



下面这几款在阿里云常见到的 NVIDIA GPU(L20、A10、V100、P100、P4、T4)+“GRID(vGPU)虚拟化”可以这样区分——看架构代际、显存/带宽、是否主打训练还是推理/视频/图形、以及是否支持切片虚拟化。
怎么选(按你的常见需求)
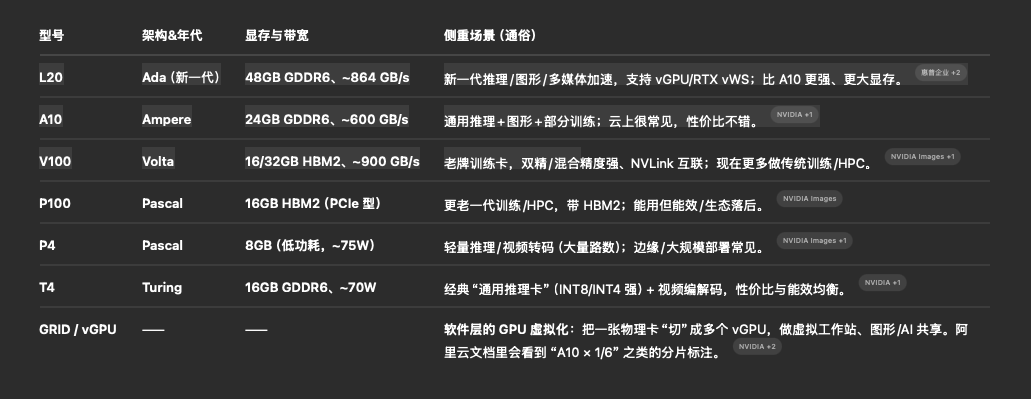
• 大模型推理/高并发、还要做图形或视频:优先 L20(Ada,48GB,带宽更高、AV1 编解码更多路);A10 次之。L20 也在 NVIDIA vGPU/RTX vWS 体系内被官方支持。
• 传统训练/HPC 或需要 NVLink 的多卡互联:历史上 V100 很合适(HBM2、NVLink),但已属上一代;预算允许可考虑更新的 Ada/Hopper 家族。
• 大规模低功耗推理/视频转码:T4(16GB/70W) 比 P4(8GB/75W) 综合更强、更灵活,INT8/INT4 非常吃香。
• 更老的 P100:能用,但生态与能效落后,除非库存/价格特别友好,不建议新购。
• 需要多人/多租户共享一张卡:用 vGPU/GRID(RTX vWS) 方案;在阿里云的 vGPU 实例规格表里,能看到“某型号 × 1/6、1/8”等切片数,表示每台实例拿到的 vGPU 份额。
阿里云相关小贴士
• 阿里云的 gn/vgn 系列会标出底层 GPU 型号 & 切片;例如文档里的 “NVIDIA A10 × 1/6” 就是把一张 A10 切成 6 份分配。近一代的 gn8v 家族面向大模型训练/推理,新款规格会引入 L20。



















 3876
3876

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言











