




在当今AI技术飞速发展的时代,HuggingFace已成为开发者不可或缺的工具平台。作为一个专注于提升研发效能的博主,我将带您全面了解这个AI领域的"GitHub",探索它如何帮助开发者事半功倍。
一、开发者为什么要了解HuggingFace?
1.1 什么是HuggingFace?
HuggingFace远不止是一个开源大模型查询平台。它是一个集模型、数据集和AI应用于一体的大型开源AI社区,已成为开源AI模型(尤其是大语言模型)的中心枢纽。许多领先的AI公司和研究人员都会在这里首发他们的最新模型。
更令人兴奋的是,HuggingFace提供了一系列工具和资源,让个人和组织能够探索、使用、训练和部署AI模型,并与更广泛的AI社区协作。想象一下,GitHub之于代码,HuggingFace之于AI模型,这种类比能帮助您理解它的定位。
▎核心价值对比
| 需求 | 传统方案 | HuggingFace方案 |
|---|---|---|
| 获取最新AI模型 | 阅读论文→自己实现 | 直接pip install |
| 模型效果验证 | 搭建测试环境 | 在线Demo即时体验 |
| 企业级部署 | 组建MLOps团队 | Inference API直调 |
1.2 HuggingFace适合哪些人使用?
HuggingFace的用户群体非常广泛:
- AI研究人员和开发者:可以下载模型代码和数据集进行高级定制和开发
- 技术爱好者:能通过"Spaces"功能,仅需点击几下就能运行预构建的AI应用
- 产品经理和设计师:可以快速体验最新AI能力,为产品设计寻找灵感
- 学生和自学者:能够接触到最前沿的AI技术实践案例
无论您是希望将AI集成到项目中的开发者,还是只想了解AI最新进展的观察者,HuggingFace都能为您提供价值。
1.3 HuggingFace的资源是免费的吗?
好消息是,HuggingFace的大部分资源都是免费的!特别是开源模型、数据集和许多"Spaces"应用,您可以自由探索和实验而无需支付任何费用。
但如同许多云平台一样,HuggingFace也提供付费层级,主要针对需要更多计算资源的用户,例如:
- 使用专用GPU进行模型训练
- 托管高性能应用
- 企业级支持和服务
据资料显示,HuggingFace采用freemium模式,基础会员每月仅需9美元,对于大多数个人开发者来说,免费资源已经足够丰富。
二、HuggingFace的三大核心组成部分
理解HuggingFace的平台结构,能帮助开发者更高效地利用其资源:
1. Models(模型库)
这里是超过150万个开源AI模型的宝库,涵盖:
- 自然语言处理(NLP):如BERT、GPT等文本模型
- 计算机视觉(CV):图像分类、目标检测等模型
- 音频处理:语音识别、音乐生成等
- 多模态模型:结合文本、图像等多种输入
每个模型页面通常包含:
- 模型代码
- 使用示例
- 社区讨论
- 相关Spaces演示
- 性能指标和论文链接
开发者可以通过精细筛选找到最适合自己需求的模型。
2. Datasets(数据集)
优质的数据集是训练和微调AI模型的关键。HuggingFace的数据集板块提供:
- 结构化数据浏览
- 数据预览功能
- 部分数据集支持SQL查询
- 数据版本控制
- 预处理脚本
从经典的MNIST到最新的多模态数据集,这里应有尽有。
3. Spaces(应用空间)
这是我最推荐非技术用户首先体验的部分!Spaces是社区构建的交互式AI应用展示平台,特点包括:
- 零代码体验AI能力
- 涵盖图像编辑、文本生成、语音合成等前沿应用
- 可直接嵌入到网站中
- 每个Space都有对应的代码仓库
三、开发者如何高效使用HuggingFace
3.1 如何利用HuggingFace学习和跟踪AI最新趋势?
作为AI领域的风向标,HuggingFace是学习的最佳平台:
- 第一手模型发布:Meta、Google等大厂新模型常在此首发
- 多样化模型体验:通过实际运行理解不同模型的优缺点
- 社区智慧:阅读模型讨论区的技术交流
- 开源代码学习:研究顶尖AI团队的项目结构
- Spaces灵感启发:看看别人如何创意地应用AI模型
建议开发者定期浏览"Trending"标签,发现社区热点。
3.2 如何将HuggingFace项目部署到自己的网站?
许多Space应用都可以轻松迁移:
- 在Space页面找到"Repository"链接(通常指向GitHub)
- 克隆代码库到本地
- 按照README配置环境(通常需要Python和依赖库)
- 本地测试运行
- 使用Docker容器化或直接部署到云服务
即使前端经验有限,也可以借助现代工具如Vercel、Streamlit等快速部署。AI编程助手如Cursor能帮助解决过程中的技术问题。
3.3 非技术人员如何从HuggingFace获益?
