




 这篇博客分享了如何利用神经网络DNN算法来构建风控领域的信用评分卡模型。作者基于拍拍贷提供的数据集,介绍了数据来源及关键字段,并提供了主程序和功能模块的相关信息,适合对风控建模和机器学习感兴趣的学习者参考。
这篇博客分享了如何利用神经网络DNN算法来构建风控领域的信用评分卡模型。作者基于拍拍贷提供的数据集,介绍了数据来源及关键字段,并提供了主程序和功能模块的相关信息,适合对风控建模和机器学习感兴趣的学习者参考。
【博客地址】:https://blog.youkuaiyun.com/sunyaowu315
【博客大纲地址】:https://blog.youkuaiyun.com/sunyaowu315/article/details/82905347
数据集介绍:
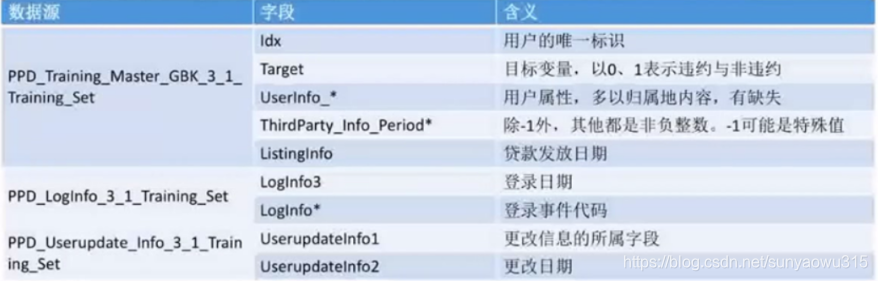
本次案例分析所用的数据,是拍拍贷发起的一次与信贷申请审核工作相关的竞赛数据集。其中共有3份文件:
- PPD_Training_Master_GBK_3_1_Training_Set.csv :信贷用户在拍拍贷上的申报信息和部分三方数据信息,以及需要预测的目标变量。
- PPD_LogInfo_3_1_Training_Set : 信贷客户的登录信息
- PPD_Userupdate_Info_3_1_Training_Set :部分客户的信息修改行为
建模工作就是从上述三个文件中对数据进行加工,提取特征并且建立合适的模型,对贷后表现做预测。
关键字段
对数据分析、机器学习、数据科学、金融风控等感兴趣的小伙伴,需要数据集、代码、行业报告等各类学习资料,可关注微信公众号:风控圏子(别打错字,是圏子,不是圈子,算了直接复制吧!)

