




Python爬虫-Scrapy框架(二)- 交互式命令模式
写在前面
在交互式命令模式这一部分主要介绍了对Scrapy的爬取功能进行测试,以及一些简单命令的使用,包括如何创建一个Scrapy项目。在这一篇文章中主要是介绍一些基本命令的使用,在代码方面讲解较少,重点还是放在后面的章节。
交互式命令模式
使用shell命令
我们可以进入Scrapy交互式命令模式对要爬取的页面进行测试,查看获取到的内容。我们在命令行程序中使用命令 scrapy shell https://blog.youkuaiyun.com/sunzhihao_future 来进入交互模式,即 scrapy shell后面追加要爬取的网址 。
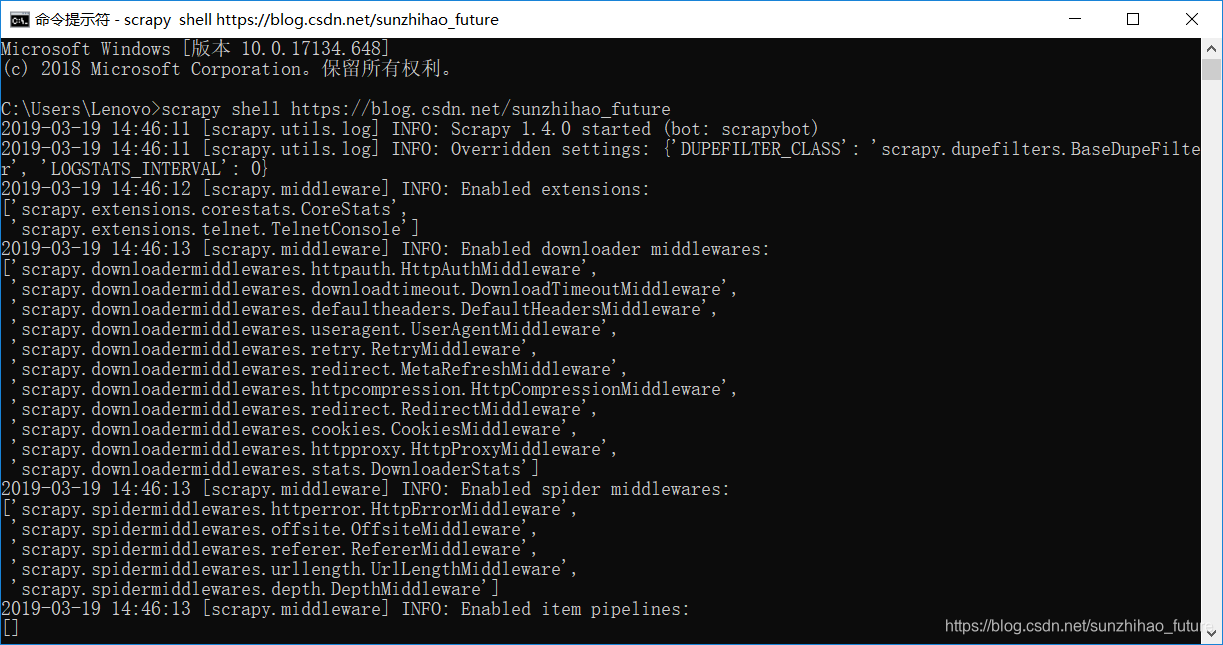
成功打开后,会进入下图所示的交互命令模式。类似于python,可以直接输入要执行的命令。
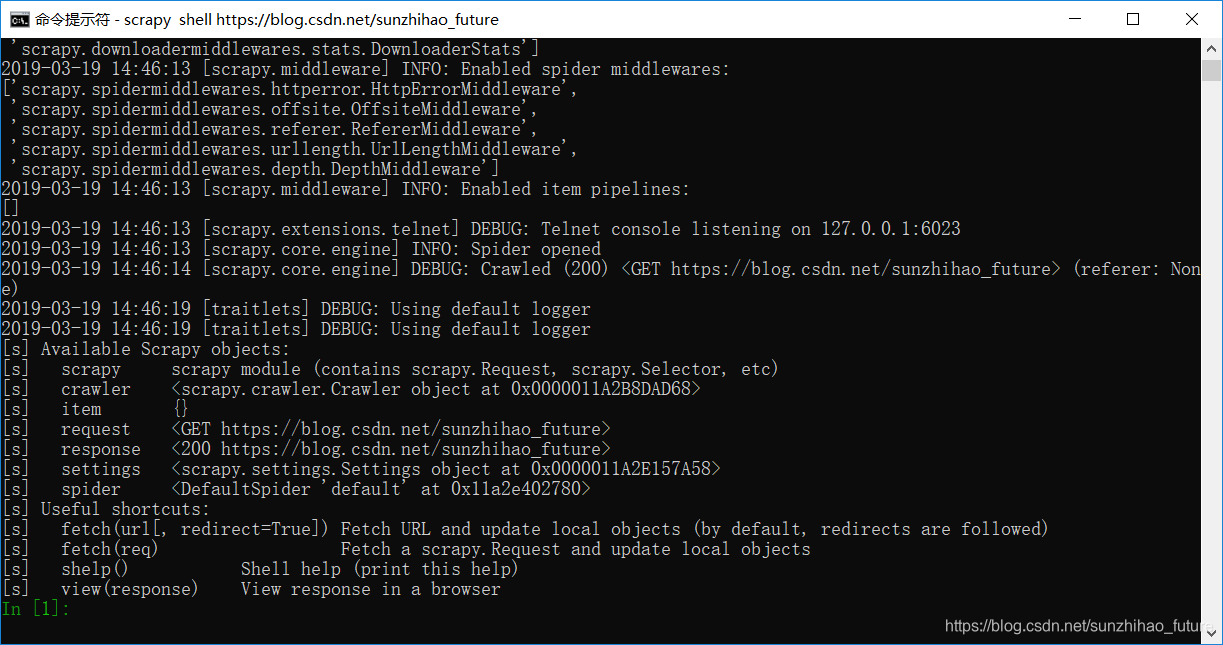
在上述shell命令执行的过程中,打开了指示的链接,将爬取的内容保存到了response变量。可以通过命令 response 来查看保存的变量。
