



 Fast R-CNN是一种改进的目标检测算法,解决了R-CNN和SPPnet存在的问题,如多阶段训练、耗时和内存占用大等。它通过单级训练算法联合学习分类和空间位置调整,提高了检测精度和效率。
Fast R-CNN是一种改进的目标检测算法,解决了R-CNN和SPPnet存在的问题,如多阶段训练、耗时和内存占用大等。它通过单级训练算法联合学习分类和空间位置调整,提高了检测精度和效率。
将看过的目标检测的经典论文进行总结,方便以后查看
文章链接:http://cn.arxiv.org/pdf/1504.08083v2
代码链接:https://github.com/rbgirshick/ fast-rcnn
1. Introduction
因为目标检测需要精确的定位,所以目标检测相对于分类更复杂,主要有两个挑战:
一、必须处理许多候选对象位置(通常称为“proposal”);
二、这些候选区域只提供粗略的定位,必须加以调整才能实现精确的定位。
这篇文章的主要思路:提出了一种单级训练算法,它联合学习对目标候选进行分类并改善它们的空间位置。
1.1 R-CNN and SPPnet
R-CNN的缺点:
- 训练是多阶段进行的。首先,R-CNN用log loss在候选的目标上微调卷积神经网络。然后,用CNN得到的特征训练SVM。这些svms充当目标检测器,取代通过微调学习的Softmax分类器.在第三个训练阶段,学习边界框回归器。
- 训练过程是耗时的,并且占用内存的。对于svm和边界框回归器训练,从每个图像中的每个候选目标中提取特征并写入磁盘。对于非常深的网络(如VGG 16),这个过程需要2.5个GPU一天的时间来处理07年trainval集的5k图像。这些特性需要数百GB的存储空间。
- 目标检测过程太慢。在测试时,从每个测试图像中的每个候选目标中提取特征.使用VGG16进行检测需要47s/图像(在一个GPU上)。
SPPnet的缺点:和上面R-CNN的缺点相同。但与R-CNN不同,SPPnet中提出的微调算法不能更新空间金字塔池之前的卷积层。这种限制(固定的卷积层)限制了非常深的网络的精度。
1.2 Contributions
Fast R-CNN的几个优势:
- 比R-CNN和SPPnet更高的检测精度;
- 训练用了一个多任务的损失函数来实现一步完成;
- 训练可以更新所有网络层的参数;
- 不需要磁盘缓存特征。
2. Fast R-CNN architecture and training
下面是对Fast R-CNN的结构图以及流程图。