关注公众号后,可联系圈子助手加入我们的机器学习风控讨论群和反欺诈讨论群。(记得要备注喔!)
相互学习,共同成长。
主程序
import pandas as pd
import datetime
import collections
import numpy as np
import numbers
import random
import sys
_path = r'C:\Users\A3\Desktop\DNN_scorecard'
sys.path.append(_path)
import pickle
from sklearn.model_selection import train_test_split
from sklearn.metrics import roc_auc_score
from importlib import reload
from matplotlib import pyplot as plt
import operator
reload(sys)
#sys.setdefaultencoding( "utf-8")
# -*- coding: utf-8 -*-
### 对时间窗口,计算累计产比 ###
def TimeWindowSelection(df, daysCol, time_windows):
'''
:param df: the dataset containg variabel of days
:param daysCol: the column of days
:param time_windows: the list of time window
:return:
'''
freq_tw = {
}
for tw in time_windows:
freq = sum(df[daysCol].apply(lambda x: int(x<=tw)))
freq_tw[tw] = freq
return freq_tw
def DeivdedByZero(nominator, denominator):
'''
当分母为0时,返回0;否则返回正常值
'''
if denominator == 0:
return 0
else:
return nominator*1.0/denominator
#对某些统一的字段进行统一
def ChangeContent(x):
y = x.upper()
if y == '_MOBILEPHONE':
y = '_PHONE'
return y
def MissingCategorial(df,x):
missing_vals = df[x].map(lambda x: int(x!=x))
return sum(missing_vals)*1.0/df.shape[0]
def MissingContinuous(df,x):
missing_vals = df[x].map(lambda x: int(np.isnan(x)))
return sum(missing_vals) * 1.0 / df.shape[0]
def MakeupRandom(x, sampledList):
if x==x:
return x
else:
randIndex = random.randint(0, len(sampledList)-1)
return sampledList[randIndex]
def Outlier_Dectection(df,x):
'''
:param df:
:param x:
:return:
'''
p25, p75 = np.percentile(df[x], 25),np.percentile(df[x], 75)
d = p75 - p25
upper, lower = p75 + 1.5*d, p25-1.5*d
truncation = df[x].map(lambda x: max(min(upper, x), lower))
return truncation
############################################################
#Step 0: 数据分析的初始工作, 包括读取数据文件、检查用户Id的一致性等#
############################################################
folderOfData = 'C:/Users/A3/Desktop/DNN_scorecard/'
data1 = pd.read_csv(folderOfData+'PPD_LogInfo_3_1_Training_Set.csv', header = 0)
data2 = pd.read_csv(folderOfData+'PPD_Training_Master_GBK_3_1_Training_Set.csv', header = 0,encoding = 'gbk')
data3 = pd.read_csv(folderOfData+'PPD_Userupdate_Info_3_1_Training_Set.csv', header = 0)
#将数据集分为训练集与测试集
all_ids = data2['Idx']
train_ids, test_ids = train_test_split(all_ids, test_size=0.3)
train_ids = pd.DataFrame(train_ids)
test_ids = pd.DataFrame(test_ids)
data1_train = pd.merge(left=train_ids,right = data1, on='Idx', how='inner')
data2_train = pd.merge(left=train_ids,right = data2, on='Idx', how='inner')
data3_train = pd.merge(left=train_ids,right = data3, on='Idx', how='inner')
data1_test = pd.merge(left=test_ids,right = data1, on='Idx', how='inner')
data2_test = pd.merge(left=test_ids,right = data2, on='Idx', how='inner')
data3_test = pd.merge(left=test_ids,right = data3, on='Idx', how='inner')
#############################################################################################
# Step 1: 从PPD_LogInfo_3_1_Training_Set & PPD_Userupdate_Info_3_1_Training_Set数据中衍生特征#
#############################################################################################
# compare whether the four city variables match
data2_train['city_match'] = data2_train.apply(lambda x: int(x.UserInfo_2 == x.UserInfo_4 == x.UserInfo_8 == x.UserInfo_20),axis = 1)
del data2_train['UserInfo_2']
del data2_train['UserInfo_4']
del data2_train['UserInfo_8']
del data2_train['UserInfo_20']
### 提取申请日期,计算日期差,查看日期差的分布
data1_train['logInfo'] = data1_train['LogInfo3'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
data1_train['Listinginfo'] = data1_train['Listinginfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y-%m-%d'))
data1_train['ListingGap'] = data1_train[['logInfo','Listinginfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)
### 提取申请日期,计算日期差,查看日期差的分布
'''
使用180天作为最大的时间窗口计算新特征
所有可以使用的时间窗口可以有7 days, 30 days, 60 days, 90 days, 120 days, 150 days and 180 days.
在每个时间窗口内,计算总的登录次数,不同的登录方式,以及每种登录方式的平均次数
'''
time_window = [7, 30, 60, 90, 120, 150, 180]
var_list = ['LogInfo1','LogInfo2']
data1GroupbyIdx = pd.DataFrame({
'Idx':data1_train['Idx'].drop_duplicates()})
for tw in time_window:
data1_train['TruncatedLogInfo'] = data1_train['Listinginfo'].map(lambda x: x + datetime.timedelta(-tw))
temp = data1_train.loc[data1_train['logInfo'] >= data1_train['TruncatedLogInfo']]
for var in var_list:
#count the frequences of LogInfo1 and LogInfo2
count_stats = temp.groupby(['Idx'])[var].count().to_dict()
data1GroupbyIdx[str(var)+'_'+str(tw)+'_count'] = data1GroupbyIdx['Idx'].map(lambda x: count_stats.get(x,0))
# count the distinct value of LogInfo1 and LogInfo2
Idx_UserupdateInfo1 = temp[['Idx', var]].drop_duplicates()
uniq_stats = Idx_UserupdateInfo1.groupby(['Idx'])[var].count().to_dict()
data1GroupbyIdx[str(var) + '_' + str(tw) + '_unique'] = data1GroupbyIdx['Idx'].map(lambda x: uniq_stats.get(x,0))
# calculate the average count of each value in LogInfo1 and LogInfo2
data1GroupbyIdx[str(var) + '_' + str(tw) + '_avg_count'] = data1GroupbyIdx[[str(var)+'_'+str(tw)+'_count',str(var) + '_' + str(tw) + '_unique']].\
apply(lambda x: DeivdedByZero(x[0],x[1]), axis=1)
data3_train['ListingInfo'] = data3_train['ListingInfo1'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))
data3_train['UserupdateInfo'] = data3_train['UserupdateInfo2'].map(lambda x: datetime.datetime.strptime(x,'%Y/%m/%d'))
data3_train['ListingGap'] = data3_train[['UserupdateInfo','ListingInfo']].apply(lambda x: (x[1]-x[0]).days,axis = 1)
collections.Counter(data3_train['ListingGap'])
hist_ListingGap = np.histogram(data3_train['ListingGap'])
hist_ListingGap = pd.DataFrame({
'Freq':hist_ListingGap[0],'gap':hist_ListingGap[1][1:]})
hist_ListingGap['CumFreq'] = hist_ListingGap['Freq'].cumsum()
hist_ListingGap['CumPercent'] = hist_ListingGap['CumFreq'].map(lambda x: x*1.0/hist_ListingGap.iloc[-1]['CumFreq'])
'''
对 QQ和qQ, Idnumber和idNumber,MOBILEPHONE和PHONE 进行统一
在时间切片内,计算
(1) 更新的频率
(2) 每种更新对象的种类个数
(3) 对重要信息如IDNUMBER,HASBUYCAR, MARRIAGESTATUSID, PHONE的更新
'''
data3_train['UserupdateInfo1'] = data3_train['UserupdateInfo1'].map(ChangeContent)
data3GroupbyIdx = pd.DataFrame({
'Idx':data3_train['Idx'].drop_duplicates()})
time_window = [7, 30, 60, 90, 120, 150, 180]
for tw in time_window:
data3_train['TruncatedLogInfo'] = data3_train['ListingInfo'].map(lambda x: x + datetime.timedelta(-tw))
temp = data3_train.loc[data3_train['UserupdateInfo'] >= data3_train['TruncatedLogInfo']]
#frequency of updating
freq_stats = temp.groupby(['Idx'])['UserupdateInfo1'].count().to_dict()
data3GroupbyIdx['UserupdateInfo_'+str(tw)+'_freq'] = data3GroupbyIdx['Idx'].map(lambda x: freq_stats.get(x,0))
# number of updated types
Idx_UserupdateInfo1 = temp[['Idx','UserupdateInfo1'] 最低0.47元/天 解锁文章
最低0.47元/天 解锁文章

















 3539
3539

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









