








SQL经典案例之按字符串顺序排列字符串中的字符
问题描述
将字符串按照字符顺序从左到右进行排序
--排序前-- >>>> ---排序后---
OLD_NAME NEW_NAME
--------- >>>> ----------
DB2 2BD
GAUSSDB ABDGSSU
MONGODB BDGMNOO
MYSQL LMQSY
ORACLE ACELOR
POSTGRESQL EGLOPQRSST
SQLSERVER EELQRRSSV
TIDB BDIT
--------- >>>> ----------
处理逻辑:先将字符串拆分成单个字符,再将各个字符按所在字符串(分组)进行排序
构造测试数据
drop table t_string;
create table t_string(tid int,tname varchar(10));
insert into t_string values(1,'ORACLE');
insert into t_string values(2,'MYSQL');
insert into t_string values(3,'POSTGRESQL');
insert into t_string values(4,'SQLSERVER');
insert into t_string values(5,'DB2');
insert into t_string values(6,'GAUSSDB');
insert into t_string values(7,'TIDB');
insert into t_string values(8,'MONGODB');
-- tid的个数需要 >= tname列的数据最大长度
drop table t_10;
create table t_10(tid int);
insert into t_10 values(1);
insert into t_10 values(2);
insert into t_10 values(3);
insert into t_10 values(4);
insert into t_10 values(5);
insert into t_10 values(6);
insert into t_10 values(7);
insert into t_10 values(8);
insert into t_10 values(9);
insert into t_10 values(10);
commit;
Oracle
函数 SYS_CONNECT_BY_PATH 能以迭代的方式创建列表,主要用于树查询(层次查询) 以及多列转行,其语法一般为:
select ... sys_connect_by_path(column_name,'connect_symbol') from table
start with ... connect by ... prior
完整语句:取分组长度一致的那个数据即排好序的字符串
col old_name format a15
col new_name format a15
select old_name, new_name
from (
select old_name,replace(sys_connect_by_path(c,' '),' ') as new_name
from (
select t.tname as old_name,
row_number() over(partition by t.tname order by substr(t.tname,iter.pos,1)) rn,
substr(t.tname,iter.pos,1) c
from t_string t,
(select rownum as pos from t_10) iter
where iter.pos <= length(t.tname) order by 1
) x
start with rn = 1
connect by prior rn = rn-1 and prior old_name = old_name
) where length(old_name) = length(new_name);

