







 本文详细介绍了 Hadoop 2.7.3 的部署过程。首先说明了准备工作,包括软件版本、绑定 IP 和修改计算机名、JDK 安装与配置。接着阐述 Hadoop 部署,涵盖安装、配置多个文件,最后介绍启动步骤,格式化文件系统、启动 hadoop,通过浏览器访问验证搭建成功。
本文详细介绍了 Hadoop 2.7.3 的部署过程。首先说明了准备工作,包括软件版本、绑定 IP 和修改计算机名、JDK 安装与配置。接着阐述 Hadoop 部署,涵盖安装、配置多个文件,最后介绍启动步骤,格式化文件系统、启动 hadoop,通过浏览器访问验证搭建成功。
作者:夕阳
1 准备
1.1 软件版本
hadoop2.7.3
1.2 绑定 IP 和修改计算机名
1.2.1 修改/etc/hosts,添加 IP 绑定

1.2.2 修改/etc/hostname,为绑定计算机名。(计算机名和上面 hosts 绑定名必须一致)
1.3 JDK 安装
下载jdk1.8软件包,放到/opt 下解压
1.3.1 将 JDK 环境变量配置到/etc/profile 中
export JAVA_HOME=/opt/jdk
export JRE_HOME=/opt/jdk/jre
export CLASSPATH=$ JAVA_HOME/lib:$ JRE_HOME/lib
export PATH=$ JAVA_HOME/bin:$ PATH
1.3.2 检查 JDK 是否配置好
source /etc/profile
java -version
2 Hadoop 部署
2.1 Hadoop 安装
解压 hadoop2.7.3软件包 ,并在主目录下创建 tmp、dfs、dfs/name、dfs/node、dfs/data
2.2 Hadoop 配置
以下操作都在 hadoop-2.7.3/etc/hadoop 下进行
2.2.1 编辑 hadoop-env.sh 文件,修改 JAVA_HOME 配置项为 JDK 安装目录
export JAVA_HOME=/opt/jdk
2.2.2 编辑 core-site.xml 文件,添加以下内容,其中 master 为计算机名,/opt/hadoop-2.7.3/tmp 为手动创建的目录
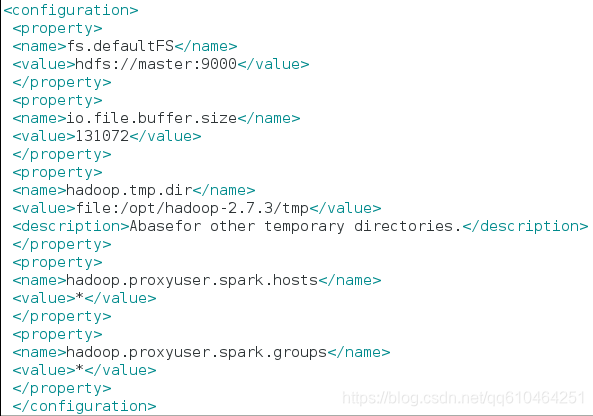
2.2.3 编辑hdfs-site.xml文件,添加以下内容 其中master为计算机名,file:/opt/hadoop-2.7.3/dfs/name和file:/opt/hadoop2.7.3/dfs/data 为手动创建目录
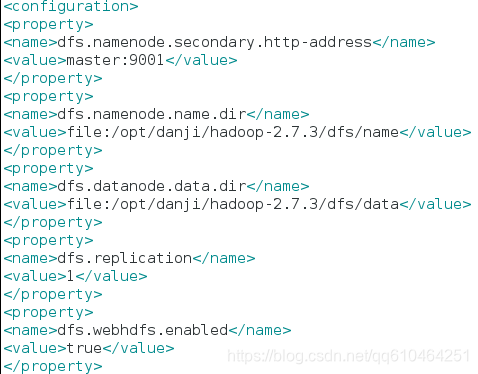
2.2.4 将mapred-site.xml.template重命名为mapred-site.xml,编辑mapred-site.xml文件,添加以下内容其中master为计算机名

2.2.5 编辑yarn-site.xml文件,添加以下内容其中master为计算机名

2.2.6 修改slaves文件

2.3 Hadoop启动
2.3.1. 格式化一个新的文件系统,进入到hadoop-2.7.3/bin下执行:
./hadoop namenode -format
2.3.2. 启动hadoop,进入到hadoop-2.7.3/sbin下执行:
./start-all.sh
2.3.3. 打开浏览器输入ip:50070能访问则搭建成功

















 4074
4074

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









