




 本文介绍了如何使用深度优先搜索(DFS)的递归方法实现二叉树的后序遍历。在给定的代码示例中,展示了前序、中序和后序遍历的不同顺序,并提供了后序遍历的具体实现,其时间复杂度为O(n)。
本文介绍了如何使用深度优先搜索(DFS)的递归方法实现二叉树的后序遍历。在给定的代码示例中,展示了前序、中序和后序遍历的不同顺序,并提供了后序遍历的具体实现,其时间复杂度为O(n)。
二叉树的后序遍历_牛客题霸_牛客网 (nowcoder.com)
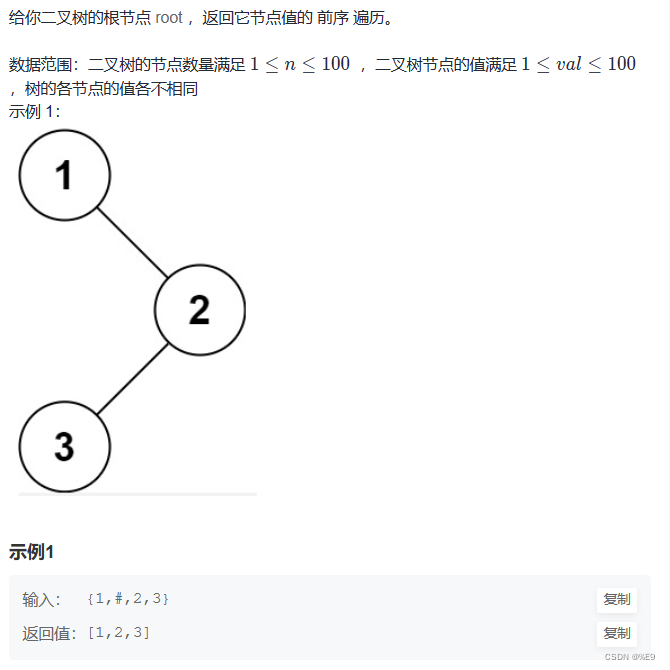
前序、后续、中序遍历原理相似
利用dfs算法 递归去做
/**
* struct TreeNode {
* int val;
* struct TreeNode *left;
* struct TreeNode *right;
* TreeNode(int x) : val(x), left(nullptr), right(nullptr) {}
* };
*/
class Solution {
public:
/**
* 代码中的类名、方法名、参数名已经指定,请勿修改,直接返回方法规定的值即可
*
*
* @param root TreeNode类
* @return int整型vector
*/
void dfs(vector<int> &res, TreeNode* root){
if(root == nullptr) return ;
/* 前序
res.push_back(root->val);
dfs(res,root->left);
dfs(res,root->right);
*/
/* 中序
dfs(res,root->left);
res.push_back(root->val);
dfs(res,root->right);
*/
/* 后序
dfs(res,root->left);
dfs(res,root->right);
res.push_back(root->val);
*/
}
vector<int> preorderTraversal(TreeNode* root) {
// write code here
vector<int> res;
dfs(res, root);
return res;
}
};需要遍历所有节点,时间复杂度On

















 372
372

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