对于非技术背景的用户,我建议:
- 直接浏览Spaces板块
- 使用搜索功能寻找感兴趣的应用(如"image edit"、“text generation”)
- 点击"Hosted inference API"体验模型
- 收藏有用的应用,建立个人AI工具库
- 关注创作者,获取更新通知
四、实战案例:HuggingFace的创意应用
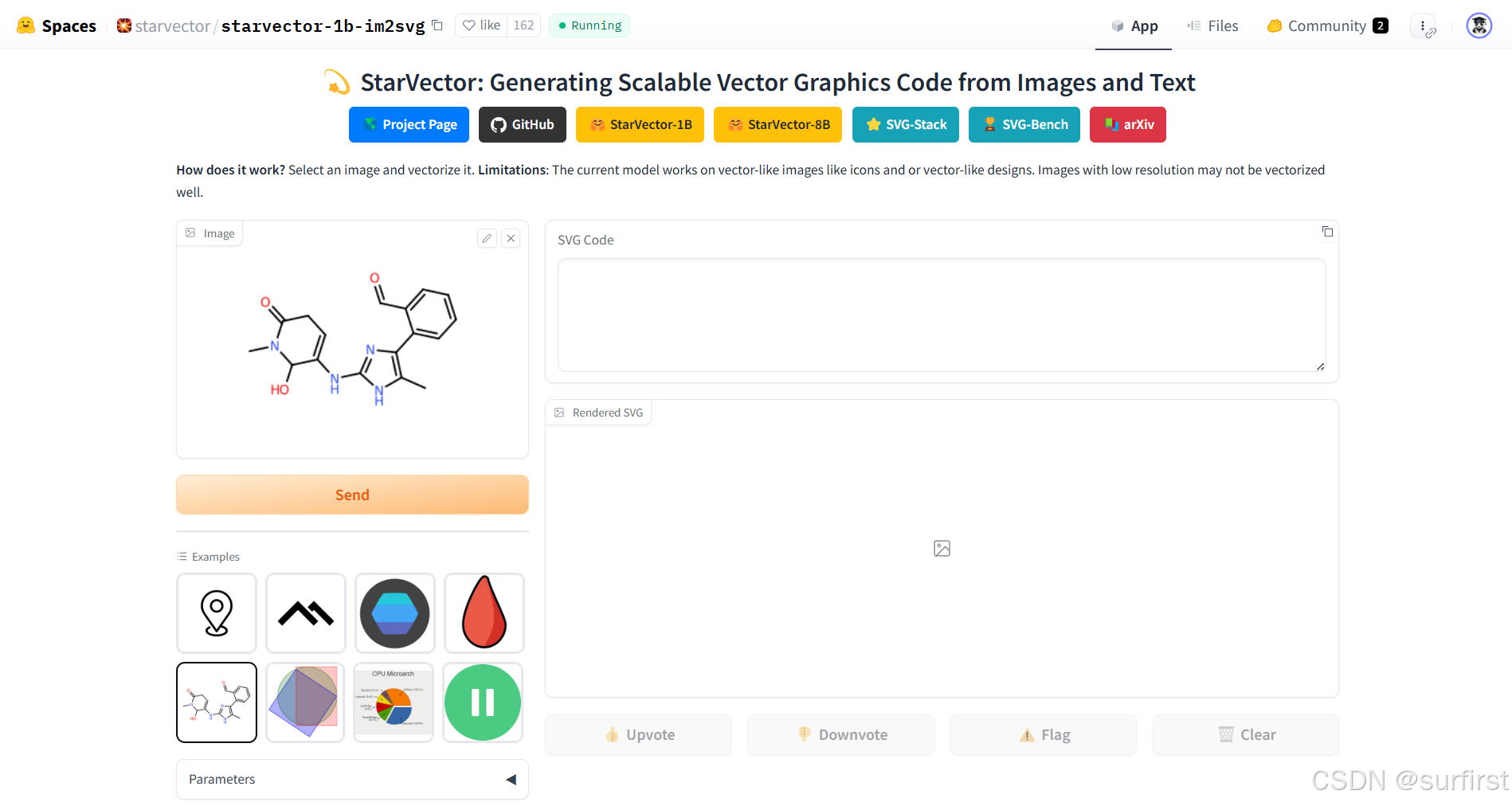
4.1 使用StarVector将图标转换为SVG
项目地址:https://huggingface.co/starvector/starvector-8b-im2svg
在线Demo:https://huggingface.co/spaces/starvector/starvector-1b-im2svg
使用场景:
- 设计师快速获得矢量图初稿
- 制作PPT专业配图
- 将低分辨率logo转换为可无限放大的矢量图
技术限制:
- 输入图片最好是简洁的图标或插图
- 复杂照片效果可能不理想
- 输出SVG可能需要后期调整
代码研究:https://github.com/joanrod/star-vector
这个项目展示了如何将深度学习与计算机图形学结合,开发者可以学习其架构设计。
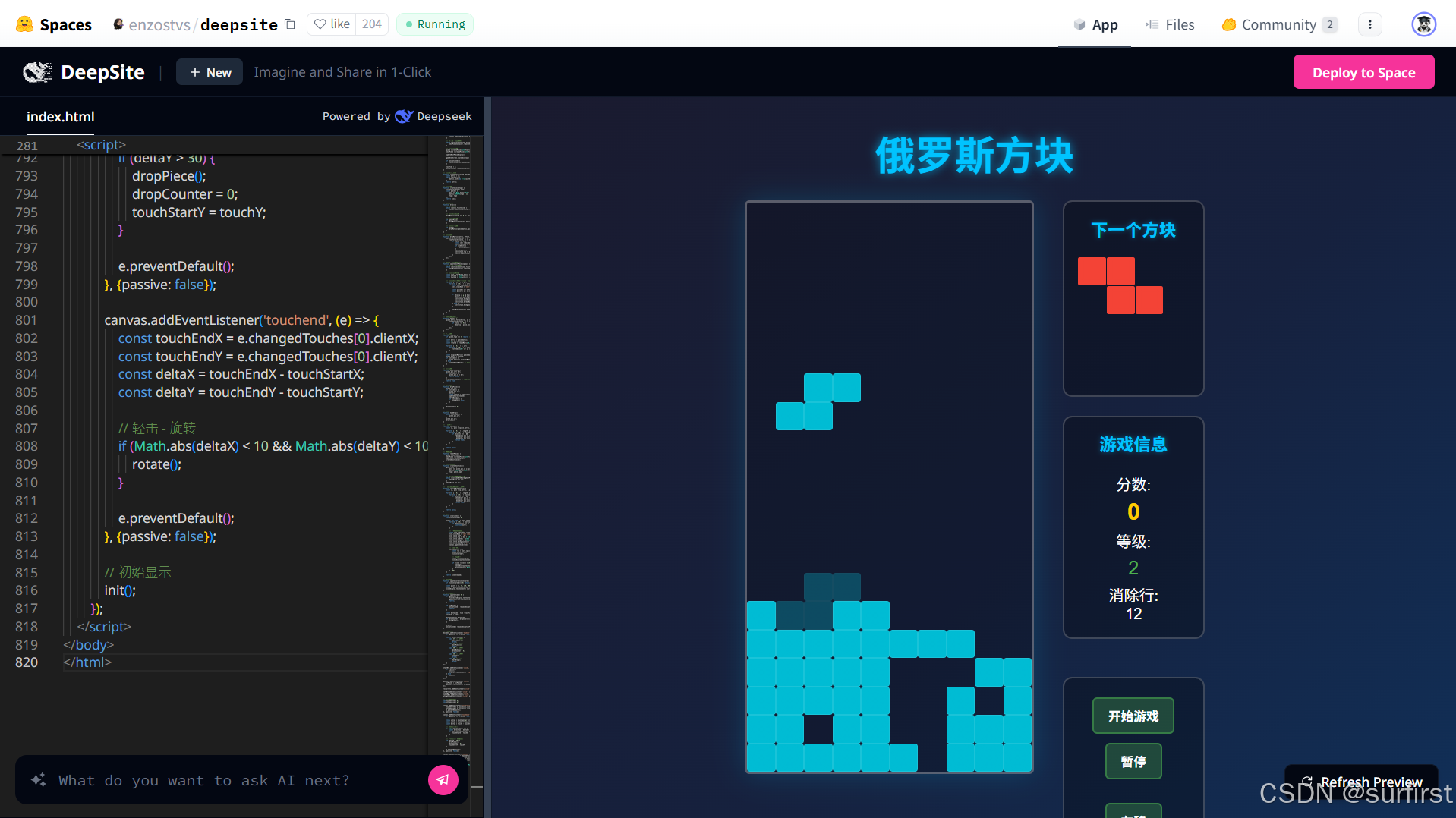
4.2 使用DeepSite自动生成前端代码
项目地址:https://huggingface.co/spaces/enzostvs/deepsite
