




Retrieval Augmented Generation(RAG) 是现代生成式 AI 应用的重要技术之一。本文将结合理论和实际案例,详细解析优化 RAG 系统的有效方法,为开发者提供从概念到实践的全面指导。
1. 什么是 RAG 以及开发 RAG 应用所面临的挑战
1.1 什么是 Retrieval Augmented Generation (RAG)?
RAG 是一种结合大语言模型(LLM)和知识库的技术,通过以下两个步骤实现增强生成:
- 检索相关信息:基于用户查询,从知识库中提取相关文档。
- 上下文生成:利用检索到的信息作为上下文,为用户生成连贯且信息丰富的回答。
这种方法能够动态扩展模型知识范围,提升响应的准确性和实用性。
1.2 RAG 应用面临的主要挑战
尽管 RAG 技术优势明显,但开发过程中也面临以下挑战:
- 数据质量:知识库中的错误或不完整数据会直接影响系统响应的可靠性。
- 检索效率:如何确保检索结果相关性强、数量适中。
- 生成准确性:避免生成内容中的“幻觉”(虚构信息)。
- 可扩展性:应对大规模并发用户时保持系统性能。
- 安全性和合规性:特别是在处理敏感信息时,需确保数据安全并符合法律法规。
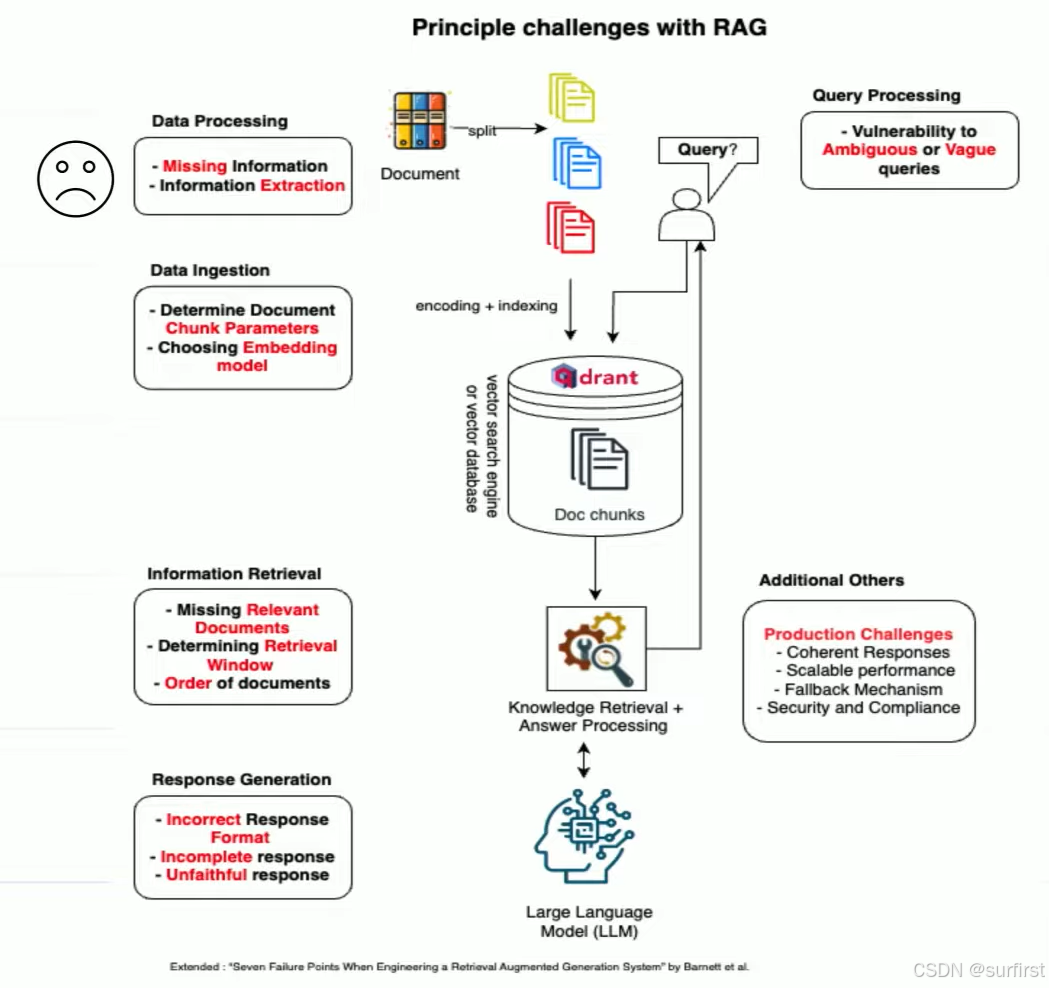
2. 通过迭代优化 RAG 应用的 5 个步骤
为提升 RAG 系统的性能,推荐采用以下迭代步骤:
- 从基线开始:搭建简单的初始系统,快速验证核心功能。
- 使用合适的指标评估:明确性能指标,如相关性、真实性和生成质量等。
- 分析数据并识别问题:通过评估结果,发现系统表现不足之处。
- 提出假设并开展实验:设计实验验证优化策略。
- 持续迭代:根据实验结果,不断调整并改进系统。
3. 优化 RAG 应用的度量指标及优化技巧
以下是常见的 RAG 系统优化指标及相应技巧:
3.1 上下文相关性(Context Relevance)
- 定义:检索的文档是否包含回答问题所需的信息。
- 优化技巧:
- 扩大检索窗口,增加相关信息的覆盖范围。
- 使用重新排序技术过滤低质量文档。
- 混合检索结合稀疏和密集向量,提升特定领域术语的检索效果。
3.2 切块相关性(Chunk Relevance)
- 定义:检索信息中有用内容的比例。
- 优化技巧:
- 调整切块策略,找到平衡相关性和上下文的最佳切块大小。
