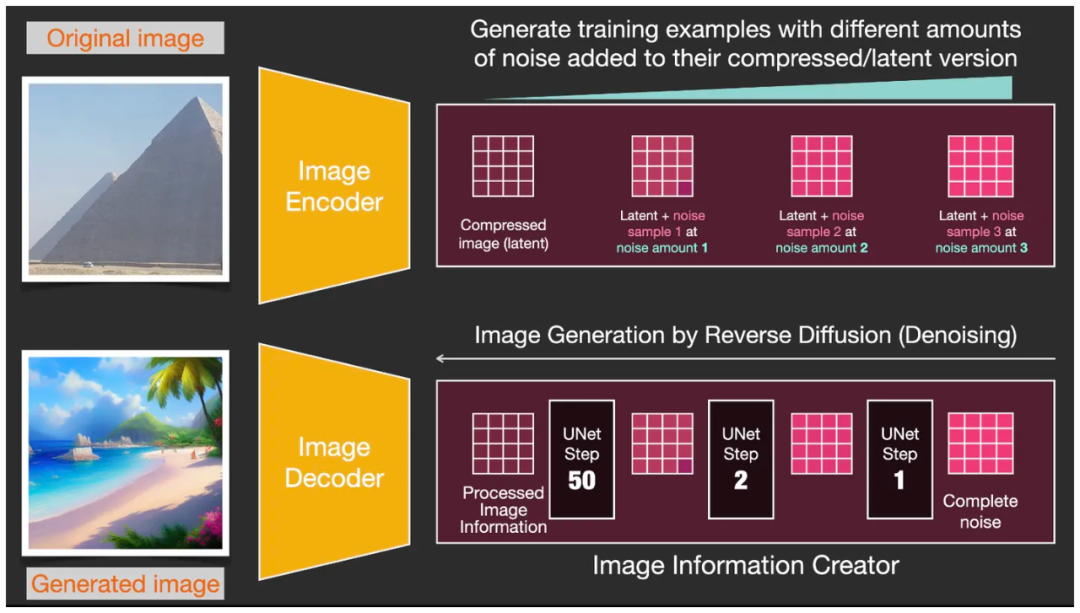
上面是随机的加噪(正向扩散),下面是降噪逆向扩散,需要训练如何根据文本内容降噪,效果类似下图。可以看到图像从随机的噪音一步步变得符合文本内容和真实图像(这里图中的例子不恰当,上面已经是风格迁移的示意图了,原本original image应该和generated image不会差这么多的,没找到合适的示意图)。
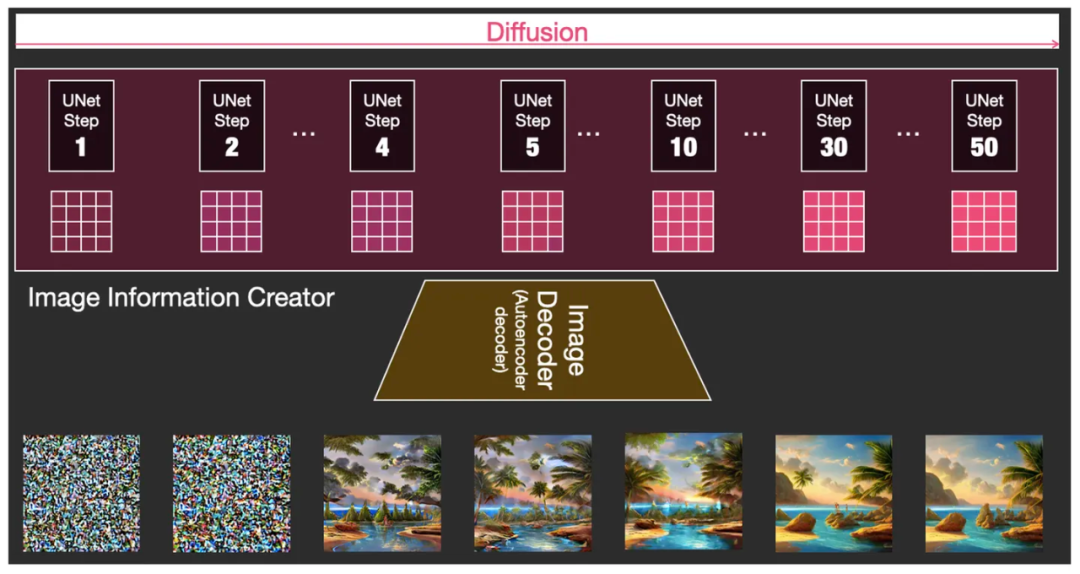
再来说loss,loss并不是衡量原始图和生成图之间的差别。U-net学习的目标是如何降噪,因为是分多步进行降噪的,所以要学习的是每一个时间步t的时候应该降什么噪,loss是衡量加噪和降噪之间的差的,所以是MSE。看上面的图我们大概率会理解为每次都会经过50步的加噪和降噪,实际情况,每次输入给U-net的已经是随机抽样的某一个时间步了,所以输入需要“时间步 t 的embedding”,类似与LLM预训练中的位置向量,得告诉模型现在的加噪程度,才能知道该降多少噪。
(2)模型推理时
输入:
文本-> CLIP Text Encoder ->text_embeddings。起点:随机采样高斯噪声
z_T(对应于最大时间步 T)。迭代去噪 (T 步): 对于
t从 T 到 1:
U-Net 输入:当前带噪潜变量
z_t, 时间步t的嵌入,text_embeddings-> 输出noise_pred。采样器 (如 DDIM, Euler, DPM++) 根据
z_t,noise_pred,t和其算法规则,计算下一步“更干净”的潜变量z_{t-1}。最终得到 去噪潜变量
z_0。- 图像解码:
z_0-> VAE Decoder -> 生成的图像。
这样就完成了快速理解stable diffusion的核心思想。若有训练需求,剩下的就是研究代码实现——过程中常有很多细节技巧,但带着核心思想去理解,就不易迷失在代码细节中。

















 3729
3729

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