代码结构:https://huggingface.co/spaces/enzostvs/deepsite/tree/main
惊艳之处:
- 通过自然语言描述生成完整网站
- 支持HTML/CSS/JavaScript输出
- 可导出代码直接使用
开发启示:
- 研究其如何将GPT类模型与代码生成结合
- 学习前端组件化设计思路
- 可以基于此构建自己的低代码平台
五、总结:为什么每个开发者都应该关注HuggingFace
通过本文的探索,我们可以看到HuggingFace已经远远超出了一个简单的模型仓库。它实际上是:
- AI开发者的军火库:提供从模型到部署的全套工具
- 技术趋势的晴雨表:最新AI进展在这里最先体现
- 创意实现的加速器:Spaces展示了无限可能
- 学习成长的大学校:通过开源项目提升AI能力
无论您是希望快速集成AI能力到现有项目,还是想深入AI模型开发,亦或是寻找创业灵感,HuggingFace都能提供强大支持。我的建议是:立即注册一个账号,从浏览Trending模型开始您的HuggingFace之旅!
行动号召:您最近在HuggingFace发现过什么有趣的项目吗?欢迎在评论区分享您的发现和使用体验!对于想深入了解某个特定功能的读者,也可以留言告诉我,我可能会在后续文章中详细解析。





















 1793
1793

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