- 采用语义切块,确保分块信息的连贯性和实用性。
3.3 真实性(Faithfulness)
- 定义:生成内容是否忠实于检索信息,避免出现虚构内容。
- 优化技巧:
- 优化检索过程,减少幻觉的可能性。
- 实现文档重新排序以优先考虑高可信度内容。
3.4 文本质量(Text Quality)
- 定义:生成内容的流畅性、一致性和语法正确性。
- 优化技巧:
- 使用高质量的 LLM 并进行任务微调。
- 通过提示词设计(如链式推理)改善生成逻辑。
4. 案例分析:基于 Quadrant 和 Quo 的迭代优化过程
以下是一个使用 Quadrant 向量数据库和 Quo 评估平台构建 RAG 问答系统的案例时间轴。
Phase 1: 初始实现
- 系统搭建:基于 Quadrant 实现简单的 RAG 系统,使用其文档作为知识库。
- 初始实验:
- 使用 Mistral Instruct LLM 和固定检索窗口。
- 进行切块策略测试(小块与大块对比)。
Phase 2: 迭代优化
- 结果评估:通过 Quo 分析实验结果,发现增加块大小虽然提供更多上下文,但会降低生成真实性。
- 调整方案:
- 采用较小的块大小,同时扩大检索窗口。
- 测试新的嵌入模型和 LLM(如 GPT-3.5)。
- 改进效果:检索相关性和真实性大幅提高,生成质量也明显改善。
Phase 3: 针对问题的深度优化
- 问题分析:通过具体数据点,发现检索对领域术语支持不足。
- 优化方案:
- 使用混合检索(稀疏与密集向量结合)。
- 测试多种重新排序模型(如 Cohere 和 ColBERT)。
- 最终成果:混合检索结合 Cohere 的重新排序模型后,系统真实性从 76% 提升至 85%。
5. 总结
通过科学评估和迭代优化,RAG 系统可以显著提升性能。在实际开发中,关键是:
- 数据驱动的迭代优化流程。
- 结合领域知识和用户需求设计实验。
- 根据指标精准分析并实施针对性改进。
通过案例可以看出,优化是一个动态过程,需要不断调整策略和工具组合。希望本文为开发者提供清晰的优化思路,使 RAG 技术为更多领域的生成式 AI 应用赋能。


















 298
298

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











