




(1)概述
为了解决现有目标检测算法无法检测交通场景图像中所有障碍物的问题,提出了一种新的YOLOSEG策略,用于铁路越界者的智能道路分割和障碍物检测。首先对Unet进行训练,对列车可能前进的铁路轨道区域进行智能分割,然后将生成的区域掩码引入到目标检测网络中,用于识别掩码区域内的障碍物。列车前方出现障碍物的真实视频难以记录,因此将驾驶员视角拍摄的交通场景与各种障碍物随机结合,创建涵盖各种铁路交通场景和照明条件的合成训练数据集,并同时自动生成标签文件。在此基础上,提出了一种用于数据集增强的随机亮度策略。通过FLOPs、Top-1 Accuracy和mAP@0.5/%的性能评估比较,基于合成数据集和真实图像的大量侵入者检测实验验证了所提出方法的准确性和有效性。
(2)贡献
大多数基于深度学习技术的目标检测算法都会检测图像中的所有障碍物。然而,铁路场景中的许多物体并不会对火车构成真正的危险。检测所有物体会浪费计算资源,并增加误识别的风险。一些研究采用了设置固定识别区域的算法,下图(a)所示形状和位置固定的梯形区域适合于图(b)所示直线区域的铁路越轨者检测。但铁路轨道并不总是简单的直线。对于图(c)和(d)所示的纵横交错的铁路轨道区域,设置固定识别区域的方法并不适用于复杂的路况。

因此,本文基于机器视觉和深度学习技术,研究了具有复杂纵横轨道的自主铁路的两个关键挑战。一项任务是对铁路轨道的区域进行智能分段,另一项任务是仅在列车可能沿着纵横交错的铁路轨道移动的可能区域检测闯入者。提出了一种新颖的策略YOLOSEG,其贡献有三个方面:
- 1. 对于输入图像,首先训练Unet进行轨迹区域分割,然后将生成的掩码引入YOLO网络作为交通障碍物的检测区域,以便只检测位于列车可能沿其移动的可能区域内的障碍物。
- 2. 将从互联网上收集的驾驶员视角拍摄的交通场景图像与各种障碍物随机结合,创建一个合成数据集,由丰富的车站、田野、桥梁、隧道等铁路交通场景组成,覆盖多种照明条件。并且在创建图像文件的同时,自动生成智能网络训练所需的标签文件。此外,提出了一种随机亮度训练策略用于数据增强,以确保更好的效率与精度之间的权衡。
- 3. 通过FLOPs、Top-1、Accuracy和mAP@0.5/%的性能评估比较,基于合成数据集和真实图像的大量入侵检测实验验证了所提出方法的准确性和有效性。
(3)方法
1)数据集生成
背景图像:本文利用来自互联网的100个公开可用的铁路视频,将驾驶员视角拍摄的交通视频转换成图像序列作为铁路背景。这些视频在白天和夜间拍摄,并包括可能的道路和天气条件。我们的合成数据集由车站、田野、桥梁、隧道等丰富的铁路交通场景组成,涵盖了多种照明条件。
前景图像:本文采用Unet23作为分割算法获取障碍物(动物、植物、车辆和火车等)。
图像生成:对前景图像和背景图像进行像素级替换,通过随机改变每个背景中擅闯者的位置、数量和大小,生成包含8000张图像的合成铁路擅闯者数据集。
标签文件的创建:我们数据集的背景图像和障碍物图像的参数是可以调整和计算的,所以在生成合成图像的同时,编写python代码生成YOLO模型训练所需的txt格式的标签文件。
2)轨道区域分割
首先进行道路分割,使用标注软件LabelMe对交通障碍物的检测区域进行标注,分为两类:无道岔的轨道和有三路道岔的轨道。图像标注完成后,LabelMe输出一个JSON文件,在此基础上生成黑白二值图像作为掩码图像。