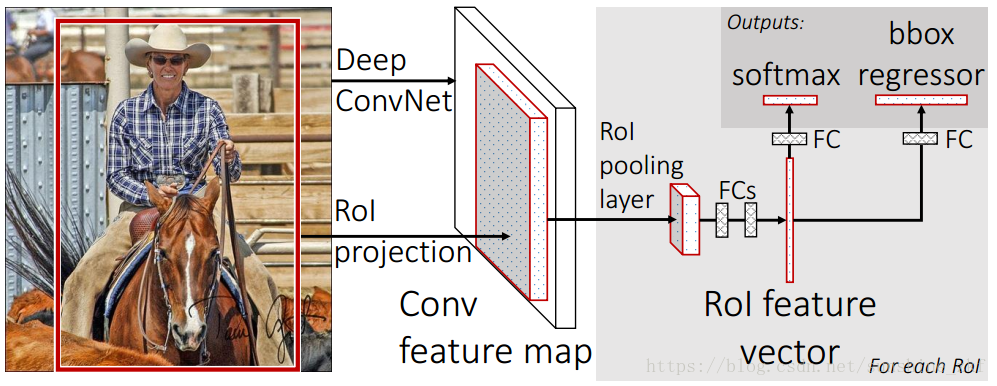
图1. Fast R-CNN架构。输入图像和多个感兴趣区域(RoI)被输入到全卷积网络中。每个RoI被池化到固定大小的特征图中,然后通过全连接层(FC)映射到特征向量。网络对于每个RoI具有两个输出向量:Softmax概率和每类检测框回归偏移量。该架构是使用多任务损失函数端到端训练的。
Fast R-CNN网络的流程:
-
任意大小的图片输入到卷积神经网络中,经过若干卷积层和池化层,得到最后的特征图;在任意大小图片上采用selective search算法提取约2k个左右的候选框;
-
根据原图中候选框到特征图的映射关系,在特征图中找到每个建议框对应的特征框【深度和特征图一致】,并在RoI池化层中将每个特征框池化到H×W【VGG-16网络是7×7】的大小;固定H×W【VGG-16网络是7×7】大小的RoI特征框经过全连接层得到固定大小的特征向量;
-
每一个RoI特征向量经由各自的全连接层【由SVD分解实现】,分别得到两个输出向量:一个是softmax的分类得分,一个是Bounding-box窗口回归;
-
利用窗口得分分别对每一类物体进行非极大值抑制剔除重叠建议框,最终得到每个类别中回归修正后的得分最高的窗口。
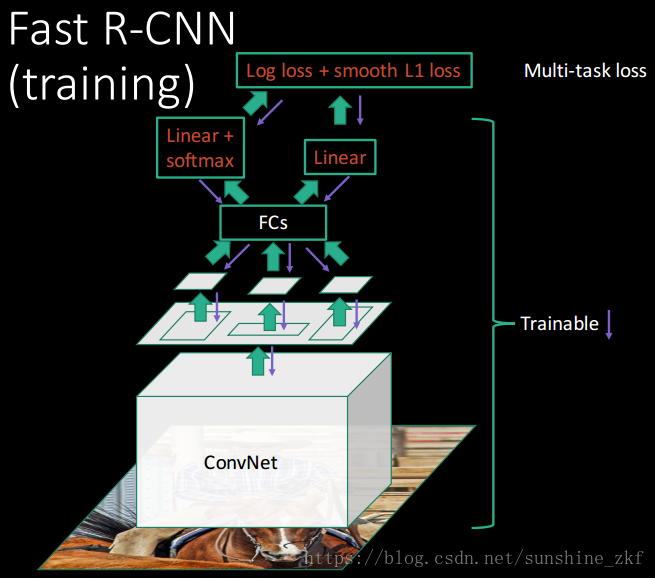
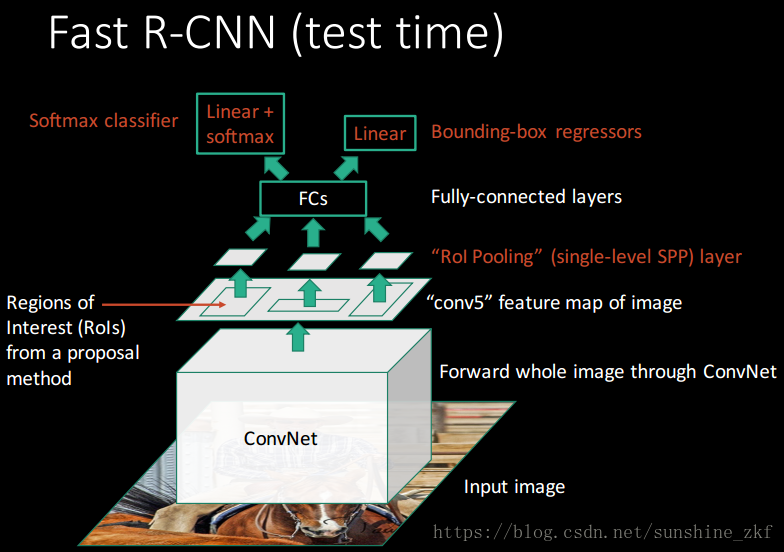
2.1 The RoI pooling layer
感兴趣区域池化层用最大池化将任意有效的感兴趣区域内的特征转换为一个固定空间为H*W(7*7)范围的一个更小的特征映射,其中H和W是层的超参数,独立于任何特定的RoI。在本文中,RoI是卷积特征图中的一个矩形窗口。 每个RoI由指定其左上角(r,c)及其高度和宽度(h,w)的四元组(r,c,h,w)定义。
RoI最大池化通过将大小为h×w的RoI窗口分割成H×W个网格,子窗口大小约为h/H×w/W,然后对每个子窗口执行最大池化,并将输出合并到相应的输出网格单元中。同标准的最大池化一样,池化操作独立应用于每个特征图通道。RoI层只是SPPnets 中使用的空间金字塔池层的特殊情况,其只有一个金字塔层。 我们使用SPPnet论文中给出的池化子窗口计算方法。
2.2 Initializing from pre-trained networks


















 1586
1586

 被折叠的 条评论
为什么被折叠?
被折叠的 条评论
为什么被折叠?
 到【灌水乐园】发言
到【灌水乐园】发言