通过命令 view(response) 来查看获取到的具体的数据,即response中的内容。
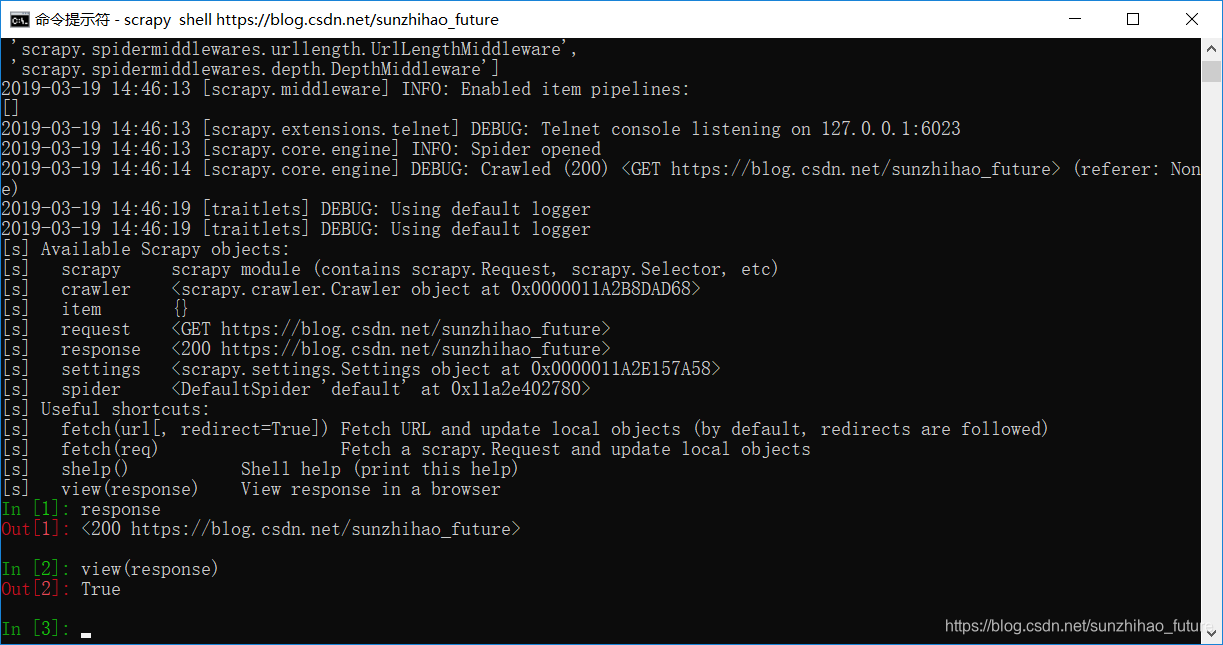
终端在收到view(response)命令后,会调用系统默认的浏览器显示爬取到的数据,如下图所示。
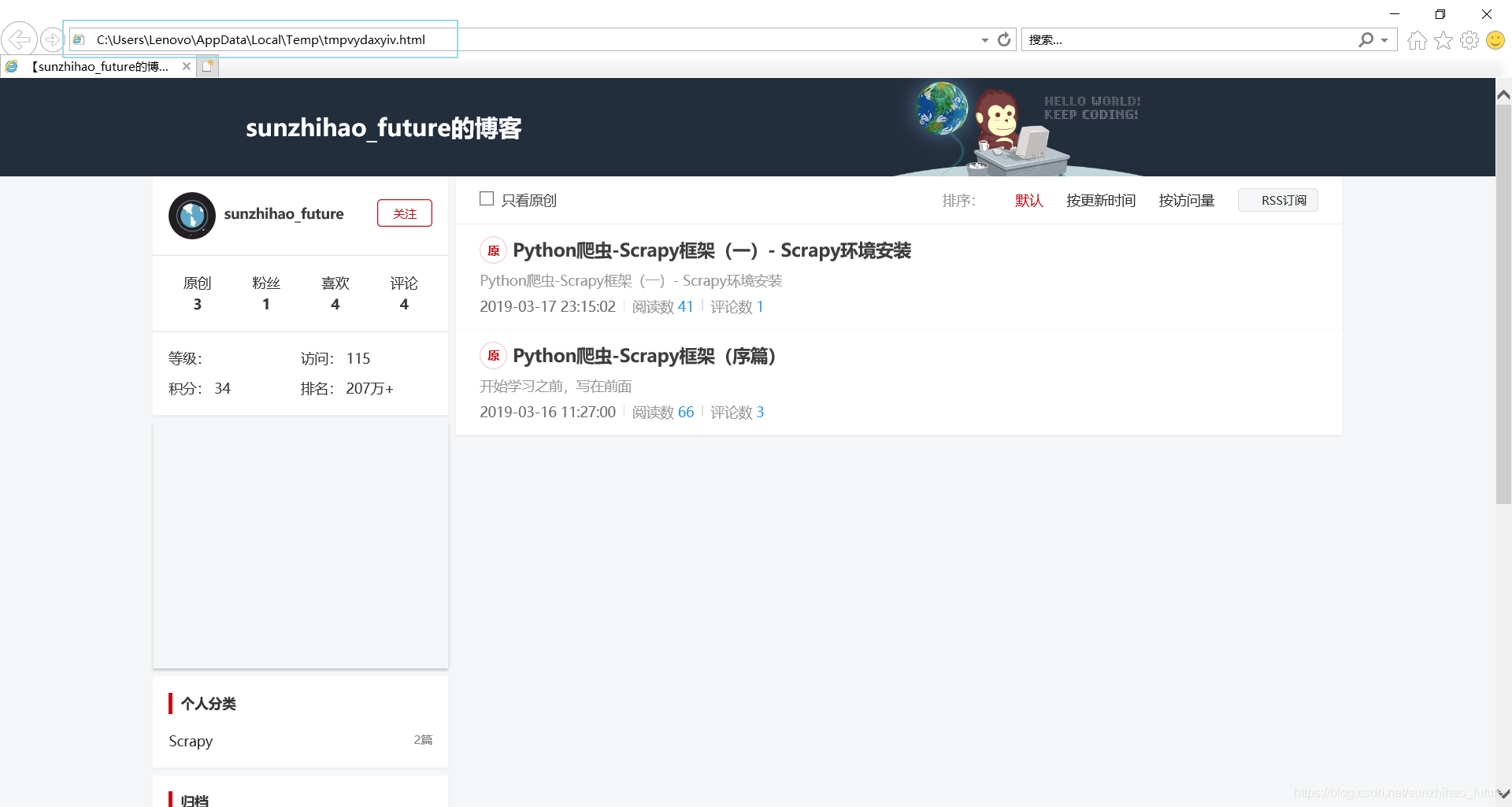
查看地址栏不难发现,新打开的页面是一个存储在本地的临时文件,与原网页进行对比,内容大致相同。
XPath Helper插件安装与使用
XPath即XML路径语言(XML Path Language),是一种用来确定XML文档中某部分位置的语言。之前利用Firefox浏览器中的FireBug开发者插件可以很方便的获取某个元素的路径,但是很遗憾,在2017年底,FireBug制作团队宣布停止继续维护,因此在最新版的Firefox浏览器中已经找不到这一款扩展程序了。
XPath Helper安装
XPath Helper是Chrome浏览器的扩展程序,提供了类似于FireBug的获取元素路径的功能,和FireBug相比,存在一些不足,但是对于初学者来说,可以暂时用来获取HTML元素的XPath路径。
由于不能很方便的直接访问Google服务器,因此我们可以提前下载XPath Helper离线安装文件,然后打开Chrome浏览器的扩展程序管理页面,将下载好的离线安装文件拖入即可安装。
这里考虑到版权问题,没有直接给出链接,如果没有找到离线安装文件,可以直接评论留言或者发送电邮至 sunzhihao_future@nuaa.edu.cn ,可以直接分享一下。
XPath Helper使用
在启用了XPath Helper后,我们可以通过Ctrl + Shift + X来打开XPath Helper的操作页面。
如果想要获取某个HTML元素的XPath路径,可以通过
 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章


















 376
376

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