3)侵入者检测
本方法用于检测铁路轨道区域上的入侵者,而不是检测整张图像中的所有目标。核心思想是先通过图像分割的方法,把图像中属于铁路轨道的部分提取出来,然后只在这个区域内进行目标检测。这样可以避免检测到与列车运行无关的目标(例如轨道旁的人或物体),从而提高检测的准确性和效率。具体来说,对于输入图像,首先应用训练好的Unet进行道路分割,得到掩码图像,其中道路为白色,其他区域为黑色,其中RGB空间值为零。将掩码图像引入YOLOSEG(体系结构如下图所示),选择白色道路区域作为待检测区域,其他区域的RGB空间值均为零。
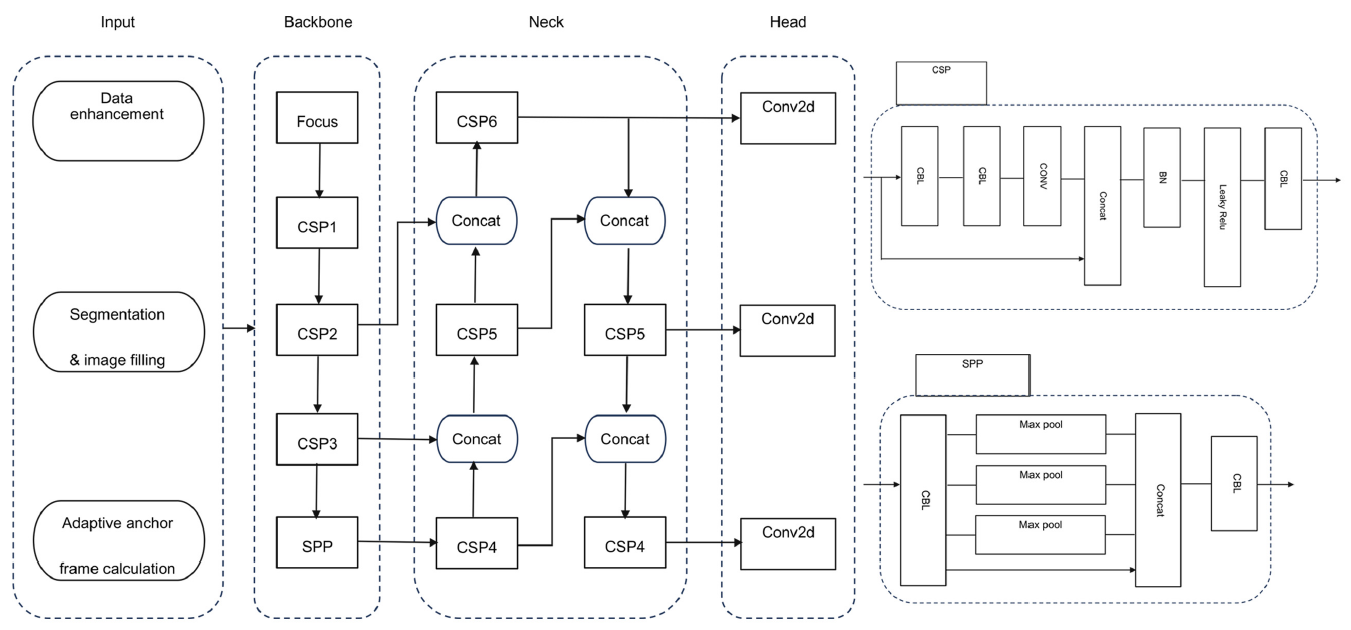
4)随机亮度策略
在训练阶段引入随机亮度策略,通过伽马变换对轨道图像和侵入者图像的亮度分别进行调整,再将铁路背景逐像素替换为擅闯者,生成合成铁路擅闯者的随机亮度输出图像,如下图所示。