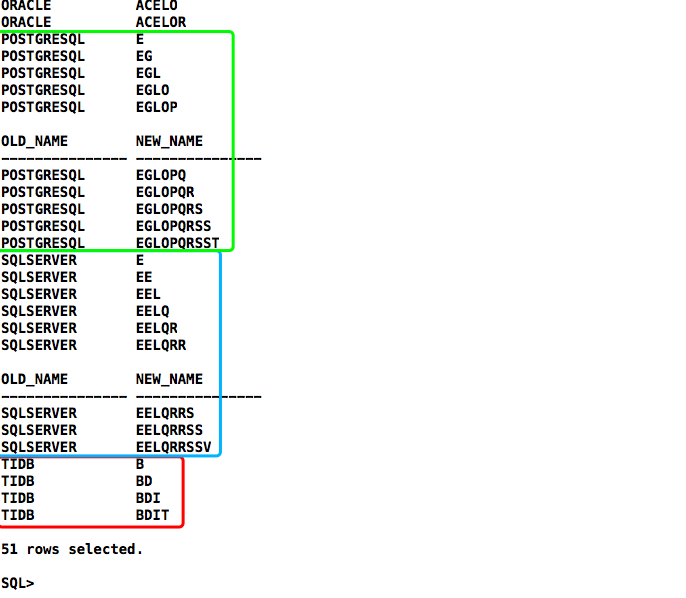
拆解:将拆分的单个字符排序拼接起来
select old_name,replace(sys_connect_by_path(c,' '),' ') as new_name
from (
select t.tname as old_name,
row_number() over(partition by t.tname order by substr(t.tname,iter.pos,1)) rn,
substr(t.tname,iter.pos,1) c
from t_string t,
(select rownum as pos from t_10) iter
where iter.pos <= length(t.tname) order by 1
) x
start with rn = 1
connect by prior rn = rn-1 and prior old_name = old_name;
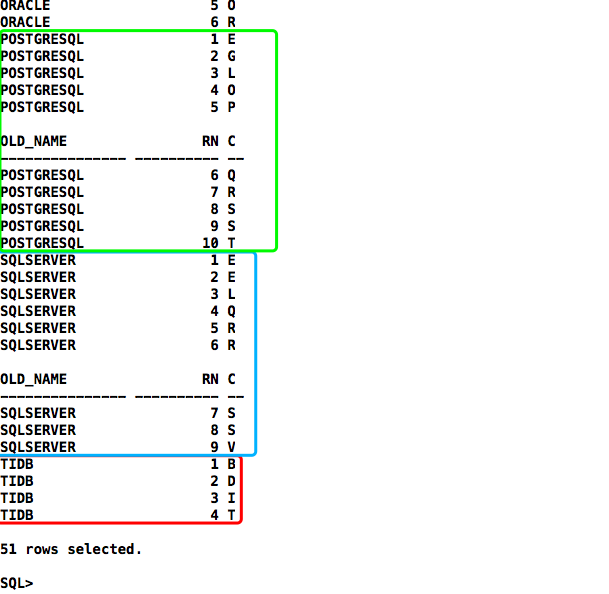
拆解:最内层,按row_number排序拆分字符串为单个字符
select t.tname as old_name,
row_number() over(partition by t.tname order by substr(t.tname,iter.pos,1)) rn,
substr(t.tname,iter.pos,1) c
from t_string t,
(select rownum as pos from t_10) iter
where iter.pos <= length(t.tname) order by 1;
MySQL
GROUP_CONCAT:不仅能进行拼接,还能进行排序,默认逗号分隔,可用separator指定分隔符,语法如下:
group_concat([DISTINCT] 要连接的字段 [Order BY ASC/DESC 排序字段] [Separator '分隔符'])
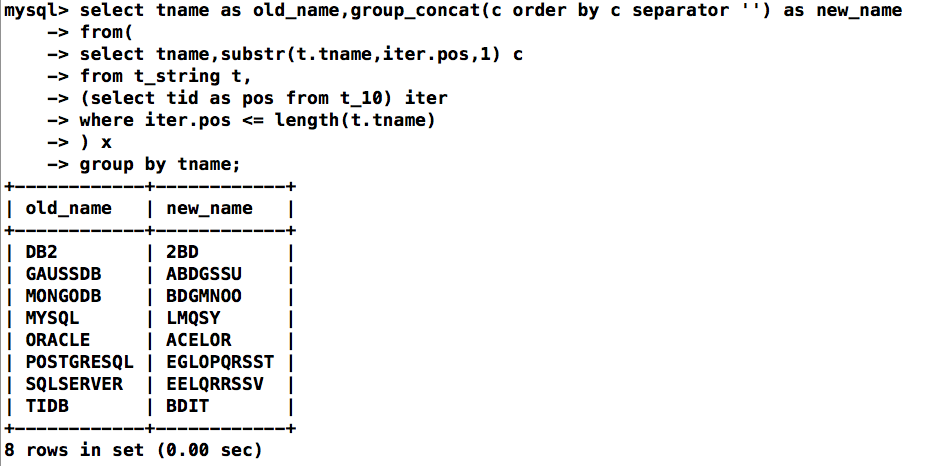
完整语句:将拆分的字符排序后进行拼接
select tname as old_name,group_concat(c order by c separator '') as new_name
from(
select tname,substr(t.tname,iter.pos,1) c
from t_string t,
(select tid as pos from t_10) iter
where iter.pos <= length(t.tname)
) x
group by tname;
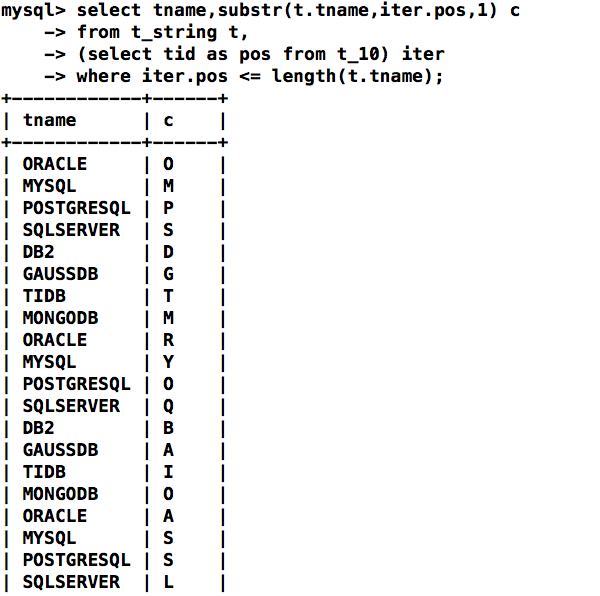
拆解:将字符串拆分成单个字符(乱序)
select tname,substr(t.tname,iter.pos,1) c
from t_string t,
(select tid as pos from t_10) iter
where iter.pos <= length(t.tname);
PostgreSQL
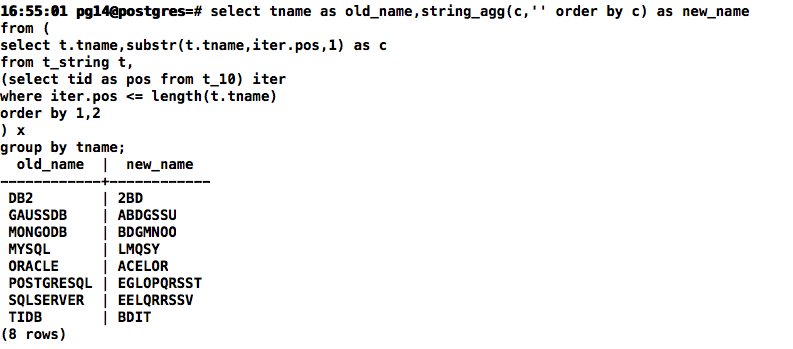
STRING_AGG:对字符串进行排序
select tname as old_name,string_agg(c,'' order by c) as new_name
from (
select t.tname,substr(t.tname,iter.pos,1) as c
from t_string t,
(select tid as pos from t_10) iter
where iter.pos <= length(t.tname)
order by 1,2
) x
group by tname;
拆解:将字符串拆分成单个字符再进行排序
select t.tname,substr(t.tname,iter.pos,1) as c
from t_string t,
(select tid as pos from t_10) iter
where iter.pos <= length(t.tname)
order by 1,2;


















 1190
1190

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