(4)实验
改进的目标检测模型YOLOSEG在我们的rail-trespasser数据集上进行训练,其中6400张来自rail-trespasser数据集的图像用于训练,剩下的1600张图像用于验证和测试。初始学习率为0.001,衰减系数为0.0005,每批包含32张图像,训练轮数为500。
障碍物检测网络的训练参数如下图所示:
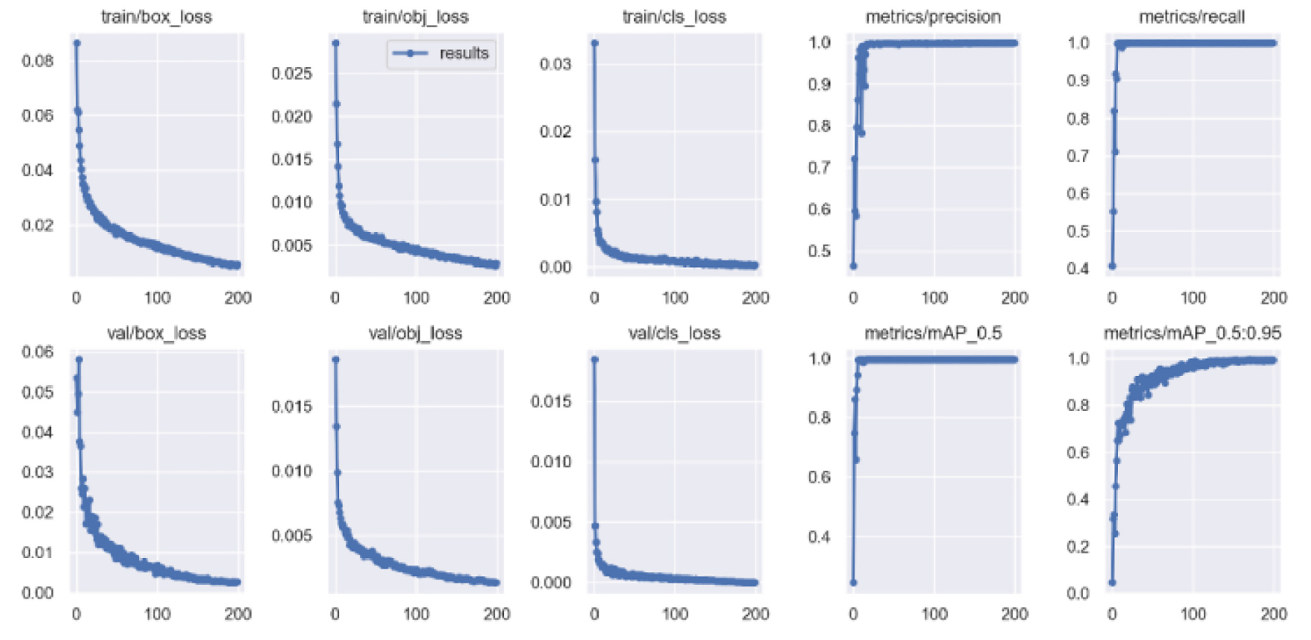
测试结果如下图所示:

未改进的YOLO会检测图像中的所有物体,而改进的YOLOSEG仅检测位于火车可能行驶的轨道区域的闯入者,如下图所示:

将训练好的YOLOSEG模型应用于真实世界的铁路越轨者图像测试,结果如下图所示:

基于生成的铁路侵入者数据集,将目前广泛使用的目标检测算法与YOLOSEG进行了比较。如下表所示:

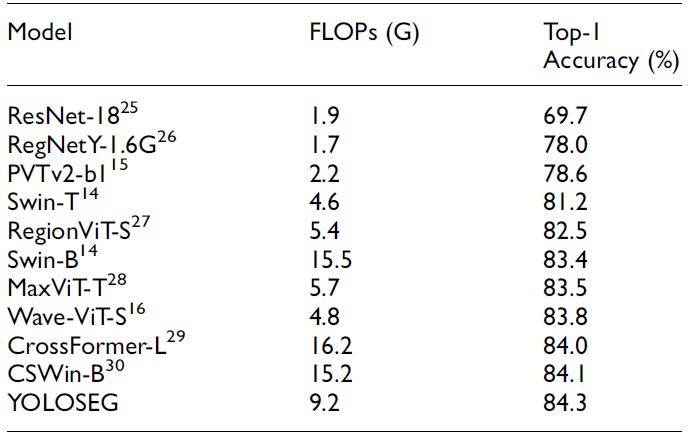
在COCO Val 2017上使用所提出方法与最先进目标检测方法之间的性能比较,如下表所示:


















 1506
1506

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









